译者 | 崔皓
审校 | 重楼
开篇
在本教程中,你将使用 Google 的 Gemini API 构建人工智能驱动的字幕生成器。我们将创建一个名为“AI-Subtitle-Generator”的项目,该项目的前端使用 React,后端使用 Express。准备好了吗?让我们马上出发吧!

先决条件
在构建项目之前,你需要对React 和 Express 有基本了解。
Gemini API 是什么?
Google 的 Gemini API 是一款功能强大的工具,可让你将高级 AI 功能集成到你的应用程序中。 Gemini 是多模态模型,它支持用户使用各种类型的输入,例如文本、图像、音频和视频等。
它擅长分析和处理大量文本,特别是从视频中提取信息的能力,非常适合字幕生成器的项目。
如何获取 API 密钥
API 密钥充当唯一标识符并验证你对服务的请求。它对于访问和使用 Gemini AI 的功能至关重要。这个密钥将允许我们的应用程序与 Gemini 进行通信,也是构建该项目的关键因素。
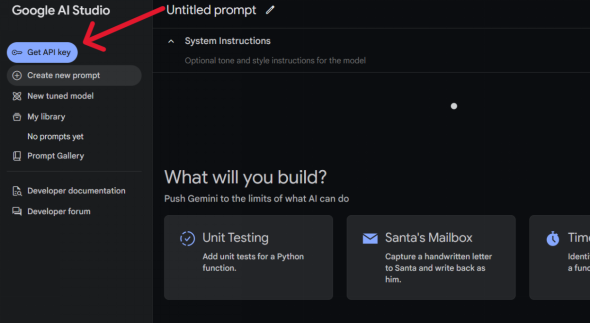
如下图所示,进入Google AI Studio ,然后点击“获取 API 密钥”(Get API key):
在打开的API KEY 页面中,单击“创建 API 密钥”:
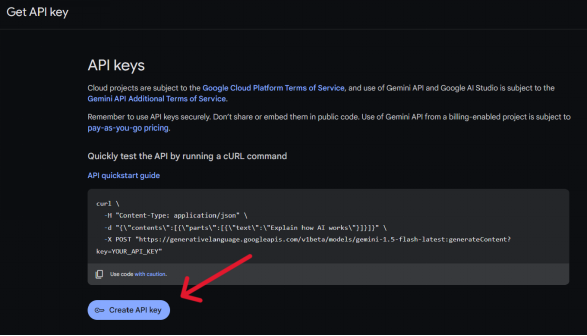
该操作将创建一个新的 API 密钥,并复制密钥对其进行妥善保存。
这个就是访问Gemini API的 密钥。此密钥用于验证应用程序对 Gemini API 的请求。每次应用程序向 Gemini 发送请求时,都必须包含此密钥。 Gemini 使用此密钥来验证请求是否来自授权来源。如果没有此 API 密钥,请求将被拒绝,同时应用也无法访问 Gemini 的服务。
项目设置
首先,基于项目创建一个新文件夹。我们称之为ai-subtitle-generator 。
在ai-subtitle-generator文件夹内,创建两个子文件夹: client和server 。 client文件夹将包含 React 前端, server文件夹将包含 Express 后端。
前端设置
我们先将重点关注放到前端,并设置一个基本的 React 应用程序。
通过如下命令,导航到client文件夹:
cd client使用Vite创建一个新的React项目。执行如下命令:
npm create vite@latest .根据提示时,选择“React”、“React + TS”或者“React + JS”。在本教程中,将使用 React + TS。当然你也可以根据喜好选择其他的选项。
接下来,使用以下命令安装依赖项:
npm install然后启动开发服务器:
npm run dev在前端处理文件上传
现在在client/src/App.tsx中,添加以下代码:
// client/src/App.tsx
const App = () => {
const handleSubmit = async (e: React.FormEvent<HTMLFormElement>): Promise<void> => {
e.preventDefault();
try {
const formData = new FormData(e.currentTarget);
console.log(formData)
} catch (error) {
console.log(error);
}
};
return (
<div>
<form onSubmit={handleSubmit}>
<input type="file" accept="video/*,.mkv" name="video" />
<input type="submit" />
</form>
</div>
);
};
export default App;在上面的代码中,我们使用了一个输入标签来接受视频并将其命名为video 。该名称将附加到FormData对象中。
在将视频发送到服务器的过程中,使用到了“键值对“的发送方式,其中”键“是video ,值是文件数据。
为什么是键值对?因为当服务器收到请求时,它需要解析传入的块。解析后,视频数据将在req.files[key]中使用,其中key是前端分配的名称(在本例中为video )。
这就是为什么使用FormData对象的原因。当创建一个新的FormData实例并将e.target传递给它时,所有表单字段及其名称将自动生成键值对的形式。
服务器设置
目前为止,我们已经获取了API 密钥,接着需要设置后端服务器。该服务器将处理来自前端上传的视频,并与 Gemini API 进行通信从而生成字幕。
通过如下命令,导航到server文件夹:
cd server并初始化项目:
npm init -y然后安装必要的包:
npm install express dotenv cors @google/generative-ai express-fileupload nodemon这些是在此项目中使用的后端依赖项:
- express :用于创建后端 API 的 Web 框架。
- dotenv :从.env文件加载环境变量。
- cors :启用跨源资源共享,允许前端与后端进行通信。
- @google/generative-ai :用于与 Gemini API 交互的 Google AI 库。
- express-fileupload :处理文件上传,可以轻松访问服务器上上传的文件。
- nodemon :更改代码时,自动重新启动服务器。
设置环境变量
现在,创建一个名为.env的文件。可以在此处管理 API 密钥。
//.env
API_KEY = YOUR_API_API
PORT = 3000更新package.json
对于该项目,我们使用 ES6 模块而不是 CommonJS。要启用此功能,请使用以下代码更新你的package.json文件:
{
"name": "server",
"version": "1.0.0",
"main": "index.js",
"type": "module", //Add "type": "module" to enable ES6 modules
"scripts": {
"start": "node server.js",
"dev": "nodemon server.js" //configure nodemon
},
"keywords": [],
"author": "",
"license": "ISC",
"description": "",
"dependencies": {
"@google/generative-ai": "^0.21.0",
"cors": "^2.8.5",
"dotenv": "^16.4.7",
"express": "^4.21.1",
"express-fileupload": "^1.5.1",
"nodemon": "^3.1.7"
}
}Express 的基本设置
创建文件server.js 。现在,让我们设置一个基本的 Express 应用程序。
// server/server.js
import express from "express";
