














译者 | 朱先忠
审校 | 重楼
引言
想象一下,你正在手术过程中控制着一台机械臂。此机械臂的离散动作可能有:
- 向上移动
- 向下移动
- 抓取
或
- 释放
这些都是明确、直接的命令,在简单情况下是易于执行的。但是,如果执行精细的动作,例如:
- 将手臂移动0.5毫米以避免损伤组织
- 施加3N的力以压缩组织
或
- 旋转手腕15°以调整切口角度
该怎么办呢?
在这些情况下,你需要的不仅仅是选择一个动作——你必须决定需要多少动作。这是连续动作空间的世界,也是深度确定性策略梯度(DDPG)算法大放异彩的地方!
像深度Q网络(DQN)这样的传统方法在离散动作方面效果很好,但在连续动作方面却举步维艰。另一方面,确定性策略梯度(DPG)算法解决了这个问题,但面临着探索性差和不稳定的挑战。DDPG算法最早是在TP.Lillicrap等人的论文中提出的,它结合了DPG算法和DQN算法的优势,以提高连续动作空间环境中的稳定性和性能。
在本文中,我们将讨论DDPG算法背后的理论和架构,研究它在Python上的实现,评估其性能(通过在MountainCarContinuous游戏上进行测试),并简要讨论如何在生物工程领域使用DDPG算法。
DDPG算法架构
与评估每个可能的“状态-动作”对以找到最佳动作(由于组合无限,在连续空间中不可能)的DQN算法不同,DPG算法使用的是“演员-评论家(Actor-Critic)”架构。演员学习一种将状态直接映射到动作的策略,避免详尽的搜索并专注于学习每个状态的最佳动作。
但是,DPG算法面临两个主要挑战:
- 它是一种确定性算法,限制了对动作空间的探索。
- 由于学习过程不稳定,它无法有效地使用神经网络。
DDPG算法通过Ornstein-Uhlenbeck过程引入探索噪声,并使用批量归一化和DQN技术(如重放缓冲区和目标网络)稳定训练,从而改进了DPG算法。
借助这些增强功能,DDPG算法非常适合在连续动作空间中训练AI代理,例如在生物工程应用中控制机器人系统。
接下来,让我们深入探索DDPG模型的关键组成!
演员-评论家(Actor-Critic)框架
- 演员(策略网络):根据代理所处的状态告诉代理要采取哪种操作。网络的参数(即权重)用θμ表示。
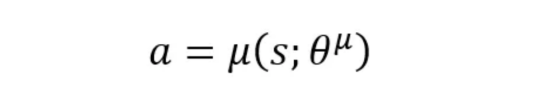
【提示】将演员网络视为决策者:它将当前状态映射到单个动作。
- 评论家(Q值网络):通过估计该状态-动作对的Q值来评估演员采取的行动有多好。
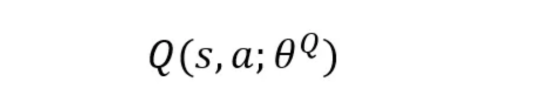
提示!将CriticNetwork视为评估者,它为每个动作分配一个质量分数,并帮助改进演员的策略,以确保它确实在每个给定状态下生成最佳动作。
注意!评论家将使用估计的Q值做两件事:
1. 改进演员的策略(演员策略更新)。
演员的目标是调整其参数(θμ),以便输出最大化评论家的Q值的动作。
为此,演员需要了解所选动作a如何影响评论家的Q值,以及其内部参数如何影响其策略,这通过此策略梯度方程完成(它是从小批量计算出的所有梯度的平均值):
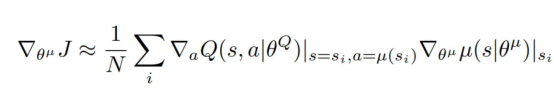
2. 通过最小化下面的损失函数来改进其自己的网络(评论家Q值网络更新)。
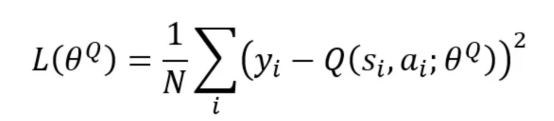
其中,N是在小批量中采样的经验数,y_i是按如下方式计算的目标Q值。
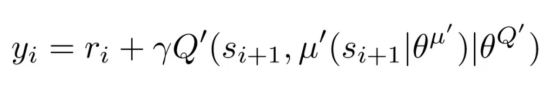
重放缓冲区
当代理探索环境时,过去的经验(状态、动作、奖励、下一个状态)会作为元组(s,a,r,s′)存储在重放缓冲区中。在训练期间,会随机抽取由其中一些经验组成的小批量来训练代理。
问题!重放缓冲区实际上如何减少不稳定性?
