引言
论文《Attention is All You Need》(Vaswani等,2017)提出了Transformer架构,这一模型通过完全摒弃标准的循环神经网络(RNN)组件,彻底改变了自然语言处理(NLP)领域。相反,它利用了一种称为“注意力”的机制,让模型在生成输出时决定如何关注输入的特定部分(如句子中的单词)。在Transformer之前,基于RNN的模型(如LSTM)主导了NLP领域。这些模型一次处理一个词元,难以有效捕捉长距离依赖关系。而Transformer则通过并行化数据流,并依赖注意力机制来识别词元之间的重要关系。这一步骤带来了巨大的影响,推动了机器翻译、文本生成(如GPT)甚至计算机视觉任务等领域的巨大飞跃。
在深入Transformer模型的实现之前,强烈建议对深度学习概念有基本的了解。熟悉神经网络、embedding、激活函数和优化技术等主题,将更容易理解代码并掌握Transformer的工作原理。如果你对这些概念不熟悉,可以考虑探索深度学习框架的入门资源,以及反向传播等基础主题。

导入库
我们将使用PyTorch作为深度学习框架。PyTorch提供了构建和训练神经网络所需的所有基本工具:
import torch
import torch.nn as nn
import math这些导入包括:
- torch:PyTorch主库。
- torch.nn:包含与神经网络相关的类和函数,如nn.Linear、nn.Dropout等。
- math:用于常见的数学操作。
Transformer架构
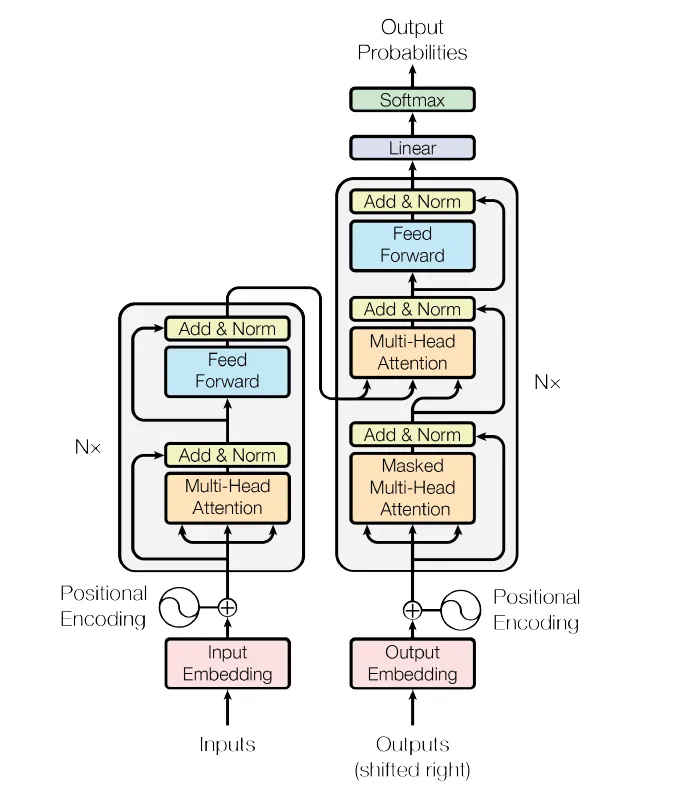
输入embedding
什么是embedding?
embedding是单词或词元的密集向量表示。与将单词表示为独热编码向量不同,embedding将每个单词映射到低维连续向量空间。这些embedding捕捉了单词之间的语义关系。例如,“男人”和“女人”的词embedding在向量空间中的距离可能比“男人”和“狗”更近。
以下是embedding层的代码:
class InputEmbedding(nn.Module):
def __init__(self, d_model: int, vocab_size: int):
super().__init__()
self.d_model = d_model
self.vocab_size = vocab_size
self.embedding = nn.Embedding(vocab_size, d_model)
def forward(self, x):
return self.embedding(x) * math.sqrt(self.d_model)解释:
- nn.Embedding:将单词索引转换为大小为d_model的密集向量。
- 缩放因子sqrt(d_model):论文中使用此方法在训练期间稳定梯度。
示例:
如果词汇表大小为6(例如,词元如[“Bye”, “Hello”等]),且d_model为512,embedding层将每个词元映射到一个512维向量。
位置编码
什么是位置编码?