import { configDotenv } from "dotenv";
import fileUpload from "express-fileupload";
import cors from "cors"
const app = express();
configDotenv(); //configure the env
app.use(fileUpload()); //it will parse the mutipart data
app.use(express.json()); // Enable JSON parsing for request bodies
app.use(cors()) //configure cors
app.use("/api/subs",subRoutes); // Use routes for the "/api/subs" endpoint
app.listen(process.env.PORT, () => { //access the PORT from the .env
console.log("server started");
});在代码中,我们创建一个 Express 应用程序实例,然后加载环境变量。该环境变量可以用来保存API 密钥等敏感数据。接下来,利用中间件: fileUpload准备服务器来接收上传的视频, express.json允许接收 JSON 数据, cors允许前端和后端之间的通信。
接着,定义路由(/api/subs)来处理与字幕生成相关的所有请求。路由的具体逻辑将在subs.routes.js中体现。最后,启动服务器,告诉它监听.env文件中定义的端口,从而保证请求响应。
然后,创建一系列文件夹来管理代码。当然,也可以在单个文件中管理代码,但将其构建到单独的文件夹进行管理会更加方便、更加清晰。
下面是服务器的最终文件夹结构:
server/
├── server.js
├── controller/
│ └── subs.controller.js
├── gemini/
│ ├── gemini.config.js
├── routes/
│ └── subs.routes.js
├── uploads/
├── utils/
│ ├── fileUpload.js
│ └── genContent.js
└── .env
注意:现在不必担心创建此文件夹结构。这仅供参考。跟着文章一步步来,在后面的内容中会逐步搭建这个结构。
创建路由
创建一个routes文件夹,然后创建subs.routes.js文件如下 :
// server/routes/sub.routes.js
import express from "express"
import { uploadFile } from "../controller/subs.controller.js" // import the uploadFile function from the controller folder
const router = express.Router()
router.post("/",uploadFile) // define a POST route that calls the uploadFile function
export default router // export the router to use in the main server.js file此代码定义了服务器的路由,特别是处理视频上传和字幕生成的路由。
使用express.Router()创建一个新的路由器实例。这使我们能够定义新的路由,该路由可以独立于主服务器路由,从而改进代码组织结构,使之更加清晰。在 API 接入点的根路径("/")处定义 POST 路由。当对此路由发出 POST 请求时(当用户在前端提交视频上传表单时会发生),将调用uploadFile函数。该函数将处理实际的上传和字幕生成。
最后,我们导出路由器,以便可以在主服务器文件(server.js)中使用它来将此路由连接到主应用程序。
配置Gemini
接下来的任务就是配置应用程序如何与 Gemini 交互。
创建一个gemini文件夹,然后创建一个名为gemini.config.js的新文件:
// server/gemini/gemini.config.js
import {
GoogleGenerativeAI,
HarmBlockThreshold,
HarmCategory,
} from "@google/generative-ai";
import { configDotenv } from "dotenv";
configDotenv();
const genAI = new GoogleGenerativeAI(process.env.API_KEY); // Initialize Google Generative AI with the API key
const safetySettings = [
{
category: HarmCategory.HARM_CATEGORY_HARASSMENT,
threshold: HarmBlockThreshold.BLOCK_NONE,
},
{
category: HarmCategory.HARM_CATEGORY_HATE_SPEECH,
threshold: HarmBlockThreshold.BLOCK_NONE,
},
{
category: HarmCategory.HARM_CATEGORY_DANGEROUS_CONTENT,
threshold: HarmBlockThreshold.BLOCK_NONE,
},
{
category: HarmCategory.HARM_CATEGORY_SEXUALLY_EXPLICIT,
threshold: HarmBlockThreshold.BLOCK_NONE,
},
];
const model = genAI.getGenerativeModel({
model: "gemini-1.5-flash-001", //choose the model
safetySettings: safetySettings, //optional safety settings
});
export default model; //export the model在上面的代码中, safetySettings是可选的。这些设置允许你定义 Gemini 输出中潜在有害内容(例如仇恨言论、暴力或露骨内容)的阈值。
创建一个控制器来处理端点逻辑
创建一个controller文件夹,并在其中创建一个名为subs.controller.js的文件。在此文件中,你将处理与 Gemini 模型交互的端点逻辑。
在 server/controller/subs.controller.js ,添加这段代码:
// server/controller/subs.controller.js
import { fileURLToPath } from "url";
import path from "path";
import fs from "fs";
const __filename = fileURLToPath(import.meta.url); //converts the module URL to a file path