通过随机抽取经验,重放缓冲区打破了连续样本之间的相关性,减少了偏差并带来了更稳定的训练。
目标网络
目标网络是演员和评论家的缓慢更新副本。它们提供稳定的Q值目标,防止快速变化并确保平稳、一致的更新。
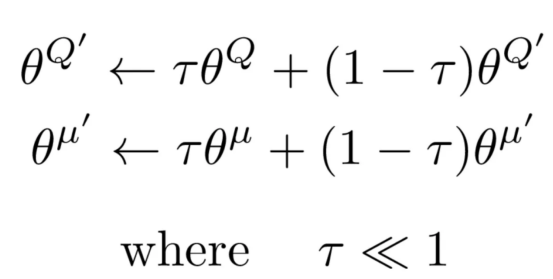
【问题】目标网络实际上如何减少不稳定性?
如果没有评论家目标网络,则目标Q值直接从评论家Q值网络计算,该网络会不断更新。这会导致目标Q值在每一步都发生变化,从而产生“移动目标”问题。因此,评论家最终会追逐不断变化的目标,导致训练不稳定。
此外,由于演员依赖于评论家的反馈,因此一个网络中的错误会放大另一个网络中的错误,从而形成相互依赖的不稳定循环。
通过引入使用软更新规则逐步更新的目标网络,我们确保目标Q值保持更一致,从而减少突然变化并提高学习稳定性。
批量归一化
批量归一化将输入归一化到神经网络的每一层,确保平均值为零且方差为1个单位。
【问题】批量归一化实际上如何减少不稳定性?
从重放缓冲区中提取的样本可能具有与实时数据不同的分布,从而导致网络更新期间不稳定。
批量归一化确保输入的一致缩放,以防止由输入分布变化引起的不稳定更新。
探索噪声
由于演员的策略是确定性的,因此在训练期间将探索噪声添加到动作中,以鼓励代理探索尽可能多的动作空间。
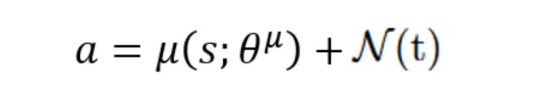
在DDPG论文中,作者使用Ornstein-Uhlenbeck过程生成时间相关噪声,以模拟现实世界的系统动态。
DDPG算法伪代码:分步分解

此伪代码取自http://arxiv.org/abs/1509.02971(参见“参考文献1”)。
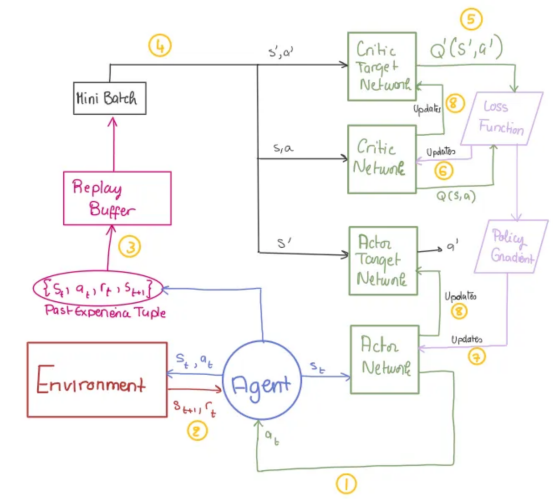
- 定义演员和评论家网络:
- 定义重放缓冲区
实现ReplayBuffer类来存储和采样上一节中讨论的转换元组(s,a,r,s’),以实现小批量离策略学习。
- 定义OU噪声类
添加OUNoise类来生成探索噪声,帮助代理更有效地探索动作空间。
- 定义DDPG代理
定义了一个DDPG类,它负责封装代理的行为:
初始化:创建演员和评论家网络,以及它们的目标对应方和重放缓冲区。
动作选择:select_action方法根据当前策略选择动作。
训练:训练方法定义了如何使用重放缓冲区中的经验来更新网络。
注意:由于本文介绍了使用目标网络和批量归一化来提高稳定性,因此我设计了训练方法,允许我们打开或关闭这些方法。这让我们可以比较代理在使用和不使用它们的情况下的性能。请参阅下面的代码以了解详细的实现。
- 训练DDPG代理
将所有定义的类和方法整合在一起,我们就可以训练DDPG代理。我的train_dppg函数遵循伪代码和DDPG模型图结构。
提示:为了让你更容易理解,我已将每个代码部分标记为伪代码和图表中相应的步骤编号。希望对你有所帮助!
