12 月 18 日消息,Meta 携手斯坦福大学,推出全新 AI 模型系列 Apollo,显著提升机器对视频的理解能力。
IT之家注:尽管人工智能在处理图像和文本方面取得了巨大进步,但让机器真正理解视频仍然是一个重大挑战。
视频包含复杂的动态信息,人工智能更难处理这些信息,不仅需要更多的计算能力,而且如何设计最佳 AI 视频解读系统,也存在诸多困难。
在视频处理方面,研究人员发现,保持每秒恒定的帧采样率能获得最佳结果。因此 Apollo 模型使用两个不同的组件,一个处理单独的视频帧,而另一个跟踪对象和场景如何随时间变化。
此外,在处理后的视频片段之间添加时间戳,有助于模型理解视觉信息与文本描述之间的关系,保持时间感知。

在模型训练方面,团队研究表明训练方法比模型大小更重要。Apollo 模型采用分阶段训练,按顺序激活模型的不同部分,比一次性训练所有部分效果更好。
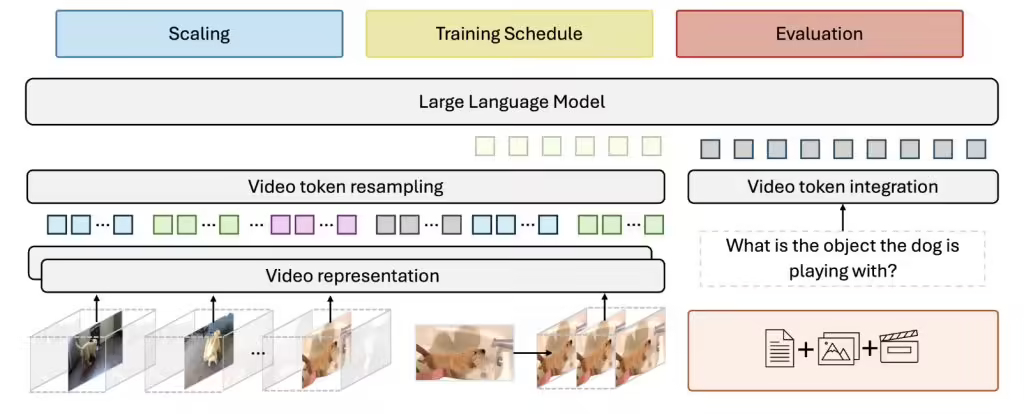
此外 Meta 公司还不断优化数据组合,发现 10~14% 的文本数据,其余部分略微偏向视频内容,可以更好地平衡语言理解和视频处理能力。
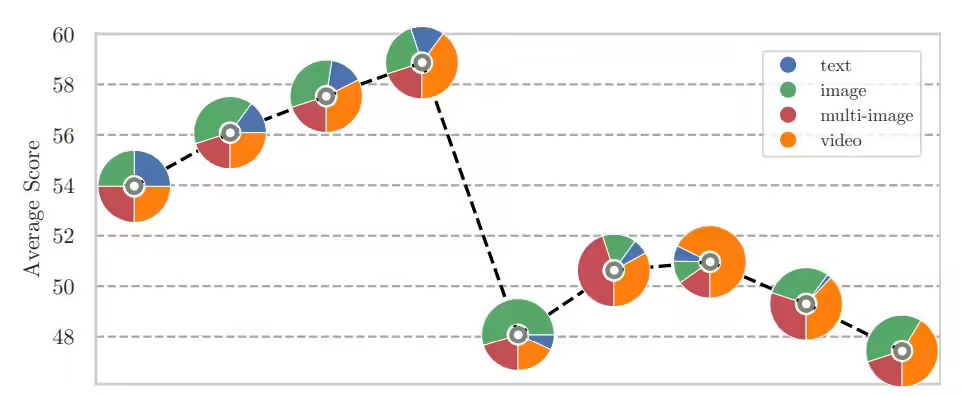
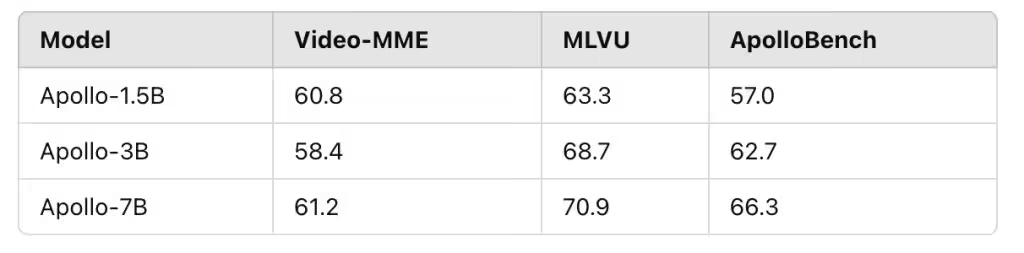
Apollo 模型在不同规模上均表现出色,较小的 Apollo-3B 超越了 Qwen2-VL 等同等规模的模型,而 Apollo-7B 超过更大参数的同类模型,Meta 已开源 Apollo 的代码和模型权重,并在 Hugging Face 平台提供公开演示。
参考