













在现代高性能数据库和缓存系统中,跳表(Skip List)作为一种高效的有序数据结构,被广泛应用于快速查找、插入和删除操作。Redis 是一个开源的键值对存储系统,它支持多种数据类型,并以其出色的性能而闻名。其中,Redis 使用了跳表来实现有序集合(Sorted Set),以保证其高效的数据处理能力。
本文将详细介绍如何使用 Go 语言从零开始实现一个类似于 Redis 的跳表。我们将探讨跳表的基本原理、设计思路以及具体的实现方法。通过本篇文章的学习,你不仅能够了解跳表的工作机制,还能够在实际项目中应用这一强大的数据结构。

定义基础数据结构
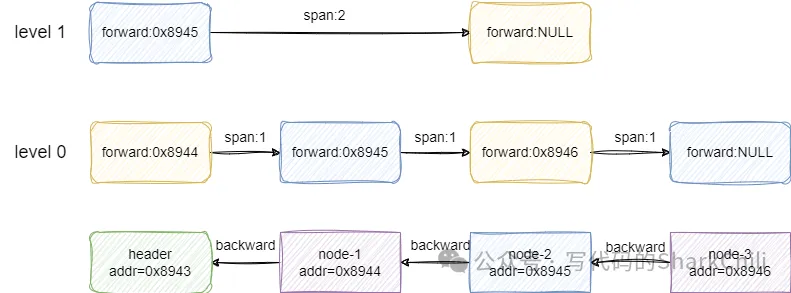
redis中跳表通过score标识元素的大小,通过redis obj维护节点的信息,与此同时为了保证查询的高效,它会为每个节点维护一份随机高度的索引记录当前节点的某个前驱节点:
对应我们给出节点的代码实现:
zskiplistLevel的代码实现比较简单,通过forward 记录本层索引的前驱节点,并用span维护当前节点需要跨几步才能走到该前驱节点:
通过上述概念构成无数个节点即称为跳表,如下图所示,各个节点都用一个level数组记录本层索引到前驱节点的地址和跨度,而跳表也用一个header和tail指针维护跳表的头尾节点:
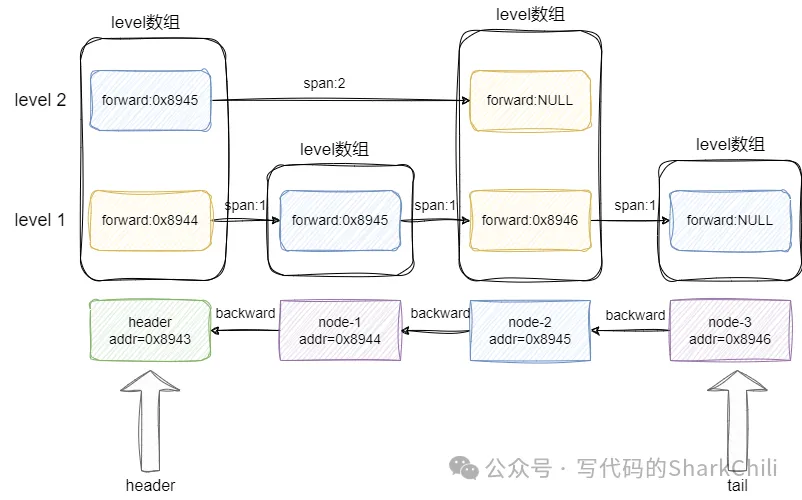
对应的跳表结构体的代码如下所示:
实现初始化方法
对应的我们也给出跳表的初始化代码,大体逻辑是初始化跳表之后,初始化一个全空的索引和维护跳表的各种初始化信息,对应的笔者也对此代码做了详尽的注释,读者可自行参阅:
跳表插入操作
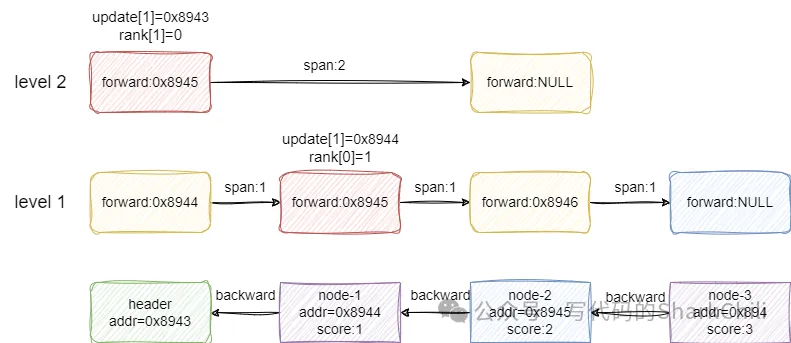
插入新节点时,本质上就是通过各层索引找到小于插入节点x的score的最大值,并记录到update数组中,同时将头节点跨到update数组元素的跨度值记录到rank数组中,如下图所示,假如我们插入节点1.5,那么对应各层索引的在update和rank两个数组中维护的信息是:
- level2级中update记录header节点,所以跨度为0。
- level1级中update记录的是节点1,跨度为1。
然后基于此信息将x插入:
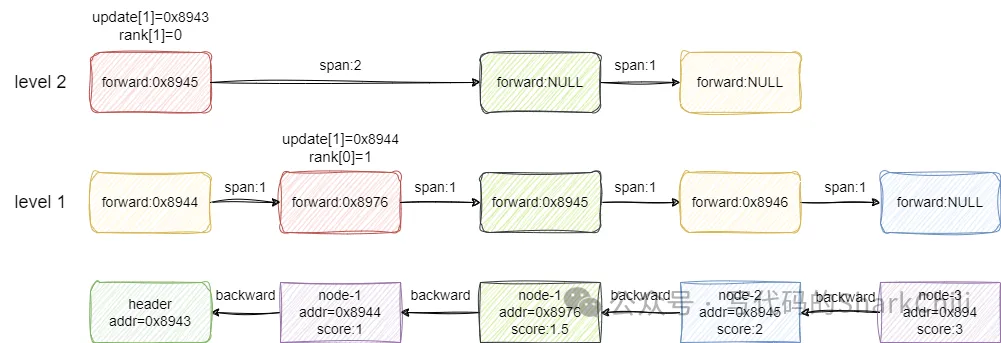
对应的代码和上述图解逻辑一致,对应的实现细节笔者都做好了标注:
跳表查询操作
有了插入操作的基础后,查询操作实现也比较容易了,即从头节点的最高索引开始不断向前找,如果没有则往下一级索引前向找,找到后返回经过的跨度即可。
如下图,我们希望查找元素2,直接从头节点的2级索引开始看,就是元素2比对一致,返回跨度2,即跨2步就能到达:
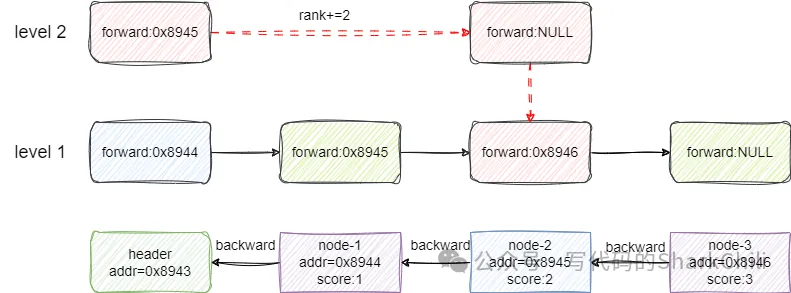
对应代码如下,和笔者说明一致,这里笔者也做了详尽的标注提供参考:
跳表删除操作
删除操作本质上也是找到要删除节点索引的前后节点,然后将这些节点关联,并修改其之间跨度,如下图我们要删除1.5节点,对应各层查找结果为:
- 3级索引找到头节点,因为前方不是1.5的节点索引,直接跨度减1即。
- 2级索引找到头节点,前方就是1.5的索引,删除掉后跨度改为header索引到1.5+1.5到前向节点跨度减去1,这里的减去1代表删除了节点1.5的跨步。
- 1级索引同2级索引,不多做赘述。
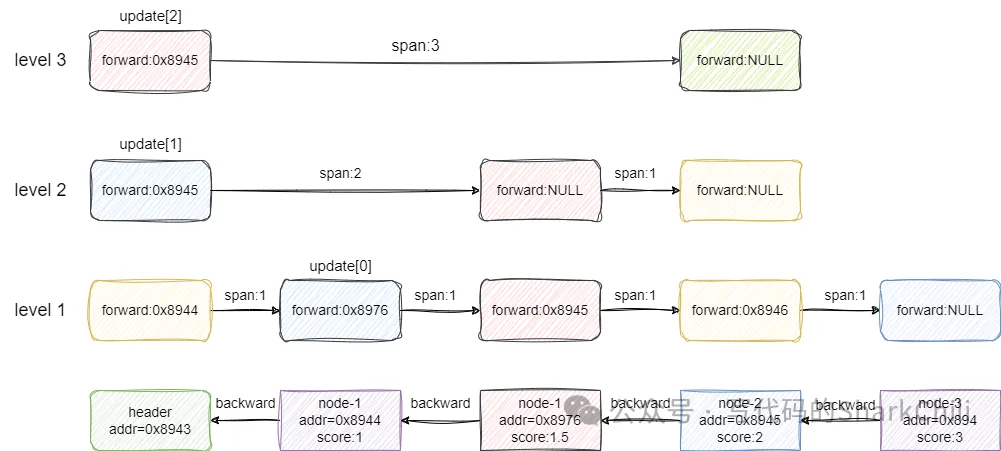
对应的代码示例如下,整体逻辑和笔者描述基本一致,先通过update找到删除节点x的前一个元素,然后调用zslDeleteNode进行删除:
对应zslDeleteNode细节就如笔者上图所讲解的步骤,读者可参考注释进行阅读:
小结
通过本文的详细讲解,我们从零开始使用 Go 语言实现了一个类似于 Redis 的跳表。我们首先介绍了跳表的基本原理和设计思路,然后逐步实现了跳表的各种核心操作,包括插入、查找和删除。最后,我们对跳表的性能进行了分析,并探讨了其在 Redis 有序集合和其他场景中的应用。




















