ROG 之缘起
ROG 的诞生是因为我们一部分业务使用 Rust 重写之后,获得了非常好的收益,比如 AVG、CPU、MEM、P99,这些数据表现非常好,大约节省了接近 50%的 CPU,内存大大降低。这个性能数据让人眼红,因此团队考虑既然 Rust 有这么好的性能,我们有没有办法提升一下用户在 Go 上的性能?

在和一些用户的对接中我们发现,让用户把 Go 业务通过 Rust 重写,难度其实非常大。很多用户会抱怨 Rust 的一些问题让他们很痛苦,比如,Rust 生命周期太复杂,泛型系统太复杂,报错看不懂,编程速度慢等等。因为这一系列问题,所以让用户把原来的 Go 项目通过 Rust 重写,对于用户来说是很难推动的事情。
于是,我们就有了一个大胆的想法,如果我们可以像使用 Rust 那样的编译技术去生成性能更好的可执行文件,同时使用 Rust 重写 Go 的 Runtime 和 GC 这两个核心组件,再通过几乎零开销的 FFI(Foreign Function Interface) 方式来支持 Rust 和 Go 之间的互调,是不是可以让用户 Go 的源码也能达到接近 Rust 的性能。这就是我们的初衷,因此有了 ROG 这个项目。
ROG 进展
我们目前测试了一些简单的场景,比如快排和二分、Simple Lisp。这些都是通过 time 命令来计算两个二进制文件执行所需要的时间。目前在快排、二分上,Go 的执行需要 5.97s,ROG 的执行需要 4.12s,在 Simple Lisp 这个项目上,Go 需要 8.17s,ROG 执行只需要 7.09s。

从以上几个基本数字来看,在一些简单的场景下,ROG 会比 Go 性能好很多。但这只是一些非常简单的 case。如果面对一些非常复杂的 case 呢?比如在复杂的微服务场景下,ROG 会有怎样的性能领先?
ROG 在上个季度刚好能够支撑 Kitex Benchmark 跑起来,目前我们完成了一次压测。

我们使用 Kitex 官方的 Benchmark 工具完成了简单的 RPC 调用测试(https://github.com/cloudwego/kitex-benchmark)。
目前,我们只测试了连接数 100,测试包大小 1024kb 的体积。在这个测试中,Go 的 QPS 可以达到 27W,ROG 28W。虽然 ROG 的 QPS 只比 Go 领先了一点,但是 P99 上有很大的提升。我们在测试过程中发现了 ROG 还有很多可以挖掘能力,只是还需要进一步优化。
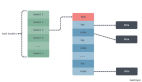
架构设计
通过刚才几个性能场景测试,我们发现 ROG 相比 Go 在不同的场景下,多多少少有一些领先。但是为什么 ROG 相比于 Go 会有这样的领先呢?早期我们其实也经历过 ROG 测试结果比 Go 还差 50%的状态。所以想先给大家介绍一下我们的设计架构。

从图中可以看出,首先会有一个 ROG 的前端来处理用户的 Go 源码,在前端经历 Parser 解析后生成 AST(Abstract Syntax Tree),做符号解析,每个函数,每个类型的符号。然后进行类型检查,分析出函数的签名以及每个变量的类型。这是一套非常常见的前端处理流程。
在经历这个过程之后,会产生一个中间语言叫做 MIR(Rust's Mid-level Intermediate Representation),之后会基于 MIR 去做一些前端时的优化,比如编译时计算、常量传播计算、逃逸分析(能够分析出哪些变量应该被逃逸到堆上去)、Inliner、SROA,以及对于特定 Go 函数的优化。
在这些优化算法处理之后,会生成一份 LLVM IR(Intermediate Representation),之后把它交给 ROG 后端。ROG 后端是我们自己魔改的一个 LLVM 版本。在 LLVM codegen 阶段我们给每个函数插入了一些对应的 Stack Check 以及对应的 STW(Stop The World) Checkpoint 指令,同时生成相应的 GC Barrier。
优化好之后就生成一份比较高质量的二进制代码了。这是对于 Go 语言的处理,而对于 Go 的 Runtime & GC 这部分,我们基本上完全是重写的。通过 Rust 重写之后,我们把这些代码通过自己维护的一个 Rust 版本去构建、打包好,调成对应的 LLVM 文件,最后和用户的 Go 代码连接起来,形成一个最终的二进制文件。这就是我们的编译流程。
收益来源
这个编译架构为什么相比 Go 或多或少有些性能优化呢?有哪些领先点?
其实领先点主要来源于三个部分。

