在当今的软件开发领域,性能优化始终是一个备受关注的核心议题。而在众多提升性能的技术手段中,MyBatis 缓存无疑占据着重要的一席之地。当我们深入探索 MyBatis 的世界时,会发现其缓存机制宛如一座隐藏的宝藏,蕴含着巨大的潜力和价值。
在接下来的篇章中,我们将一同踏上探索 MyBatis 缓存的奇妙之旅。我们将逐步揭开它神秘的面纱,深入剖析其背后的原理、结构和运作方式。通过了解它是如何巧妙地减少数据库查询次数、提升系统响应速度,我们能更好地把握这一强大工具,为我们的开发项目带来更卓越的性能表现。

一、详解一级缓存
1. 什么是一级缓存
当我们建立SqlSession时,就可以通过Mybatis进行sql查询,假如本次session查询时我们需要进行两次相同的sql查询,就需要进行进行两次的磁盘IO,为了避免这种没必要的等待,Mybatis为每一个SqlSession设置一级缓存,在同一个SqlSession中,一级缓存会将第一次查询结果缓存起来,第二次相同的查询就可以直接使用了。
2. 一级缓存使用示例
Mybatis默认是开启一级缓存的,如下所示,可以发现只要第二次使用的sql和参数一样,就会从一级缓存中获取数据。
User1 user1 = user1Mapper.select("1");
logger.info("一级缓存第一次查询:[{}]", user1);
User1 user11 = user1Mapper.select("1");
logger.info("一级缓存第二次查询:[{}]", user11);
User1 user12 = user1Mapper.select("2");
logger.info("一级缓存第三次查询,id不同:[{}]", user12);输出结果:
2022-11-27 15:51:28,313 [main] DEBUG [com.sharkchili.mapper.User1Mapper.select] - ==> Preparing: select * from user1 where id = ?
2022-11-27 15:51:28,338 [main] DEBUG [com.sharkchili.mapper.User1Mapper.select] - ==> Parameters: 1(String)
2022-11-27 15:51:28,539 [main] DEBUG [com.sharkchili.mapper.User1Mapper.select] - <== Total: 1
2022-11-27 15:51:28,541 [main] DEBUG [com.sharkchili.mapper.User1Mapper.select] - ==> Preparing: select * from user1 where id = ?