Transformer并行处理输入序列,因此它们缺乏固有的顺序概念(与RNN不同,RNN是顺序处理词元的)。位置编码被添加到embedding中,以向模型提供词元在序列中的相对或绝对位置信息。
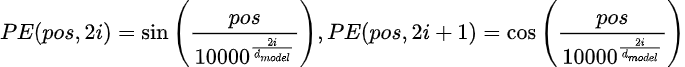
以下是位置编码的代码:
class PositionalEncoding(nn.Module):
def __init__(self, d_model: int, seq_len: int, dropout: float) -> None:
super().__init__()
self.d_model = d_model
self.seq_len = seq_len
self.dropout = nn.Dropout(dropout)
pe = torch.zeros(seq_len, d_model)
position = torch.arange(0, seq_len).unsqueeze(1).float()
div_term = torch.exp(torch.arange(0, d_model, 2).float() * (-math.log(10000.0) / d_model))
pe[:, 0::2] = torch.sin(position * div_term)
pe[:, 1::2] = torch.cos(position * div_term)
pe = pe.unsqueeze(0)
self.register_buffer('pe', pe)
def forward(self, x):
x = x + (self.pe[:, :x.shape[1], :]).requires_grad_(False)
return self.dropout(x)解释:
- 正弦函数:编码在偶数和奇数维度之间交替使用正弦和余弦函数。
- 为什么使用正弦函数?这些函数允许模型泛化到比训练时更长的序列。
- register_buffer:确保位置编码与模型一起保存,但在训练期间不更新。
我们只需要计算一次位置编码,然后为每个句子重复使用。
层归一化
什么是层归一化?
层归一化是一种通过跨特征维度归一化输入来稳定和加速训练的技术。它确保每个输入向量的均值为0,方差为1。
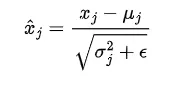
我们还引入了两个参数,gamma(乘法)和beta(加法),它们会在数据中引入波动。网络将学习调整这两个可学习参数,以在需要时引入波动。
以下是代码:
class LayerNormalization(nn.Module):
def __init__(self, eps: float = 1e-6) -> None:
super().__init__()
self.eps = eps
self.alpha = nn.Parameter(torch.ones(1))
self.bias = nn.Parameter(torch.zeros(1))
def forward(self, x):
mean = x.mean(dim=-1, keepdim=True)
std = x.std(dim=-1, keepdim=True)
return self.alpha * (x - mean) / (std + self.eps) + self.bias解释:
- alpha和bias:可学习参数,用于缩放和偏移归一化后的输出。
- eps:添加到分母中的小值,以防止除以零。
前馈块
什么是前馈块?
它是一个简单的两层神经网络,独立应用于序列中的每个位置。它帮助模型学习复杂的变换。以下是代码:
class FeedForwardBlock(nn.Module):
def __init__(self, d_model: int, d_ff: int, dropout: float) -> None:
super().__init__()
self.linear_1 = nn.Linear(d_model, d_ff)
self.dropout = nn.Dropout(dropout)
self.linear_2 = nn.Linear(d_ff, d_model)
def forward(self, x):
return self.linear_2(self.dropout(torch.relu(self.linear_1(x))))解释:
- 第一层线性层:将输入维度从d_model扩展到d_ff,即512 → 2048。
- ReLU激活:增加非线性。
- 第二层线性层:投影回d_model。
多头注意力
什么是注意力?
注意力机制允许模型在做出预测时关注输入的相关部分。它计算值(V)的加权和,其中权重由查询(Q)和键(K)之间的相似性决定。
什么是多头注意力?
与计算单一注意力分数不同,多头注意力将输入分成多个“头h”,以学习不同类型的关系。

注意力
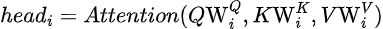
按头计算的注意力
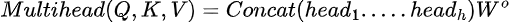
所有头的注意力
- Q(查询):代表当前单词或词元。
- K(键):代表序列中的所有单词或词元。
- V(值):代表与每个单词或词元相关的信息。
- Softmax:将相似性分数转换为概率,使其总和为1。
- 缩放因子sqrt(d_k):防止点积变得过大,从而破坏softmax函数的稳定性。
每个头计算自己的注意力,结果被拼接并投影回原始维度。以下是多头注意力块的代码:
class MultiHeadAttentionBlock(nn.Module):
def __init__(self, d_model: int, h: int, dropout: float) -> None: # h is number of heads
super().__init__()
self.d_model = d_model
self.h = h
# Check if d_model is divisible by num_heads
assert d_model % h == 0, "d_model must be divisible by num_heads"
self.d_k = d_model // h
# Define matrices W_q, W_k, W_v , W_o
self.w_q = nn.Linear(d_model, d_model) # W_q
self.w_k = nn.Linear(d_model, d_model) # W_k
self.w_v = nn.Linear(d_model, d_model) # W_v
self.w_o = nn.Linear(d_model, d_model) # W_o
self.dropout = nn.Dropout(dropout)
@staticmethod
def attention(query, key, value, d_k, mask=None, dropout=nn.Dropout):
# Compute attention scores
attention_scores = (query @ key.transpose(-2, -1)) / math.sqrt(d_k)
if mask is not None:
attention_scores.masked_fill(mask == 0, -1e9) # Mask padding tokens
attention_scores = torch.softmax(attention_scores, dim=-1)
if dropout is not None:
attention_scores = dropout(attention_scores)