性能和结果:DDPG算法有效性评估
至此,我们已经在MountainCarContinuous-v0环境中测试了DDPG算法在连续动作空间中的有效性。在该环境中,代理学会了如何获得动力以将汽车开上陡峭的山坡。结果表明,与其他配置相比,使用目标网络和批量归一化可以实现更快的收敛、更高的奖励和更稳定的学习。
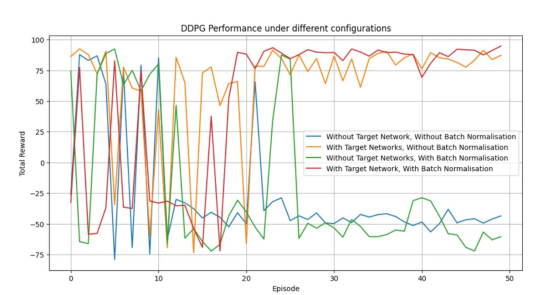
作者本人生成的图表

作者本人生成的GIF动画
注意:你可以通过运行从我的GitHub代码仓库下载的代码并根据需要更改环境名称,然后在你选择的任何环境中自行实现此功能!
生物工程领域的DDPG算法:高精度和适应性
通过本文的介绍,我们已经看到DDPG是一种强大的算法,可用于在具有连续动作空间的环境中训练代理。通过结合DPG算法和DQN算法的技术,DDPG算法可以提高探索、稳定性和性能——这正是机器人手术和生物工程应用的关键因素。
想象一下,像达芬奇系统(da Vinci system)这样的机器人外科医生使用DDPG实时控制精细动作,确保精确调整而不会出现任何错误。借助DDPG算法,机器人可以以毫米为单位调整手臂的位置,在缝合时施加精确的力,甚至可以轻微旋转手腕以获得最佳切口。这种实时精度可以改变手术结果,缩短恢复时间,并最大限度地减少人为错误。
但DDPG算法的潜力不仅限于医学手术领域。它已经推动了生物工程的发展,使机器人假肢和辅助设备能够复制人类肢体的自然运动(有兴趣的读者可以查看这篇有趣的文章:https://www.tandfonline.com/doi/abs/10.1080/00207179.2023.2201644)。
现在,我们已经介绍了DDPG算法背后的理论,是时候由你来探索它的实际应用了。你可以从简单的例子开始,逐渐深入到更复杂的实战场景!
参考文献
- Lillicrap TP、Hunt JJ、Pritzel A、Heess N、Erez T、Tassa Y等人。使用深度强化学习的连续控制(Continuous control with deep reinforcement learning [Internet])。arXiv;2019年。出处:http://arxiv.org/abs/1509.02971
译者介绍
朱先忠,51CTO社区编辑,51CTO专家博客、讲师,潍坊一所高校计算机教师,自由编程界老兵一枚。
原文标题:Understanding DDPG: The Algorithm That Solves Continuous Action Control Challenges,作者:Sirine Bhouri


