2022-11-27 15:51:28,541 [main] DEBUG [com.sharkchili.mapper.User1Mapper.select] - ==> Parameters: 2(String)
[main] INFO com.sharkchili.mapper.MyBatisTest - 一级缓存第一次查询:[User1{id='1', name='小明', user2=null}]
[main] INFO com.sharkchili.mapper.MyBatisTest - 一级缓存第二次查询:[User1{id='1', name='小明', user2=null}]
2022-11-27 15:51:28,667 [main] DEBUG [com.sharkchili.mapper.User1Mapper.select] - <== Total: 1
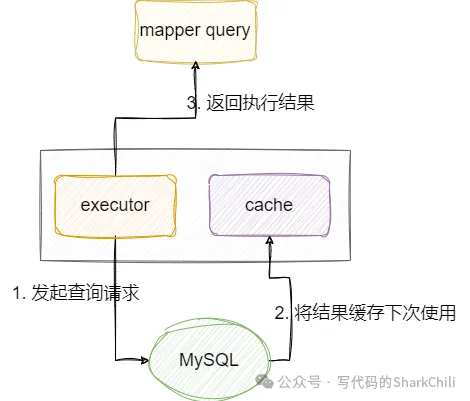
[main] INFO com.sharkchili.mapper.MyBatisTest - 一级缓存第三次查询,id不同:[User1{id='2', name='小王', user2=null}] 3. 一级缓存的执行过程
当然我们也得有一个查询代码,查询代码如下所示:
User1 user1 = user1Mapper.select("1");
logger.info("一级缓存第一次查询:[{}]", user1);本质上mapper代理对象进行查询操作时底层的BaseExecutor会调用queryFromDatabase获取查询结果,然后将查询结果存到缓存中:
private <E> List<E> queryFromDatabase(MappedStatement ms, Object parameter, RowBounds rowBounds, ResultHandler resultHandler, CacheKey key, BoundSql boundSql) throws SQLException {
this.localCache.putObject(key, ExecutionPlaceholder.EXECUTION_PLACEHOLDER);
List list;
try {
//执行并获取查询结果
list = this.doQuery(ms, parameter, rowBounds, resultHandler, boundSql);
} finally {
this.localCache.removeObject(key);
}
//基于本次查询用到的MappedStatement , 参数, rowBounds, sql作为key将结果缓存
this.localCache.putObject(key, list);