第一部分,编译优化。因为 ROG 利用了 LLVM 积累多年的编译优化算法,能够生成一些性能更好的代码,而 Go 的编译优化会为编译速度做出一定牺牲。
第二部分,ROG 提供了跨语言 LTO(Link Time Optimization) 以及 FFI,通过几乎零开销的方式调用 Rust 提供的方法,因此在一些需要更高性能的场景,用户可以使用 Rust 开发,由 ROG 进行编译并进行调用。而 Go 对于 FFI 会使用 CGO,并且 CGO 会存在一些 overhead。
第三部分,Runtime & GC。ROG 完全使用 Rust 重写,再通过上面提供的 FFI 来保证调用的性能,而 Go 的 Runtime & GC 则是完全使用 Go 原生实现的。单纯从语言的表达能力上限来说,Go 远不如 Rust,所以如果我们通过 Rust 来重写 Runtime & GC 这两部分组件,理论上会比 Go 拥有更好的性能。
面临的挑战
介绍完性能来源之后,可能很多人会有疑问,貌似我们的主要性能受益都是来自于 LLVM。LLVM 本身优化已经做得很好了,我们做的是不是就是非常简单地把一个 Go 源码翻译到 LLVM 就行了呢?
其实整个事情并没有那么简单,在这一年里,我们踩过非常多的坑。以下举几个简单的例子。
Go Runtime
如果大家之前了解过 TinyGo,就会发现 TinyGo 的思路和 ROG 非常接近——TinyGo 也是把 Go 的源码给翻译到 LLVM。我们可以回想下在使用 TinyGo 的时候遇到过什么问题。
首先,TinyGo 需要用户手动通过 runtime.Gosched 这个函数来进行协作调度,所以它对用户代码是有影响的。如果用户没有在关键的地方去插入这个函数调度,会对它的调度产生影响。另外,TinyGo 本身也不支持多线程,并且缺少相应的 channel timer reflect 等 lib 的支持。
而 ROG 把这些问题都解决了,ROG 会在编译阶段插入代码,完成协作式调度,并且 ROG 设计的本身也是为了高性能,所以自然会对多线程进行支持,并且 ROG 对于 channel timer reflect 全部都重写。对于我们来说,解决 TinyGo 的不足的过程也相当艰难,毕竟重写整个 Runtime & GC 等是一个非常大的工作量。

Safety FFI
假设如果我们要在 Go 提供 FFI,当用户写出这样的代码会发生什么事情?

左边这张图是用户写的一份 Go 代码,里面有函数。rog_test(a *int32) 这个函数可能就是 FFI 提供的一个外部函数。如果用户直接去调用这个外部函数,而 rog test 本身是由 Rust 实现的,如右图,当我们写出这样的代码的时候,会发生什么事情?
因为 rust_tup 被 Rust Allocator 管理,Go GC 无法扫描到这个变量,所以这个变量 a 也无法被 GC 扫描到,而 “a” 这个变量是被 Go 的 Allocator 管理的,所以如果 a 无法被 GC 扫描到,那么 a 就会被 free 掉。但是这个时候, rust_tup 仍然会持有变量 a 的指针,在 Go 那边相当于是一个对外内存引用了 Go 的一个对象,但是因为 Go 扫不到这个对象,所以这个对象就被 free 掉了,但是对外内存仍然引用这个指针。
当我们提供 FFI 的时候,很有可能会面临这样的情况。这种情况该怎么处理?在 ROG 这边,我们就会通过一个模改的 Rust 编译器,提供一个 Managed Chekcer 去限制用户写出这样的代码,在编译器阶段保证用户不会写出这样的代码,保证 FFI 的安全性。这是 ROG 解决这个问题的思路。
Roadmap & 未来规划
CGO
目前 ROG 虽然能跑过 Kitex Benchmark,并在内部一些服务上做了测试,但它仍有很多功能需要改进,比如 CGO。CGO 是 Go 语言用来提供 FFI 的一种方案,但 ROG 的 FFI 是通过一种非常简单粗暴的方式提供的。目前 ROG 的 FFI 需要用户手工去标记 ROG,写上 rog:linkname 标记。这样我们在链接时才能链接上对应的符号。而 CGO 可以让用户简单的直接在 Go 文件的一个注释里写上 C 代码 import C,通过 import c 这个 package 来进行调用。
从 FFI 来说,CGO 会比现在的 ROG 方便很多,而且已有很多的开源库,以及字节内部一些服务,他们也在使用 CGO。我们在未来会支持 CGO,兼容 CGO 的表达方式,提供 ROG 需要的 FFI,生成 ROG 需要的 FFI 代码进行调用。
宏/编译器生成代码
Rust 宏在我看来是一个非常强的功能,因为 Rust 宏可以简单地在每个 Rust 进行标记,申明这个结构可以提供 Serialize(序列化)和 Deserialize(反序列化)这两种方法。这样就可以在编译时为它生成序列化和反序列化的代码,直接进行调用,而不需要像 Go 原始的 JSON,它有反射开销。而这种反射开销在需要高性能的序列化场景会有很大的性能开销。为了解决 Go 的反射开销,sonic 做出了 JIT 方案,而 JIT 对开发 sonic 的开发者来说,负担是非常大的。

那么如果我们可以把 Rust 宏的理念引入到 ROG 中,会有什么样的体验?
首先,更好的开发体验。以 Kitex 举例,我们可以直接在编译时,通过宏为每个 IDL 生成 clint 的代码,这样就不需要用户去手动调用一些 main 去生成。
其次,更高效的序列化。像 JSON 这种序列化,我们可以通过类似 Rust 宏的方式在编译时生成好序列化和反序列化所需要的代码,直接调用,这样就可以省掉反射的开销。

关于宏带来的案例,我们还在继续探索中,之后我们会基于宏做一些更好更方便的尝试。这也是我们对于宏的规划。但是不得不提到的是,宏的出现会对 Go 本身有一定的影响,因此可能只会通过注释的方式去提供,保证对 Go 语法的兼容性;并且只会在 JSON 等序列化这些地方进行一些替换,保证用户的开发体验不会受到影响。
开源
ROG 未来肯定会进行开源,并且贡献到社区。
目前我们的想法是 2024 年先在公司内部完成一些业务的试用,能够稳定地上生态环境,并且能够取得一定的收益。在这些都稳定并且处理好 Go 本身大部分特性问题之后,才会将其开源。因此如果顺利,最早可能会需要等到 2025 年的第二季度才会去准备开源工作。