const __dirname = path.dirname(__filename); //get the current file directory
export const uploadFile = async (req, res) => {
try {
if (!req.files || !req.files.video) { //if there is no file available, return error to the client
return res.status(400).json({ error: "No video uploaded" });
}
const videoFile = req.files.video; //access the video
const uploadDir = path.join(__dirname, "..", "uploads"); //path to upload the video temporarily
if (!fs.existsSync(uploadDir)) { //check if the directory exists
fs.mkdirSync(uploadDir); //if not create a new one
}
const uploadPath = path.join(uploadDir, videoFile.name);
await videoFile.mv(uploadPath); //it moves the video from the buffer to the "upload" folder
return res.status(200).json({ message:"file uploaded sucessfully" });
} catch (error) {
return res
.status(500)
.json({ error: "Internal server error: " + error.message });
}
};由于我们使用的是 ES6 模块,因此__dirname默认情况下不可用。与 CommonJS 相比,文件处理机制有所不同。因此,将使用fileURLToPath来处理文件路径。
将文件从默认的临时位置(缓冲区)移动到uploads夹。
但文件上传过程尚未完成。我们仍然需要将文件发送到Google AI文件管理器,上传后,它会返回一个URI,模型会使用这个URI进行视频分析。
如何将文件上传到 Google AI 文件管理器
创建文件夹utils并创建文件fileUpload.js 。你可以参考上面提供的文件夹结构。
// server/utils/fileUpload.js
import { GoogleAIFileManager, FileState } from "@google/generative-ai/server";
import { configDotenv } from "dotenv";
configDotenv();
export const fileManager = new GoogleAIFileManager(process.env.API_KEY); //create a new GoogleAIFileManager instance
export async function fileUpload(path, videoData) {
try {
const uploadResponse = await fileManager.uploadFile(path, { //give the path as an argument
mimeType: videoData.mimetype,
displayName: videoData.name,
});
const name = uploadResponse.file.name;
let file = await fileManager.getFile(name);
while (file.state === FileState.PROCESSING) { //check the state of the file
process.stdout.write(".");
await new Promise((res) => setTimeout(res, 10000)); //check every 10 second
file = await fileManager.getFile(name);
}
if (file.state === FileState.FAILED) {
throw new Error("Video processing failed");
}
return file; // return the file object, containing the upload file information and the uri
} catch (error) {
throw error;
}
}在上面的代码中,我们创建了一个名为fileUpload的函数,它带有两个参数。这些参数将从控制器函数传递,我们稍后将对其进行设置。
fileUpload函数使用fileManager.uploadFile方法将视频发送到 Google 的服务器。此方法需要两个参数:文件路径和包含文件元数据(其 MIME 类型和显示名称)的对象。
由于 Google 服务器上的视频处理需要时间,因此我们需要检查文件的状态。我们使用一个循环来执行此操作,该循环使用fileManager.getFile()每 10 秒检查一次文件的状态。只要文件的状态为PROCESSING,循环就会继续。一旦状态更改为SUCCESS或FAILED ,循环就会停止。
然后,该函数检查处理是否成功。如果是,则返回文件对象,其中包含有关上传和处理的视频的信息,包括其 URI。否则,如果状态为FAILED ,该函数将引发错误。
将 URI 传递给 Gemini 模型
在utils文件夹中,创建一个名为genContent.js的文件:
// server/utils/genContent.js
import model from "../gemini/gemini.config.js";
import { configDotenv } from "dotenv";
configDotenv();
export async function getContent(file) {
try {
const result = await model.generateContent([
{
fileData: {
mimeType: file.mimeType,
fileUri: file.uri,
},
},
{
text: "You need to write a subtitle for this full video, write the subtitle in the SRT format, don't write anything else other than a subtitle in the response, create accurate subtitle.",
},
