













在时间序列分析领域中,数据缺失是一个不可避免的挑战。无论是由于传感器故障、数据传输中断还是设备维护等原因,这些缺失都会对数据分析和预测造成显著影响。传统的处理方法,如前向填充或简单插值,虽然实现简单,但在处理复杂数据时往往表现不足。

具体来说,当时间序列具有以下特征时,传统方法的局限性就会显现:
- 存在复杂的非线性模式
- 包含多层次的趋势变化
- 数据波动性较大
本文将通过实际案例,详细探讨如何运用机器学习技术来解决时间序列的缺失值问题。
数据说明
为了确保研究的可重复性,我们构建了一个模拟的能源生产数据集。这个数据集具有以下特征:
- 时间范围:2023年1月1日至2023年3月1日
- 采样频率:10分钟
- 数据特点:包含真实的昼夜能源生产周期
- 缺失设置:随机选择10%的数据点作为缺失值
让我们首先看看如何生成这个数据集:
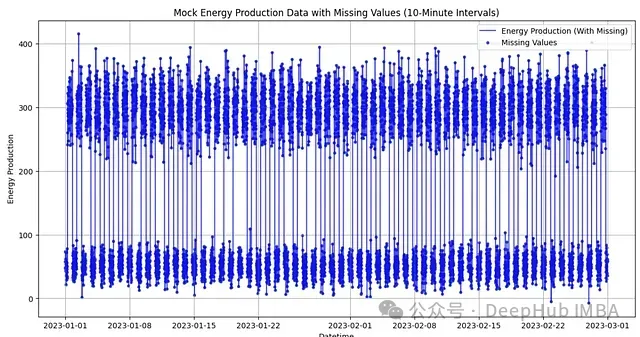 图1:模拟能源生产数据可视化。蓝线表示能源生产数据,散点表示缺失值的位置
图1:模拟能源生产数据可视化。蓝线表示能源生产数据,散点表示缺失值的位置
从上图中,我们可以清晰地观察到以下特征:
- 数据展现出明显的周期性波动,这反映了能源生产的昼夜变化规律
- 缺失值(散点标记)随机分布在整个时间序列中
- 能源生产量在白天和夜间有显著的水平差异
这个数据集为我们研究不同补充方法的效果提供了理想的测试基础。在接下来的分析中,我们将详细探讨如何运用机器学习方法来补充这些缺失值。
机器学习在时间序列补充中的应用基础
机器学习方法的优势
在时间序列数据分析中,机器学习方法相比传统补充方法具有独特优势。传统方法通常基于简单的统计假设,而机器学习方法则能够自适应地学习数据中的复杂模式和多维依赖关系。
非线性关系处理:在能源生产等实际场景中,变量之间往往存在复杂的非线性关系。机器学习模型能够自动捕捉这些非线性模式,而无需预先指定关系形式。
多维特征利用:当数据集包含多个相关变量时,机器学习模型可以同时考虑多个特征的影响,从而提供更准确的估计。
大规模缺失处理:对于连续时间段的缺失,机器学习可以通过学习数据的长期模式来提供更可靠的补充值。
异常模式识别:在处理非随机缺失时,机器学习方法表现出较强的鲁棒性,能够识别并适应异常模式。
线性回归补充方法实现
我们首先探讨线性回归这一基础但高效的补充方法。以下是详细的实现步骤:
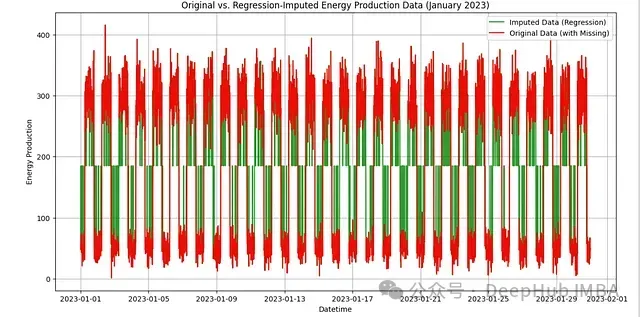 图2:线性回归补充效果可视化。绿线表示补充后的数据,红线表示原始数据
图2:线性回归补充效果可视化。绿线表示补充后的数据,红线表示原始数据
补充效果的多维度评估
为了全面评估补充效果,我们需要从多个维度进行分析。以下是详细的评估框架:
这个统计分析揭示了以下关键发现:
- 数据完整性:补充后的数据集从7648个观测值增加到8497个,实现了完整覆盖。
