













论文信息
- 论文题目:LiON: Learning Point-wise Abstaining Penalty for LiDAR Outlier DetectioN Using Diverse Synthetic Data
- 论文发表单位:清华大学, 厦门大学,滴滴出行, 香港中文大学-深圳
- 论文地址:https://arxiv.org/abs/2309.10230
- 项目仓库:https://github.com/Daniellli/LiON

1.Motivation
基于点云的语义场景理解是自动驾驶汽车感知技术栈中的重要模块。然而,由于点云不像图像那样具有丰富的语义信息,在点云中这个识别异常点是一项极具挑战性的任务。本工作从两个方面缓解了点云缺乏语义信息对异常点感知的影响:1) 提出了一种新的学习范式,使模型能够学习更鲁棒的点云表征,增强点与点之间的辨别性;2) 借助额外的数据源,ShapeNet,提出了一套可以生成多样且真实伪异常的方法。实验结果表明,在公开数据集 SemanticKITTI 和 NuScenes 上,本方法显著超越了前 SOTA。
2.Method
给定一个场景点云,点云语义分割的主要任务是为点云中的每个样本点分配一个预先定义的类别,例如车、树、行人等。本工作将这些属于预先定义类别的样本点称为正常样本点。而 点云异常检测则作为点云语义分割模块的补充,用于识别那些不属于预先定义类别集合的样本点,例如桌子、椅子等无法预料的类别。本工作将这些样本点称为异常样本点。
此前的工作 REAL 将图像异常检测方法直接适配到点云异常检测领域,并通过实验发现,大量异常样本被错误分类为预先定义的类别。为了解决这一问题,REAL 提出了一种新的校正损失,用于校正正常样本的预测。然而,本工作的实验结果表明,尽管该校正损失能够提升异常样本的分类性能,但同时也对正常样本的分类性能造成了显著的负面影响。
本工作将图像异常检测方法在点云异常检测领域表现不佳的原因归结于点云不像图像那样具有丰富的语义信息。比如Figure 1左侧,即使是人类也难以识别道路中央的家具信息。因此,该工作从两个方面缓解点云缺乏丰富语义含义所带来的影响。

Figure 1 点云语义分割模块错误地将家具分类成道路
首先,该工作提出为每个样本点计算一个惩罚项,并通过额外的损失函数保证正常样本点的惩罚较小,而异常样本点的惩罚较大。然后,将该惩罚项嵌入交叉熵损失中,以动态调整模型的优化方向。通过为每个样本点学习额外的惩罚项并改进学习范式,本工作增强了样本点之间的辨别性,缓解了点云缺乏语义信息的问题,从而全面提升了异常检测能力。
此外,该工作提出利用 ShapeNet 数据集生成伪异常。ShapeNet 是一个大规模的三维形状数据集,包含超过 22 万个三维模型,覆盖 55 个主要类别和 200 多个子类别。因此,通过 ShapeNet 生成的伪异常具有较高的多样性。其次,在生成伪异常时,该工作进一步考虑了点云的采样模式,从而使生成的伪异常更加真实。因此,该工作通过生成更加多样且真实的伪异常,更好地估计和模拟了真实异常的分布,缓解了点云缺乏语义信息的问题。
2.1. 模型整体架构
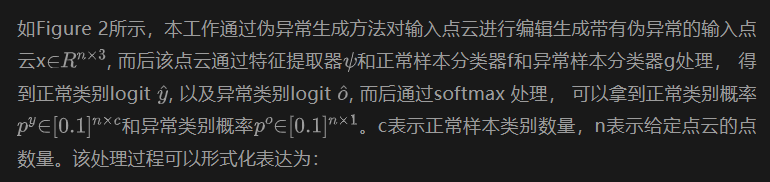

其中[·]表示拼接操作。
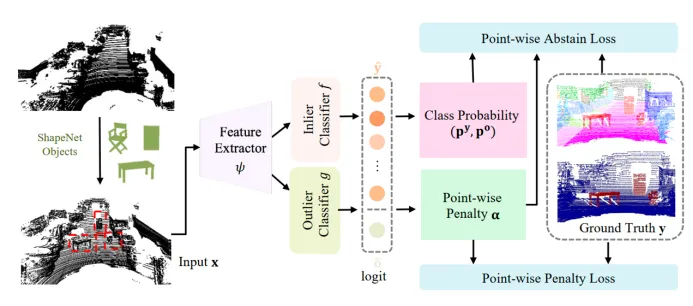
Figure 2 算法处理流程
2.2. 基于逐点惩罚的学习范式
本工作提出对每个样本点用能量函数计算一个额外的惩罚项a,惩罚项的计算如下所示:

此外,该工作通过一个额外的逐点惩罚损失函数使得对于所有的正常样本点都有个较小的惩罚,对于所有的异常样本点都有较大的惩罚。该逐点惩罚损失函数的形式化表达如下:



Figure 3 惩罚项和逐点惩罚损失之间关系
而后,该工作用惩罚项a升级交叉熵损失函数,动态调整交叉熵损失的优化重点, 升级后的交叉熵损失函数被叫做逐点拒绝(abstain)损失函数:


因此整个算法的损失函数为:


2.3.合成数据生成点云异常
该工作通过引入额外的数据源, ShapeNet,来生成更加多样且真实的伪异常,从而更好地近似真实异常分布。首先,通过伯努利分布计算插入的伪异常数量G。而后,通过循环G次下面流程来插入伪异常。
如Figure 4所示,该生成方法包括以下步骤:(a)加载物体后,基于均匀分布计算平移距离和旋转角度,并对物体进行(b)平移和(c)旋转,使其有可能放置在场景中的任意角落;(d)基于均匀分布计算的缩放系数,对物体进行缩放;(e) 将物体放置于场景地面; (f)使用被插入物体遮挡住的场景样本点来替换插入物体的样本点。

Figure 4 伪异常生成流程
3.Experiment
实验结果表明,该工作提出的方法在SemanticKITTI和NuScenes两个公开数据集上能够大幅优于之前的SOTA方法。
3.1.实验基准
该工作沿用了之前的实验基准。采用SemanticKITTI和NuScenes作为基准数据集。在SemanticKITTI中,将{other-vehicle}设为异常类别;在NuScenes中,将{barrier,constructive-vehicle,traffic-cone,trailer}设为异常类别。这些异常类别的样本在训练过程是不可见的。

3.2.定量结果

Table 1 定量结果对比
该工作沿用之前的实验设置, 选C3D(Cylinder3D)作为分割基座模型。前SOTA方法, APF,没有在NuScenes上开展实验并且没有开源代码, 因此该工作无法在NuScenes上与其进行对比。Table 1实验结果表明,该工作提出的算法在两个公开基准数据集上大幅优于之前SOTA方法。
3.3.定性结果
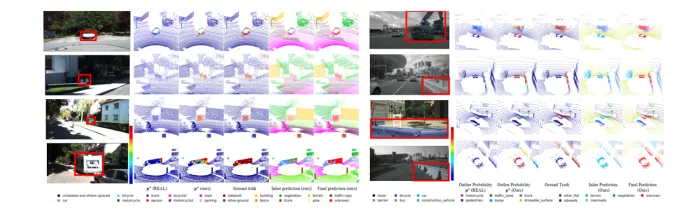
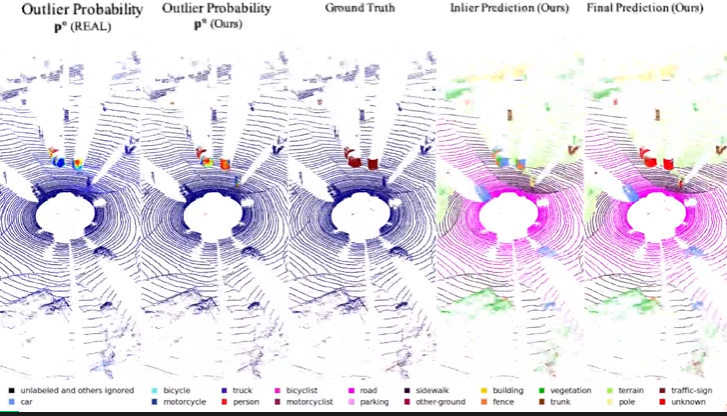
Figure 5 SemanticKITTI(左)和NuScenes(右)上的定性结果对比
与前SOTA算法对比,该工作提出的算法不管是在64线雷达采集的点云数据上(SemanticKITTI)还是32线雷达采集的点云数据(NuScenes)上都表现出了优越的性能, 不仅能够精确定位异常类别而且能够赋予较高的置信度。


