if (ms.getStatementType() == StatementType.CALLABLE) {
this.localOutputParameterCache.putObject(key, parameter);
}
return list;
}总结一下流程就如下图所示:
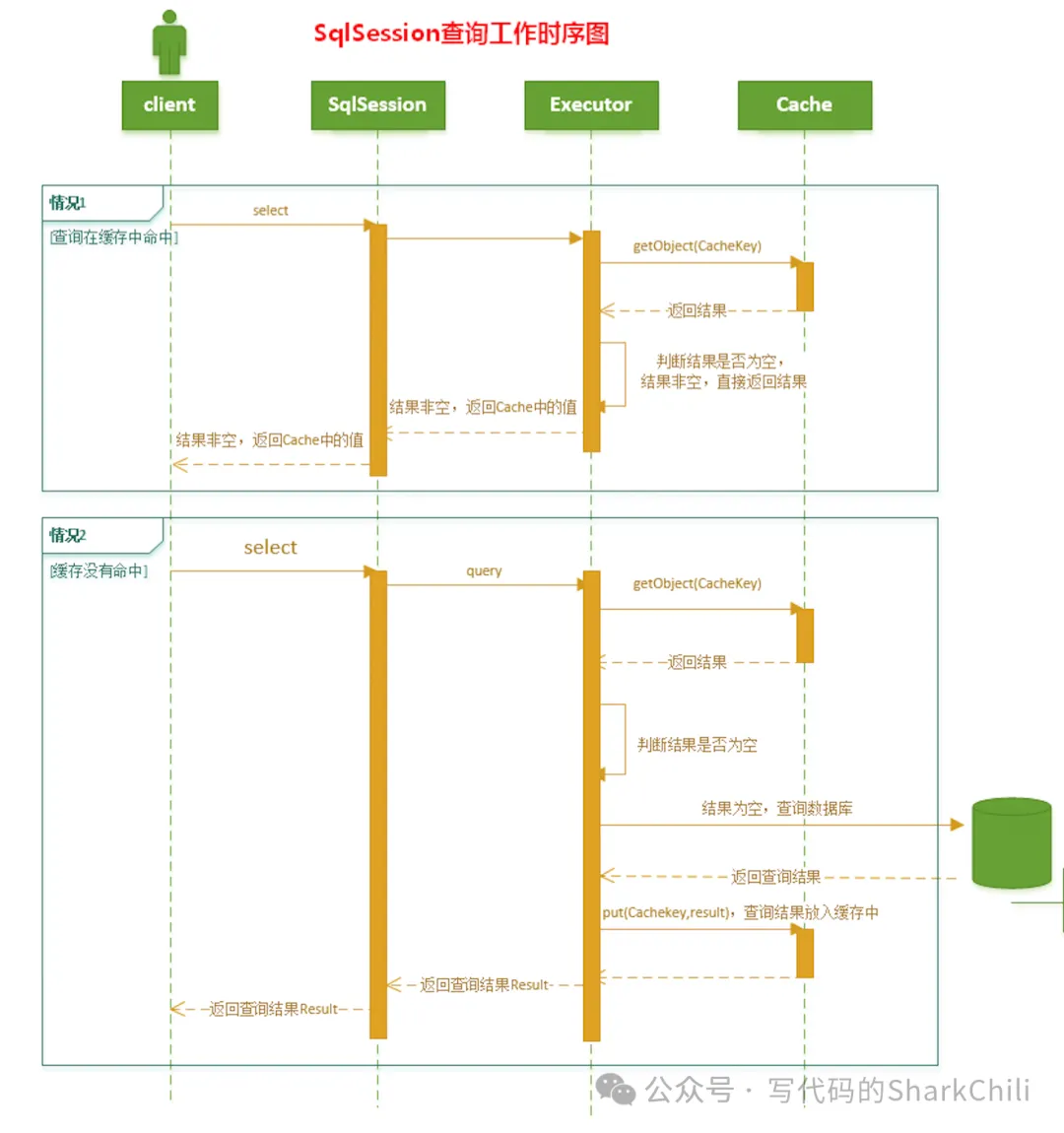
4. 一级缓存的生命周期
- 当SqlSession调用了close之后,会直接释放PerpetualCache对象,缓存自然不能使用了。
- 进行update、delete、insert等操作,缓存就会被清空,但是缓存对象还能用。
- 调用clearCache同理,缓存被清空,但是对象还能用。
二、详解二级缓存
1. 什么是二级缓存
二级缓存是mybatis为了解决跨session缓存数据所增加的一层面向namespace级别的缓存方案,即以mapper文件为单位划分的缓存空间,通过开启二级缓存,程序执行查询时会优先从全局共享的的二级缓存开始查询,如果全局的二级缓存没有数据,再通过一级缓存查询,如果有则返回并返回,如果没有则执行SQL查询依次缓存到一级缓存、二级缓存中:
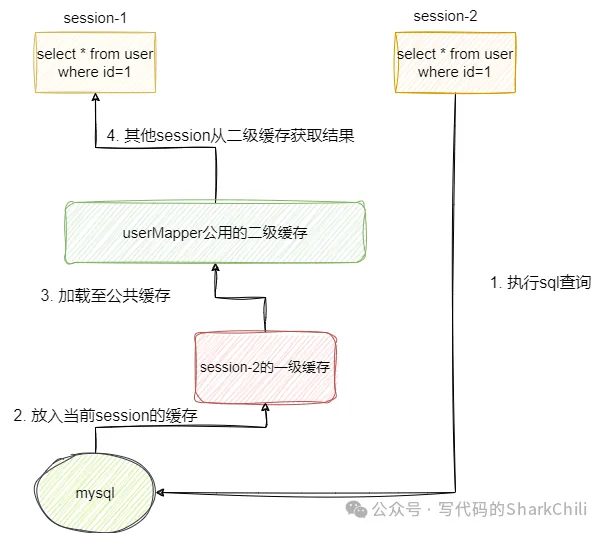
2. 二级缓存使用示例
为了讨论二级缓存,我们不妨展示一个简单的二级缓存配置示例,首先Mybatis配置开启二级缓存,其实这个可以不用配置,默认的情况下是true:
<settings>
<!--开启二级缓存-->
<setting name="cacheEnabled" value="true"/>
</settings>对应的Mapper文件下添加下面这段配置:
<cache/>然后我们给出对的测试代码:
UserMapper userMapper = SpringUtil.getBean(UserMapper.class);
User user = new User();
user.setId(1L);
//第一次查询
User u = userMapper.selectByUserId(user);
log.info("user:{}", JSONUtil.toJsonStr(u));
//第二次查询
User u2 = userMapper.selectByUserId(user);
log.info("user:{}", JSONUtil.toJsonStr(u2));可以看到使用同样的会话,第二次查询不会查询SQL而是直接从二级缓存获取数据:
2024-12-13 12:13:00.458 INFO 17996 --- [ main] com.zaxxer.hikari.HikariDataSource : HikariPool-1 - Start completed.
