












日前,针对国家市场监管总局宣布依法对英伟达公司开展反垄断立案调查,英伟达公司发言人表示公司凭借实力取胜,这反映在他们的基准测试结果和对客户的价值上,引发热议。
当前,生成式AI的发展加速了全球AI算力需求的井喷。作为当前一骑绝尘的GPU供应商,英伟达的高端GPU在全球受到热抢,这给了其足够的底气。然而,此次反垄断调查涉及的迈络思InfiniBand 互联技术,却让我们看到了国产替代方案的可能性。尤其是柏睿数据等国产厂商在RDMA技术创新方面的突破,足以支撑与各类GPU的混合组网,其高性能实力同样“反映在基准测试结果和对客户的价值上”。

据了解,柏睿数据是一家以高性能计算为核心优势的智能数据算力基础设施提供商,以“全内存分布式计算引擎“为核心研发了新一代高性能、标准化、全智能的数据智能产品体系。
柏睿数据通过将RDMA封装成Socket接口,使得开发人员可以使用熟悉的Socket编程模型,而无需直接处理RDMA的复杂性。这一创新简化了RDMA的应用门槛,可以更容易地与现有的应用程序和系统集成,提高了可移植性、兼容性和易维护性。
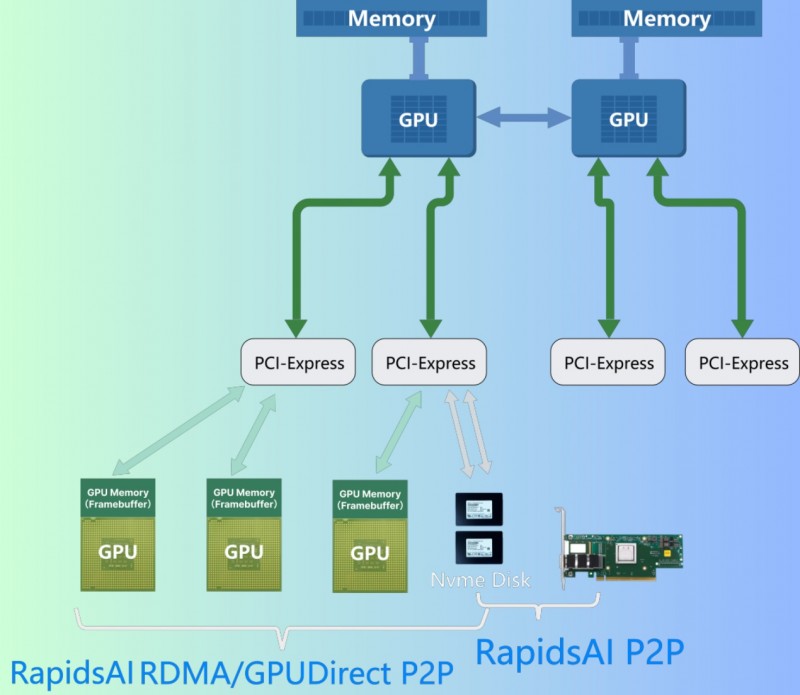
为满足AI时代模型训练的算力需求,分布式AI集群系统成为了满足AI应用算力需求的首选。而这对于多台服务器之间的数据交换则形成了很大的考验,需要以大规模、高性能、低延时的网络作为基础。凭借低延迟和高吞吐量的优势,RDMA 现已成为 AI 存储系统中的重要技术选项。
最新发布的《柏睿RDMA socket大规模测试400g》报告,为柏睿数据的高性能RDMA技术提供了有力的数据支撑。该测试在一个大规模400G RoCE集群中进行,对比了柏睿RDMA Socket与传统TCP以太网以及原生RDMA的性能表现。测试结果显示,柏睿RDMA Socket在时延和带宽方面均展现出显著优势,为国产RDMA技术的发展注入了强劲动力。