- 中心趋势:补充后数据的均值(185.07)与原始数据基本一致,表明保持了数据的整体水平。
- 离散程度:补充数据的标准差(120.31)略低于原始数据(126.82),表明发生了一定程度的平滑。
- 分布特征:虽然最大值和最小值保持不变,但中位数的变化反映出分布形态有所改变。
通过这些初步分析,我们可以看到线性回归方法在保持数据基本特征方面表现良好,但也存在一定的局限性,特别是在处理数据的变异性方面。在下一部分中,我们将进一步探讨更多高级评估指标,以及决策树回归等其他补充方法的表现。
时间序列补充效果的深入评估
在时间序列分析中,仅依靠基本的统计指标是不够的。我们需要特别关注数据的时序特性,包括自相关性、趋势和季节性模式。让我们逐步深入这些关键评估维度。
自相关性分析
自相关性反映了时间序列中相邻观测值之间的依赖关系。保持适当的自相关结构对于确保补充数据的时序特性至关重要。以下是详细的分析过程:
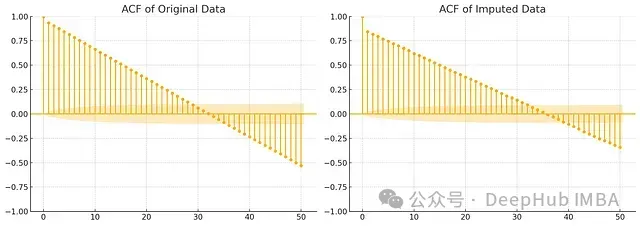 图3:自相关函数对比分析。左图显示原始数据的自相关性,右图显示补充后数据的自相关性
图3:自相关函数对比分析。左图显示原始数据的自相关性,右图显示补充后数据的自相关性
从自相关分析中,我们可以观察到几个重要特征:
- 短期相关性:补充数据在短期滞后期(1-5个lag)的自相关系数与原始数据非常接近,表明短期时间依赖关系得到了良好保持。
- 周期性特征:两个图中都清晰显示出规律的波动模式,这反映了数据中的日周期特性被很好地保留。
- 相关强度:补充数据的自相关系数整体略低于原始数据,这是线性回归补充过程中不可避免的平滑效应导致的。
时间序列分解分析
为了更深入地理解补充效果,我们使用STL(Seasonal-Trend decomposition using Loess)方法将时间序列分解为趋势、季节性和残差组件:
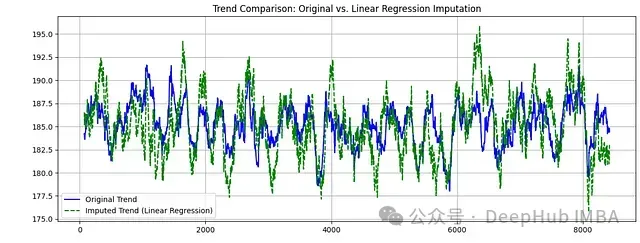 图4:趋势组件比较。蓝线表示原始数据趋势,绿虚线表示补充数据趋势
图4:趋势组件比较。蓝线表示原始数据趋势,绿虚线表示补充数据趋势
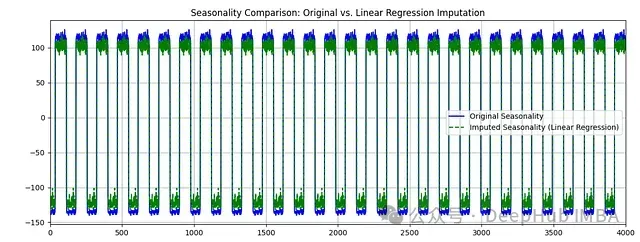 图5:季节性组件比较。展示了原始数据和补充数据的周期性模式。
图5:季节性组件比较。展示了原始数据和补充数据的周期性模式。
通过分解分析我们发现:
趋势组件特征:
- 补充数据很好地保持了原始数据的长期趋势方向
- 趋势线的平滑程度增加,这是线性回归方法的特性导致的
- 关键的趋势转折点得到了准确保持
季节性组件特征:
- 日内周期的基本模式被准确捕获
- 补充数据的季节性振幅略有减小,表明极值被部分平滑
- 周期性的时间点(如日出、日落时段)的变化模式得到保持
这些分析结果提示我们,虽然线性回归方法在保持数据的基本时序特性方面表现不错,但在处理极值和突变点方面可能存在局限,所以我们选用一些更好的模型如决策树回归器,来改善这些方面的表现。