2024-12-13 12:13:00.464 DEBUG 17996 --- [ main] c.s.mapper.UserMapper.selectByUserId : ==> Preparing: select u.id id, u.name name , m.total total from user u inner join money m on u.id = m.u_id where u.id = 1
2024-12-13 12:13:00.482 DEBUG 17996 --- [ main] c.s.mapper.UserMapper.selectByUserId : ==> Parameters:
2024-12-13 12:13:00.498 DEBUG 17996 --- [ main] c.s.mapper.UserMapper.selectByUserId : <== Total: 1
2024-12-13 12:13:00.549 INFO 17996 --- [ main] com.sharkChili.WebApplication : user:{"id":1,"name":"xiaoming","total":50}
2024-12-13 12:13:00.550 DEBUG 17996 --- [ main] com.sharkChili.mapper.UserMapper : Cache Hit Ratio [com.sharkChili.mapper.UserMapper]: 0.5
2024-12-13 12:13:00.550 INFO 17996 --- [ main] com.sharkChili.WebApplication : user:{"id":1,"name":"xiaoming","total":50}3. 二级缓存的工作模式
在开启二级缓存配置后,框架会首先去CachingExecutor看看是否有缓存数据,若没有则会从一级缓存查询,实在找不到就通过BaseExecutor查询并处理完缓存起来。
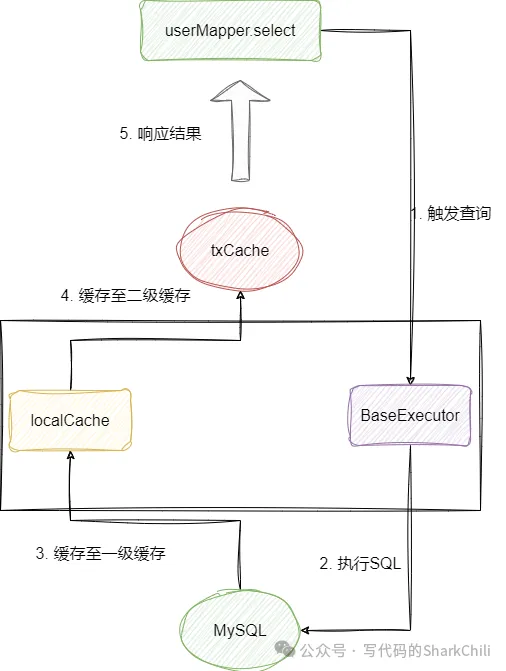
注意这里CachingExecutor用到了装饰者模式,将Executor 组合进来,所以CachingExecutor会先调用(List)this.tcm.getObject(cache, key);看看缓存中是否有数据,若没有在进行进一步查询并缓存的操作。
//将基础执行器作为被装饰的成员属性组合进来
private final Executor delegate;
public <E> List<E> query(MappedStatement ms, Object parameterObject, RowBounds rowBounds, ResultHandler resultHandler, CacheKey key, BoundSql boundSql) throws SQLException {
Cache cache = ms.getCache();
if (cache != null) {
this.flushCacheIfRequired(ms);
//开启二级缓存则执行该逻辑
if (ms.isUseCache() && resultHandler == null) {
this.ensureNoOutParams(ms, boundSql);
//先去缓存查询
List<E> list = (List)this.tcm.getObject(cache, key);
if (list == null) {
// 若为空则调用BaseExecutor 进行数据获取
