在 Python 多线程编程中,concurrent.futures 模块提供了一个高层的接口来异步执行可调用对象。今天,我们将通过一个循序渐进的案例,深入了解如何使用这个强大的工具。
从一个模拟场景开始
假设我们需要处理一批网络请求。为了模拟这个场景,我们使用 sleep 来代表耗时操作:
运行这段代码,你会发现处理 10 个任务需要大约 10-15 秒。这显然不够高效。
使用传统的 threading 模块
让我们先看看使用传统的 threading 模块如何改进:
这个版本使用了多线程,性能确实提升了,但代码比较复杂,需要手动管理线程、锁和队列。
concurrent.futures 的优雅解决方案
现在,让我们看看如何使用 concurrent.futures 来简化代码:
这里我们用到了几个关键概念:
- ThreadPoolExecutor :线程池执行器,用于管理一组工作线程。创建时可以指定最大线程数。
- executor.submit() :向线程池提交一个任务。返回 Future 对象,代表将来某个时刻会完成的操作。
- as_completed() :返回一个迭代器,在 Future 完成时产生对应的 Future 对象。这意味着结果是按照完成顺序而不是提交顺序返回的。
Future 对象的高级用法
Future 对象提供了多个有用的方法,让我们通过实例来了解:
线程/进程池还是异步 IO?
IO 密集型任务:优先选择 asyncio
为什么选择 asyncio ?
- 更低的资源开销: asyncio 使用协程,不需要创建额外的线程或进程
- 更高的并发量:单线程可以轻松处理数千个并发任务
- 没有 GIL 的限制:协程在单线程内切换,完全规避了 GIL 的影响
让我们通过一个网络请求的例子来对比:
在这个例子中, asyncio 版本通常会表现出更好的性能,尤其是在并发量大的情况下。
CPU 密集型任务:使用 ProcessPoolExecutor
为什么选择多进程?
- 绕过 GIL:每个进程都有自己的 Python 解释器和 GIL
- 充分利用多核性能:可以真正实现并行计算
- 适合计算密集型任务:如数据处理、图像处理等
来看一个计算密集型任务的对比:
在这种场景下, ProcessPoolExecutor 的性能明显优于 ThreadPoolExecutor 。
混合型任务:ThreadPoolExecutor 的优势
为什么有时候选择线程池?
- 更容易与现有代码集成:大多数 Python 库都是基于同步设计的
- 资源开销比进程池小:线程共享内存空间
- 适合 IO 和 CPU 混合的场景:当任务既有 IO 操作又有计算时
示例场景:
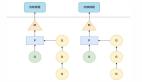
选择建议的决策树
在选择并发方案时,可以参考以下决策流程:
首先判断任务类型:
- 如果是纯 IO 密集型(网络请求、文件操作),优先选择 asyncio。
- 如果是纯 CPU 密集型(大量计算),优先选择 ProcessPoolExecutor。
- 如果是混合型任务,考虑使用 ThreadPoolExecutor。
考虑其他因素:
- 现有代码是否易于改造为异步?
- 是否需要与同步代码交互?
- 并发量有多大?
- 是否需要跨进程通信?
性能对比总结
方案 | IO密集型 | CPU密集型 | 混合型 | 资源开销 | 代码复杂度 |
asyncio | 最佳 | 较差 | 好 | 最低 | 较高 |
ThreadPoolExecutor | 好 | 较差 | 较好 | 低 | 低 |
ProcessPoolExecutor | 一般 | 最佳 | 一般 | 高 | 低 |
总的来说,选择合适的并发方案需要综合考虑任务特性、性能需求、代码复杂度等多个因素。在实际应用中,有时候甚至可以混合使用多种方案,以达到最优的性能表现。
实用技巧总结
控制线程池大小
批量提交任务
错误处理
总结
concurrent.futures 模块为 Python 并发编程提供了一个优雅的高级接口。相比传统的 threading / multiprocessing 模块,它具有以下优势:
- 使用线程池自动管理线程的生命周期
- 提供简洁的接口提交任务和获取结果
- 支持超时和错误处理
- 代码更加 Pythonic 和易于维护