决策树回归方法的应用与评估
在观察到线性回归方法的局限性后,我们引入决策树回归器作为一种更灵活的补充方法。决策树的非线性特性使其能够更好地捕捉数据中的复杂模式。
决策树回归器的实现
让我们首先看看如何使用决策树进行缺失值补充:
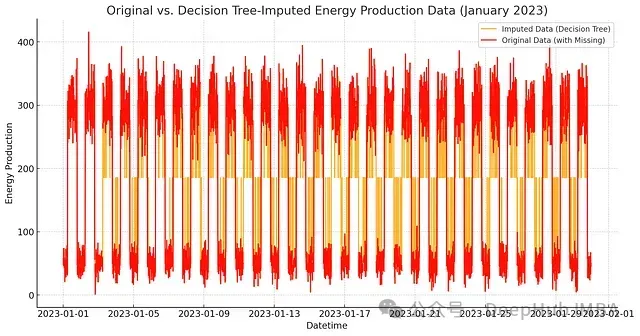 图6:决策树补充结果可视化。橙线表示决策树补充的数据,红线表示原始数据
图6:决策树补充结果可视化。橙线表示决策树补充的数据,红线表示原始数据
从图中可以直观地看到,决策树方法在保持数据特征方面展现出了以下优势:
- 更好地保持了数据的局部变化特征
- 对极值的处理更为准确
- 补充结果展现出更自然的波动性
补充效果对比分析
让我们通过各项指标来系统比较两种方法的表现:
核心统计指标对比:
这些数据揭示了一些重要的发现:
分布特征保持:
- 决策树补充的数据在标准差方面(120.63)比线性回归(120.31)更接近原始数据(126.82)
- 两种方法都很好地保持了数据的整体范围(最小值和最大值)
- 决策树在四分位数的保持上表现更好,特别是在中位数方面
自相关性分析:
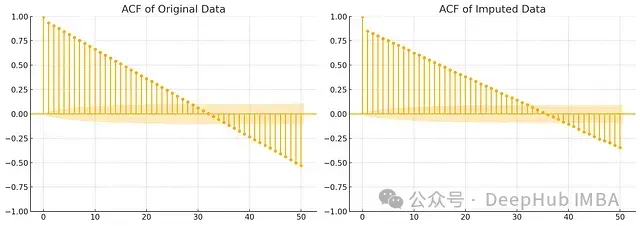 图7:两种方法的自相关分析对比
图7:两种方法的自相关分析对比
决策树方法在时间依赖性的保持方面表现出明显优势:
- 更准确地保持了短期相关性强度
- 更好地捕捉了周期性模式
- 自相关结构的衰减特征更接近原始数据
- 趋势和季节性分解:
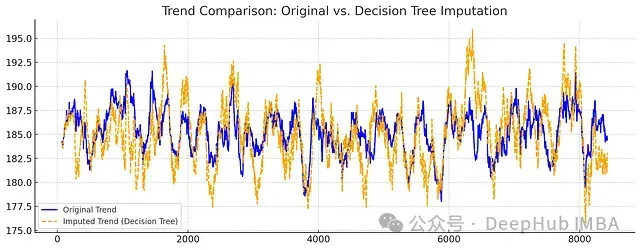 图8:趋势组件比较
图8:趋势组件比较
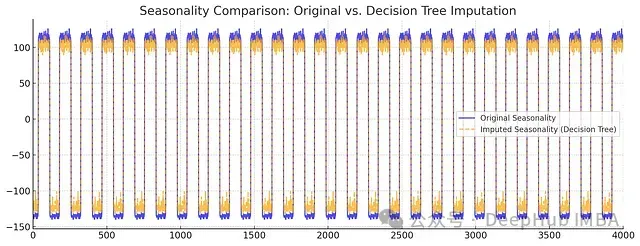 图9:季节性组件比较
图9:季节性组件比较
从分解结果可以看出:
- 决策树方法在保持趋势的细节特征方面表现更好
- 季节性模式的振幅和相位都得到了更准确的保持
- 整体而言,决策树补充的数据展现出更自然的时间序列特性
方法优劣势总结与应用建议
基于以上分析,我们可以得出以下结论:
线性回归方法的特点:
- 优势:计算效率高,实现简单
- 劣势:对非线性模式的捕捉能力有限
- 适用场景:数据呈现明显的线性趋势,且波动较为规律
决策树方法的特点:
- 优势:能更好地处理非线性关系,保持数据的局部特征
- 劣势:计算复杂度较高,需要更多的参数调优
- 适用场景:数据具有复杂的非线性模式,需要保持精细的局部特征
实践建议:
- 对于简单的时间序列,可以优先考虑线性回归方法
- 在处理复杂模式的数据时,建议使用决策树方法
- 可以根据具体应用场景的需求(如计算资源限制、精度要求等)来选择合适的方法
本文展示了机器学习方法在时间序列缺失值补充中的有效性,并提供了方法选择的实践指导。这些方法和评估框架可以推广到其他类似的时间序列分析场景中。


