list = this.delegate.query(ms, parameterObject, rowBounds, resultHandler, key, boundSql);
//将数据存到二级缓存中
this.tcm.putObject(cache, key, list);
}
return list;
}
}
//调用BaseExecutor 获取查询结果并缓存
return this.delegate.query(ms, parameterObject, rowBounds, resultHandler, key, boundSql);
}4. 二级缓存怎么作用域
二级缓存怎么作用域有两种:
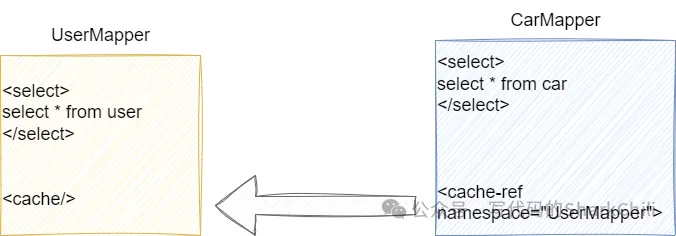
- 自定义划分,我们在每个Mapper.xml中添加 <cache/>使得每一个mapper都有一个全局的独立缓存空间:

- 假如我们希望多个mapper共享一个空间的话,需要被分享的mapper使用<cache/>,而其他mapper则用<cache-ref namespace="">指向这个空间即可。
5. 使用二级缓存要具备的几个条件
总的来说是三个条件:
- 全局配置开启二级缓存:<setting name="cacheEnabled" value="true"/>,默认是true的。
- mapper.xml标签配置了 <cache/>或者 <cache-ref/>
- select语句配置useCache=true
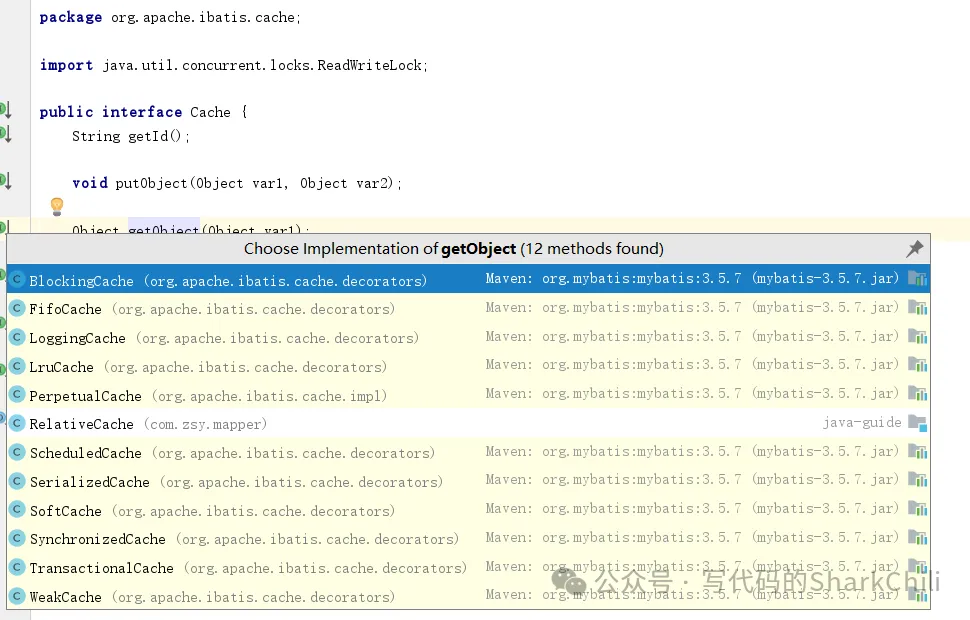
6. 二级缓存实现的选择有哪些和默认项
有三种吧:
- 框架自身提供了很多缓存方案,这些缓存还提供了不同的回收策略:例如LRU、FIFO等。
- 用户继承接口org.apache.ibatis.cache.Cache自行实现一个缓存。
- 通过第三方缓存工具集成。
对于Mybatis的二级缓存默认缓存算法,如下图,可以看到框架自身基于装饰者模式实现了很多缓存工具,并且每个缓存容量都有限制,不同的缓存工具内存回收策略是不同的:例如LruCache即最近最少使用算法,内存容量满了就回收到现在为止最不常用的。而FifoCache同理,内存满了之后回收最先被缓存的数据,ScheduledCache则是定时清理缓存了。
7. 二级缓存关联刷新问题
我们直接从一个比较实际的场景出发,首先我们有一张user表,里面有一条id为1的用户数据,name是xiaoming,然后有一张关联表money,它记录xiaoming的钱包金额为50,对应数据信息如下:
-- SELECT * FROM `user` u ;
id|name |
--+--------+
1|xiaoming|
-- SELECT * FROM money m ;
id|u_id|total|
--+----+-----+
1| 1| 10|然后我们在userMapper中写了这样一条关联查询的SQL并开启二级缓存:
<select id="selectByUserId" resultType="com.sharkChili.domain.User">
select u.id id, u.name name , m.total total
from user u
inner join money m on u.id = m.u_id
where u.id = #{id}
</select>然后我们执行下面这段操作:
- 通过关联查询获取用户1的姓名和关联表的金额信息。
- 通过moneyMapper更新用户1对应余额。
- 通过二级缓再次查询。
那么问题来了,第二次查询的金额会是更新后的10吗?