]);
return result.response.text();
} catch (error) {
throw error;
}
}导入我们之前配置的模型。创建一个名为getContent的函数。 getContent函数获取文件对象(从fileUpload函数返回)。
将文件 URI 和mimi传递给模型。然后,我们将提供提示,指示模型为整个视频生成 SRT 格式的字幕。如果需要,你还可以添加提示。然后返回响应。
更新subs.controller.js文件
最后,我们需要更新控制器文件。我们已经创建了fileUpload和getContent函数,现在我们将在控制器中使用它们并提供所需的参数。
在 server/controller/subs.controller.js :
// server/controller/subs.controller.js
import { fileURLToPath } from "url";
import path from "path";
import fs from "fs";
import { fileUpload } from "../utils/fileUpload.js";
import { getContent } from "../utils/genContent.js";
const __filename = fileURLToPath(import.meta.url);
const __dirname = path.dirname(__filename);
export const uploadFile = async (req, res) => {
try {
if (!req.files || !req.files.video) {
return res.status(400).json({ error: "No video uploaded" });
}
const videoFile = req.files.video;
const uploadDir = path.join(__dirname, "..", "uploads");
if (!fs.existsSync(uploadDir)) {
fs.mkdirSync(uploadDir);
}
const uploadPath = path.join(uploadDir, videoFile.name);
await videoFile.mv(uploadPath);
const response = await fileUpload(uploadPath, req.files.video); //we pass 'uploadPath' and the video file data to 'fileUpload'
const genContent = await getContent(response); //the 'response' (containing the file URI) is passed to 'getContent'
return res.status(200).json({ subs: genContent }); //// return the generated subtitles to the client
} catch (error) {
console.error("Error uploading video:", error);
return res
.status(500)
.json({ error: "Internal server error: " + error.message });
}
};至此,后台API就完成了。现在,我们将继续更新前端。
更新前端
我们的前端目前只允许用户选择视频。在本节中,我们将更新它以将视频数据发送到后端进行处理。然后,前端将从后端接收生成的字幕并启动.srt文件的下载。
导航到client文件夹:
cd client安装axios 。我们将使用它来处理 HTTP 请求。
npm install axios在client/src/App.tsx中:
// client/src/App.tsx
import axios from "axios";
const App = () => {
const handleSubmit = async (e: React.FormEvent<HTMLFormElement>): Promise<void> => {
e.preventDefault();
try {
const formData = new FormData(e.currentTarget);
// sending a POST request with form data
const response = await axios.post(
"http://localhost:3000/api/subs/",
formData
);
// creating a Blob from the server response and triggering the file download
const blob = new Blob([response.data.subs], { type: "text/plain" });
const link = document.createElement("a");
link.href = URL.createObjectURL(blob);
link.download = "subtitle.srt";
link.click();
link.remove();
} catch (error) {
console.log(error);
}
};
return (
<div>
<form onSubmit={handleSubmit}>
<input type="file" accept="video/*,.mkv" name="video" />
<input type="submit" />
</form>
</div>
);
};
export default App;axios向后端 API 端点(/api/subs)发出 POST 请求。服务器将处理视频,这可能需要一些时间。
服务器发送生成的字幕后,前端接收它们作为响应。为了处理此响应并允许用户下载字幕,我们将使用 Blob。 Blob(二进制大对象)是一种 Web API 对象,表示原始二进制数据,本质上就像文件一样。在我们的例子中,从服务器返回的字幕将被转换为 Blob,然后可以在用户的浏览器中触发下载。
概括
在本教程中,你学习了如何使用 Google 的 Gemini API、React 和 Express 构建人工智能驱动的字幕生成器。你可以上传视频,发送到Gemini API进行字幕生成,并提供生成的字幕供下载。
结论
就是这样!你已使用 Gemini API 成功构建了人工智能驱动的字幕生成器。为了更快地进行测试,请从较短的视频剪辑(3-5 分钟)开始。较长的视频可能需要更多时间来处理。
想要创建可定制的视频提示应用程序吗?只需添加一个输入字段,让用户输入提示,将该提示发送到服务器,并使用它代替硬编码的提示。仅此而已。
译者介绍
崔皓,51CTO社区编辑,资深架构师,拥有18年的软件开发和架构经验,10年分布式架构经验。