随着越来越多的资源和框架针对各种任务进行定制,开始计算机视觉应用从未如此简单。其中一个任务就是手部追踪,它在虚拟现实、手语翻译以及许多其他人机交互相关应用中有着广泛的用途。在本文中,我将向你展示如何使用Python和网络摄像头轻松开始手部追踪算法,所有操作都在你的计算机本地运行。我们将直接使用mediapipe手部追踪解决方案,并了解其基本工作原理。
项目设置
首先创建一个空的项目目录。我强烈建议你使用虚拟环境管理器,例如Miniconda,以分离不同的Python项目。我喜欢通过在项目目录中创建本地环境来设置我的环境,以避免弄乱我的全局Conda环境。
conda create -p ./env python=3.12
conda activate ./env安装Mediapipe
接下来我们需要安装mediapipe pip包。这非常简单,它会自动安装所有所需的依赖项。
pip install mediapipe代码
现在我们可以开始创建一个main.py文件。首先导入所需的包,我们将使用opencv-python进行网络摄像头视频帧捕获,以及mediapipe手部解决方案及其绘图工具。
import cv2
import mediapipe.python.solutions.hands as mp_hands
import mediapipe.python.solutions.drawing_utils as mp_drawing
import mediapipe.python.solutions.drawing_styles as mp_drawing_styles接下来我们需要设置网络摄像头的VideoCapture。通过指定索引0,我们获取第一个可用的网络摄像头。
cap = cv2.VideoCapture(index=0)现在我们需要创建一个手部追踪对象。通过使用with语句,我们在帧捕获循环周围创建一个上下文,以便可以使用hands对象。这确保在with语句的上下文结束时,所有与追踪相关的资源都能正确清理。
with mp_hands.Hands(
model_complexity=0,
max_num_hands=2,
min_detection_confidence=0.5,
min_tracking_confidence=0.5,
) as hands:
# TODO: video Frame loop这里我们有几个配置选项。model_complexity定义是使用简单模型(0)还是更复杂的模型(1)。复杂模型在检测中通常具有更高的准确性,但会牺牲延迟。max_num_hands指定将检测到的手部数量的上限,例如,如果我们只想识别一只手,可以将其降低到1。min_detection_confidence和min_tracking_confidence分别指模型在首次检测手部时以及在保持追踪时的置信度。
为了创建视频帧循环,我们使用一个while循环,只要视频捕获打开,它就会运行。我们从视频捕获中读取最新的帧,如果成功,我们将其显示出来。请注意,我们水平翻转图像以获得类似镜子/自拍的效果。我们还会检查每一帧是否按下了键q,然后退出循环。最后在循环结束后,我们通过释放视频捕获资源来清理它。
with mp_hands.Hands(
model_complexity=0,
max_num_hands=2,
min_detection_confidence=0.5,
min_tracking_confidence=0.5,
) as hands:
while cap.isOpened():
success, frame = cap.read()
if not success:
print("Ignoring empty camera frame...")
continue
# TODO: check frame for hands
# TODO: draw detected hand landmarks on frame
cv2.imshow("Hand Tracking", cv2.flip(frame, 1))
if cv2.waitKey(1) & 0xFF == ord("q"):
break
cap.release()现在唯一剩下要做的就是实现手部关键点检测及其可视化。唯一需要考虑的是,OpenCV以BGR(蓝、绿、红颜色通道顺序)格式加载图像,而模型是在RGB上训练的,因此为了获得最佳结果,我们也应该将帧转换为RGB。
注意:你也可以尝试在不转换为RGB的情况下运行检测。在我的情况下,它仍然有效,但检测的准确性要低得多。
# Check the frame for hands
frame_rgb = cv2.cvtColor(frame, cv2.COLOR_BGR2RGB)
results = hands.process(frame_rgb)为了检查这是否有效,我们可以在检测到手部时添加一个打印语句:
if results.multi_hand_landmarks is None:
print("No hands detected")
else:
print(f"Number of hands detected: {len(results.multi_hand_landmarks)}")最后,我们可以使用mediapipe提供的绘图工具在帧上注释,以可视化帧中的手部。通过指定HAND_CONNECTIONS常量,手部关键点之间的连接以及关键点本身将被绘制出来。此外,指定的默认绘图规范允许对不同手指进行明显的着色。
# Draw the hand annotations on the image
if results.multi_hand_landmarks:
for hand_landmarks in results.multi_hand_landmarks:
mp_drawing.draw_landmarks(
image=frame,
landmark_list=hand_landmarks,
connections=mp_hands.HAND_CONNECTIONS,
landmark_drawing_spec=mp_drawing_styles.get_default_hand_landmarks_style(),
connection_drawing_spec=mp_drawing_styles.get_default_hand_connections_style(),
)mediapipe 工作原理
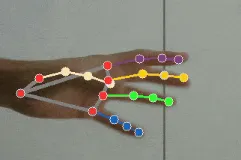
手部追踪的架构主要由两个阶段组成,一个是手掌检测,粗略地检测手部的位置,然后是手部关键点检测,更精确地定位手部和手指的不同部分。
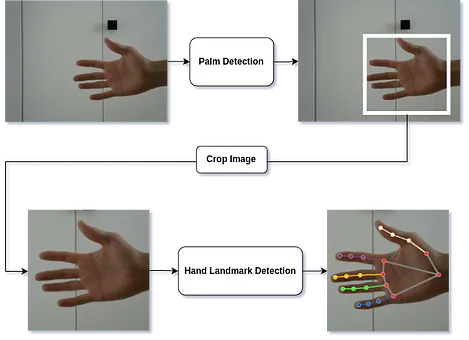
第一阶段的手掌检测模型基于SSD。因此,该模型将完整图像的像素值作为输入,并输出描述图像中手掌可能位置的边界框以及每个框的置信度分数。这里使用了一些技巧,例如将锚框(在网络中创建的分类前的提议)限制为正方形图像。
第二部分,手部关键点模型,是一个回归模型,它将手掌检测的边界框中的裁剪图像作为输入,并返回手部所有21个关键点的3D坐标。


参考资料:
- mediapipe解决方案:https://mediapipe.readthedocs.io/en/latest/solutions/hands.html
- SSD论文:https://arxiv.org/abs/1512.02325
- 完整代码:https://github.com/trflorian/hand-tracker