UserMapper userMapper = SpringUtil.getBean(UserMapper.class);
User user = new User();
user.setId(1L);
//第一次查询
User u = userMapper.selectByUserId(user);
log.info("user:{}", JSONUtil.toJsonStr(u));
//更新用户1对应的余额信息
MoneyMapper moneyMapper = SpringUtil.getBean(MoneyMapper.class);
Money money = new Money();
money.setId(1L);
money.setTotal(10L);
moneyMapper.updateByPrimaryKeySelective(money);
//第二次查询
User u2 = userMapper.selectByUserId(user);
log.info("user:{}", JSONUtil.toJsonStr(u2));答案是还是走了脏缓存:
2024-12-13 12:22:09.286 DEBUG 9056 --- [ main] c.s.mapper.UserMapper.selectByUserId : ==> Preparing: select u.id id, u.name name , m.total total from user u inner join money m on u.id = m.u_id where u.id = ?
2024-12-13 12:22:09.307 DEBUG 9056 --- [ main] c.s.mapper.UserMapper.selectByUserId : ==> Parameters: 1(Long)
2024-12-13 12:22:09.325 DEBUG 9056 --- [ main] c.s.mapper.UserMapper.selectByUserId : <== Total: 1
2024-12-13 12:22:09.379 INFO 9056 --- [ main] com.sharkChili.WebApplication : user:{"id":1,"name":"xiaoming","total":50}
2024-12-13 12:22:09.394 DEBUG 9056 --- [ main] c.s.m.M.updateByPrimaryKeySelective : ==> Preparing: update money SET total = ? where id = ?
2024-12-13 12:22:09.394 DEBUG 9056 --- [ main] c.s.m.M.updateByPrimaryKeySelective : ==> Parameters: 10(Long), 1(Long)
2024-12-13 12:22:09.402 DEBUG 9056 --- [ main] c.s.m.M.updateByPrimaryKeySelective : <== Updates: 1
2024-12-13 12:22:09.403 DEBUG 9056 --- [ main] com.sharkChili.mapper.UserMapper : Cache Hit Ratio [com.sharkChili.mapper.UserMapper]: 0.5
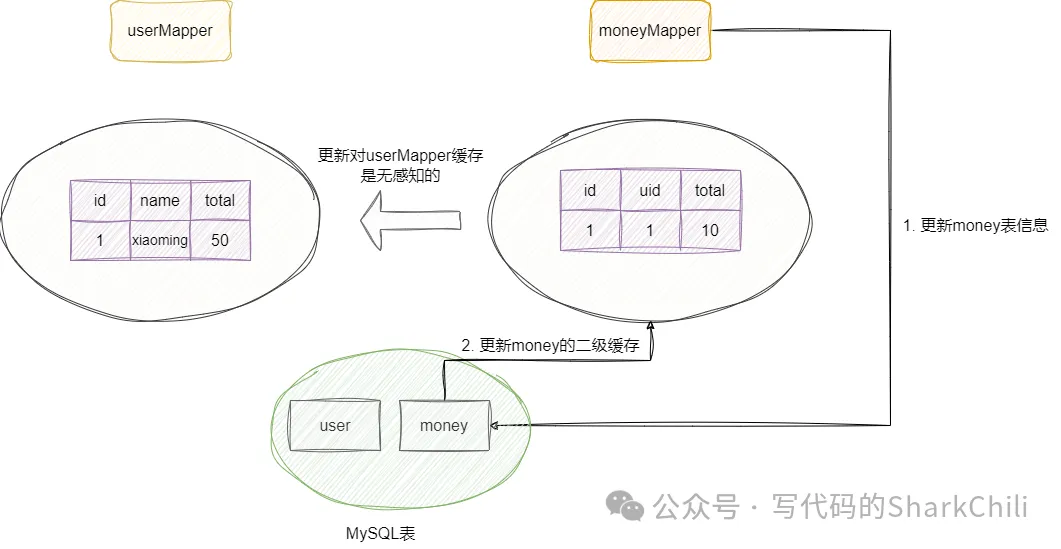
2024-12-13 12:22:09.403 INFO 9056 --- [ main] com.sharkChili.WebApplication : user:{"id":1,"name":"xiaoming","total":50}原因也很简单,二级缓存是以namespace为区域划分,这意味着userMapper缓存的数据不会因为moneyMapper的改变而触发更新,这意味着如果涉及关联查询的缓存数据可能会因为关联表的更新无法感知而出现脏缓存:
解决方案也很简单,我们只要确保缓存更新被关联表时,及时刷新响应缓存即可,具体可以参考这篇文章
MyBatis 二级缓存 关联刷新实现:https://blog.csdn.net/qq_37217713/article/details/123288123
8. 二级缓存的配置参数
主要参数有这么四个:
- 缓存回收策略(eviction):这个参数有这么4个LRU最近最少回收算法这种是默认的算法、FIFO先进先出算法、SOFT算法(基于垃圾回收器算法和软引用回收的对象)、WEAK算法即基于垃圾回收器算法和弱引用规则回收对象。
- 刷新间隔(flushInterval):单位毫秒。