return (attention_scores @ value), attention_scores
def forward(self, q, k, v, mask):
# Compute Q, K, V
query = self.w_q(q)
key = self.w_k(k)
value = self.w_v(v)
# Split into multiple heads
query = query.view(query.shape[0], query.shape[1], self.h, self.d_k).transpose(1, 2)
key = key.view(key.shape[0], key.shape[1], self.h, self.d_k).transpose(1, 2)
value = value.view(value.shape[0], value.shape[1], self.h, self.d_k).transpose(1, 2)
# Compute attention
x, self.attention_scores = MultiHeadAttentionBlock.attention(query, key, value, self.d_k, mask, self.dropout)
# Concatenate heads
x = x.transpose(1, 2).contiguous().view(x.shape[0], -1, self.h * self.d_k)
# Final linear projection
return self.w_o(x)解释:
- 线性层(W_q, W_k, W_v):这些层将输入转换为查询、键和值。
- 分割成头:输入被分割成h个头,每个头的维度较小(d_k = d_model / h)。
- 拼接:所有头的输出被拼接,并使用w_o投影回原始维度。
示例:
如果d_model=512且h=8,每个头的维度为d_k=64。输入被分割成8个头,每个头独立计算注意力。结果被拼接回一个512维向量。
残差连接和层归一化
什么是残差连接?
残差连接将层的输入添加到其输出中。这有助于防止“梯度消失”问题。以下是残差连接的代码:
class ResidualConnection(nn.Module):
def __init__(self, dropout: float) -> None:
super().__init__()
self.dropout = nn.Dropout(dropout)
self.norm = LayerNormalization()
def forward(self, x, sublayer):
return x + self.dropout(sublayer(self.norm(x)))解释:
- x:层的输入。
- sublayer:表示层的函数(如注意力或前馈块)。
- 输出是输入和子层输出的和,随后进行dropout。
1. 编码器块
编码器块结合了我们迄今为止讨论的所有组件:多头注意力、前馈块、残差连接和层归一化。以下是编码器块的代码:
class EncoderBlock(nn.Module):
def __init__(self, self_attention_block: MultiHeadAttentionBlock, feed_forward_block: FeedForwardBlock, dropout: float) -> None:
super().__init__()
self.self_attention_block = self_attention_block
self.feed_forward_block = feed_forward_block
self.residual_connections = nn.ModuleList([ResidualConnection(dropout) for _ in range(2)])
def forward(self, x, src_mask):
x = self.residual_connections[0](x, lambda x: self.self_attention_block(x, x, x, src_mask))
x = self.residual_connections[1](x, self.feed_forward_block)
return x解释:
- 自注意力:输入对自身进行注意力计算,以捕捉词元之间的关系。
- 前馈块:对每个词元应用全连接网络。
- 残差连接:将输入添加回每个子层的输出。
2. 解码器块
解码器块与编码器块类似,但包含一个额外的交叉注意力层。这使得解码器能够关注编码器的输出。以下是解码器块的代码:
class DecoderBlock(nn.Module):
def __init__(self, self_attention_block: MultiHeadAttentionBlock, cross_attention_block: MultiHeadAttentionBlock, feed_forward_block: FeedForwardBlock, dropout: float) -> None:
super().__init__()
self.self_attention_block = self_attention_block
self.cross_attention_block = cross_attention_block
self.feed_forward_block = feed_forward_block
self.residual_connections = nn.ModuleList([ResidualConnection(dropout) for _ in range(3)])
def forward(self, x, encoder_output, src_mask, tgt_mask):
x = self.residual_connections[0](x, lambda x: self.self_attention_block(x, x, x, tgt_mask))
x = self.residual_connections[1](x, lambda x: self.cross_attention_block(x, encoder_output, encoder_output, src_mask))
x = self.residual_connections[2](x, self.feed_forward_block)
return x解释:
- 自注意力:解码器对其自身输出进行注意力计算。
- 交叉注意力:解码器对编码器的输出进行注意力计算。
- 前馈块:对每个词元应用全连接网络。
3. 最终线性层
该层将解码器的输出投影到词汇表大小,将embedding为每个单词的概率。该层将包含一个线性层和一个softmax层。这里使用log_softmax以避免下溢并使此步骤在数值上更稳定。以下是最终线性层的代码:
class ProjectionLayer(nn.Module):
def __init__(self, d_model: int, vocab_size: int) -> None:
super().__init__()
self.proj = nn.Linear(d_model, vocab_size)
def forward(self, x):
return torch.log_softmax(self.proj(x), dim=-1)解释:
- 输入:解码器的输出(形状:[batch, seq_len, d_model])。
- 输出:词汇表中每个单词的对数概率(形状:[batch, seq_len, vocab_size])。
Transformer模型
Transformer将所有内容结合在一起:编码器、解码器、embedding、位置编码和投影层。以下是代码:
class Transformer(nn.Module):
def __init__(self, encoder: Encoder, decoder: Decoder, src_embed: InputEmbedding, tgt_embed: InputEmbedding, src_pos: PositionalEncoding, tgt_pos: PositionalEncoding, projection_layer: ProjectionLayer) -> None:
super().__init__()
self.encoder = encoder
self.decoder = decoder
self.src_embed = src_embed
self.tgt_embed = tgt_embed
self.src_pos = src_pos
self.tgt_pos = tgt_pos
self.projection_layer = projection_layer
def encode(self, src, src_mask):
src = self.src_embed(src)
src = self.src_pos(src)
return self.encoder(src, src_mask)
def decode(self, encoder_output, tgt, src_mask, tgt_mask):
tgt = self.tgt_embed(tgt)
tgt = self.tgt_pos(tgt)
return self.decoder(tgt, encoder_output, src_mask, tgt_mask)
def project(self, decoder_output):
return self.projection_layer(decoder_output)最终构建函数块
最后一个块是一个辅助函数,通过组合我们迄今为止看到的所有组件来构建整个Transformer模型。它允许我们指定论文中使用的超参数。以下是代码:
def build_transformer(src_vocab_size: int, tgt_vocab_size: int, src_seq_len: int, tgt_seq_len: int,
d_model: int = 512, N: int = 6, h: int = 8, dropout: float = 0.1, d_ff: int = 2048) -> Transformer:
# Create the embedding layers for source and target
src_embed = InputEmbedding(d_model, src_vocab_size)
tgt_embed = InputEmbedding(d_model, tgt_vocab_size)
# Create positional encoding layers for source and target
src_pos = PositionalEncoding(d_model, src_seq_len, dropout)
tgt_pos = PositionalEncoding(d_model, tgt_seq_len, dropout)
# Create the encoder blocks
encoder_blocks = []
for _ in range(N):
encoder_self_attention_block = MultiHeadAttentionBlock(d_model, h, dropout)
feed_forward_block = FeedForwardBlock(d_model, d_ff, dropout)
encoder_block = EncoderBlock(encoder_self_attention_block, feed_forward_block, dropout)
encoder_blocks.append(encoder_block)
# Create the decoder blocks
decoder_blocks = []
for _ in range(N):
decoder_self_attention_block = MultiHeadAttentionBlock(d_model, h, dropout)
decoder_cross_attention_block = MultiHeadAttentionBlock(d_model, h, dropout)
feed_forward_block = FeedForwardBlock(d_model, d_ff, dropout)
decoder_block = DecoderBlock(decoder_self_attention_block, decoder_cross_attention_block, feed_forward_block, dropout)
decoder_blocks.append(decoder_block)
# Create the encoder and decoder
encoder = Encoder(nn.ModuleList(encoder_blocks))
decoder = Decoder(nn.ModuleList(decoder_blocks))
# Create the projection layer
projection_layer = ProjectionLayer(d_model, tgt_vocab_size)
# Create the Transformer model
transformer = Transformer(encoder, decoder, src_embed, tgt_embed, src_pos, tgt_pos, projection_layer)
# Initialize the parameters using Xavier initialization
for p in transformer.parameters():
if p.dim() > 1:
nn.init.xavier_uniform_(p)
return transformer该函数接受以下超参数作为输入:
- src_vocab_size:源词汇表的大小(源语言中唯一词元的数量)。
- tgt_vocab_size:目标词汇表的大小(目标语言中唯一词元的数量)。
- src_seq_len:源输入的最大序列长度。
- tgt_seq_len:目标输入的最大序列长度。
- d_model:模型的维度(默认:512)。
- N:编码器和解码器块的数量(默认:6)。
- h:多头注意力机制中的注意力头数量(默认:8)。
- dropout:防止过拟合的dropout率(默认:0.1)。
- d_ff:前馈网络的维度(默认:2048)。
我们可以使用此函数创建具有所需超参数的Transformer模型。例如:
src_vocab_size = 10000
tgt_vocab_size = 10000
src_seq_len = 50
tgt_seq_len = 50
transformer = build_transformer(src_vocab_size, tgt_vocab_size, src_seq_len, tgt_seq_len)总结 — “Attention is All You Need” 核心贡献
- 并行化:RNN按顺序处理单词,而Transformer并行处理整个句子。这大大减少了训练时间。
- 多功能性:注意力机制可以适应各种任务,如翻译、文本分类、问答、计算机视觉、语音识别等。
- 为基础模型铺路:该架构为BERT、GPT和T5等大规模语言模型铺平了道路。