- 容量(size):引用数目,正整数。
- 是否只读(readOnly):如果只读则直接返回缓存实例,性能上会相对有些优势。若不为只读则会通过序列化获取对象的拷贝,性能就相对差一些。
配置范例如下所示:
<cache eviction="FIFO"
flushInterval="60000"
size="512"
readOnly="true"/>9. 二级缓存的失效场景
有两种情况一种是第一次查询的sqlsession没有提交或者关闭:
User1 user1 = user1Mapper.select("1");
logger.info("二级缓存第一次查询:[{}]", user1);
SqlSession sqlSession2 = sqlSessionFactory.openSession();
User1Mapper user1Mapper1 = sqlSession2.getMapper(User1Mapper.class);
User1 user13 = user1Mapper1.select("1");
logger.info("二级缓存第二次查询:[{}]", user13);输出结果:
2022-11-29 01:05:43,339 [main] DEBUG [com.sharkchili.mapper.User1Mapper.select] - ==> Preparing: select * from user1 where id = ?
2022-11-29 01:05:43,363 [main] DEBUG [com.sharkchili.mapper.User1Mapper.select] - ==> Parameters: 1(String)
2022-11-29 01:05:43,502 [main] DEBUG [com.sharkchili.mapper.User1Mapper.select] - <== Total: 1
2022-11-29 01:05:43,506 [main] DEBUG [com.sharkchili.mapper.User1Mapper] - Cache Hit Ratio [com.sharkchili.mapper.User1Mapper]: 0.0
2022-11-29 01:05:43,506 [main] DEBUG [org.apache.ibatis.transaction.jdbc.JdbcTransaction] - Opening JDBC Connection
[main] INFO com.sharkchili.mapper.MyBatisTest - 二级缓存第一次查询:[User1{id='1', name='小明', user2=null}]
2022-11-29 01:05:44,234 [main] DEBUG [org.apache.ibatis.datasource.pooled.PooledDataSource] - Created connection 550668305.
2022-11-29 01:05:44,234 [main] DEBUG [org.apache.ibatis.transaction.jdbc.JdbcTransaction] - Setting autocommit to false on JDBC Connection [com.mysql.cj.jdbc.ConnectionImpl@20d28811]
2022-11-29 01:05:44,351 [main] DEBUG [com.sharkchili.mapper.User1Mapper.select] - ==> Preparing: select * from user1 where id = ?
2022-11-29 01:05:44,351 [main] DEBUG [com.sharkchili.mapper.User1Mapper.select] - ==> Parameters: 1(String)
2022-11-29 01:05:44,465 [main] DEBUG [com.sharkchili.mapper.User1Mapper.select] - <== Total: 1
[main] INFO com.sharkchili.mapper.MyBatisTest - 二级缓存第二次查询:[User1{id='1', name='小明', user2=null}]第二种则是常规更新操作:
2022-11-29 01:07:22,302 [main] DEBUG [com.sharkchili.mapper.User1Mapper.select] - ==> Preparing: select * from user1 where id = ?
2022-11-29 01:07:22,326 [main] DEBUG [com.sharkchili.mapper.User1Mapper.select] - ==> Parameters: 1(String)
2022-11-29 01:07:22,456 [main] DEBUG [com.sharkchili.mapper.User1Mapper.select] - <== Total: 1
[main] INFO com.sharkchili.mapper.MyBatisTest - 二级缓存第一次查询:[User1{id='1', name='小明', user2=null}]
2022-11-29 01:07:22,479 [main] DEBUG [com.sharkchili.mapper.User1Mapper.updatebySet] - ==> Preparing: update user1 SET id=?, name=? where id=?
2022-11-29 01:07:22,479 [main] DEBUG [com.sharkchili.mapper.User1Mapper.updatebySet] - ==> Parameters: 1(String), aa(String), 1(String)
2022-11-29 01:07:22,713 [main] DEBUG [com.sharkchili.mapper.User1Mapper.updatebySet] - <== Updates: 1
2022-11-29 01:07:22,714 [main] DEBUG [org.apache.ibatis.transaction.jdbc.JdbcTransaction] - Rolling back JDBC Connection [com.mysql.cj.jdbc.ConnectionImpl@f8c1ddd]
2022-11-29 01:07:22,833 [main] DEBUG [org.apache.ibatis.transaction.jdbc.JdbcTransaction] - Resetting autocommit to true on JDBC Connection [com.mysql.cj.jdbc.ConnectionImpl@f8c1ddd]
2022-11-29 01:07:22,949 [main] DEBUG [org.apache.ibatis.transaction.jdbc.JdbcTransaction] - Closing JDBC Connection [com.mysql.cj.jdbc.ConnectionImpl@f8c1ddd]
2022-11-29 01:07:22,949 [main] DEBUG [org.apache.ibatis.datasource.pooled.PooledDataSource] - Returned connection 260840925 to pool.
2022-11-29 01:07:22,949 [main] DEBUG [com.sharkchili.mapper.User1Mapper] - Cache Hit Ratio [com.sharkchili.mapper.User1Mapper]: 0.0
2022-11-29 01:07:22,949 [main] DEBUG [org.apache.ibatis.transaction.jdbc.JdbcTransaction] - Opening JDBC Connection
2022-11-29 01:07:22,949 [main] DEBUG [org.apache.ibatis.datasource.pooled.PooledDataSource] - Checked out connection 260840925 from pool.
2022-11-29 01:07:22,949 [main] DEBUG [org.apache.ibatis.transaction.jdbc.JdbcTransaction] - Setting autocommit to false on JDBC Connection [com.mysql.cj.jdbc.ConnectionImpl@f8c1ddd]
2022-11-29 01:07:23,065 [main] DEBUG [com.sharkchili.mapper.User1Mapper.select] - ==> Preparing: select * from user1 where id = ?
2022-11-29 01:07:23,065 [main] DEBUG [com.sharkchili.mapper.User1Mapper.select] - ==> Parameters: 1(String)
[main] INFO com.sharkchili.mapper.MyBatisTest - 二级缓存第二次查询:[User1{id='1', name='小明', user2=null}]
2022-11-29 01:07:23,184 [main] DEBUG [com.sharkchili.mapper.User1Mapper.select] - <== Total: 1要想真正用上二级缓存,需要像这样及时提交或者关闭其他session:
User1 user1 = user1Mapper.select("1");
logger.info("二级缓存第一次查询:[{}]", user1);
if (sqlSession != null) {
sqlSession.close();
}
SqlSession sqlSession2 = sqlSessionFactory.openSession();
User1Mapper user1Mapper1 = sqlSession2.getMapper(User1Mapper.class);
User1 user13 = user1Mapper1.select("1");
logger.info("二级缓存第二次查询:[{}]", user13);
if (sqlSession2 != null) {
sqlSession2.close();
}10. Mybatis一级缓存和二级缓存的区别
一级缓存默认开启,作用域session,当session调用close或者flush时就会被清空,缓存也是PerpetualCache 一种基于HashMap实现的缓存。 而二级缓存作用于mapper(namespace),也是基于缓存也是PerpetualCache ,默认不开启,需要缓存的属性类必须实现序列化接口即继承Serializable,而且二级缓存可以自定义缓存存储源。