该次测试采用柏睿自研发的基准测试 Benchmark 工具,该工具实现了 对柏睿 RDMA Socket、原生 RDMA 和 TCP 以太网在不同包大小、多线程等情况下的性能测试。该工具有助于开发⼈员评估不同通信⽅式在不同场景下的性能表现,以便选择最适合应⽤需求的通信⽅式。同时,该⼯具还可帮助开发⼈员优化代码,提⾼通信性能,从⽽提升应⽤的整体性能表现。
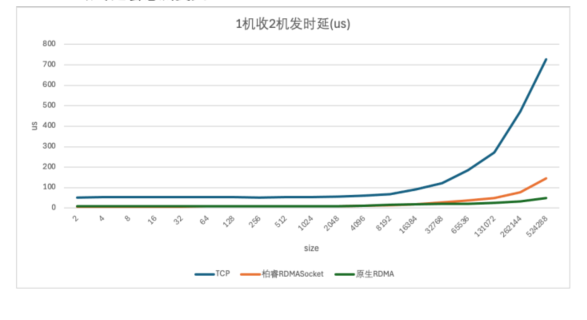
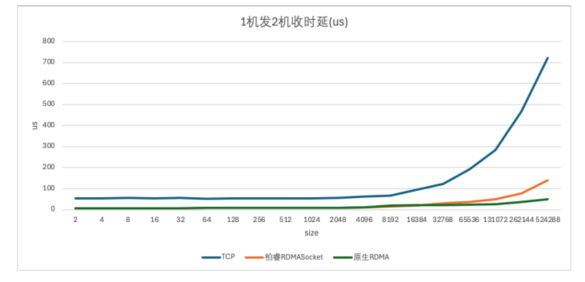
在时延方面,柏睿RDMA Socket的表现尤为出色。测试数据显示,在发送包大小不超过RDMA的4096 MTU时,柏睿RDMA Socket与原生RDMA的时延基本持平,且整体比TCP以太网时延快7倍左右。即使在发送包大小超过RDMA 的 4096 MTU时,柏睿RDMA Socket的时延也仅略有增加,但整体仍然比TCP以太网快5倍左右。总体来说,使⽤柏睿 RDMA Socket 替代 TCP 能够将时延显著降低.这一优势在复杂的数据处理场景中尤为重要,能够显著提升系统的响应速度和用户体验。
在带宽方面,柏睿RDMA Socket同样表现不俗。测试结果显示,在 1-3 台服务器测试环境中,柏睿 RDMA Socket 仅需要使用 TCP 以太网 的 1/32 传送包(size)即可达到满 400G 带宽的传输能力;在 6 台服务器测试环境中,柏睿 RDMA Socket 仅需要使用 TCP 以太网的 1/4 线程即可达到满 400G 带宽的传输能力;在一台双向同时收发的情况下,柏睿 RDMA Socket 可以将双向共 800G 带宽跑满,而 TCP 仅能将双向带宽跑到 500G。
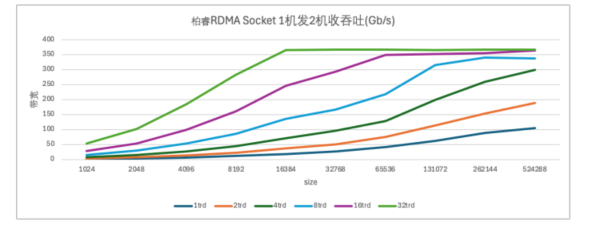
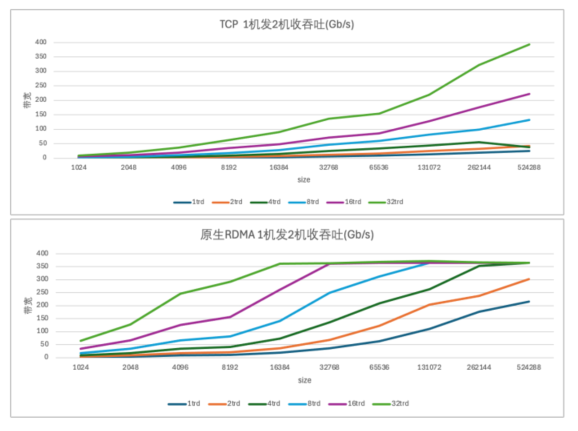
柏睿RDMA Socket在发送较小数据包时也能保持较高的带宽利用率。使用柏睿 RDMA Socket 可以大大提升网络响应速度和带宽传送能力。这对于需要频繁传输小数据包的应用场景来说具有重要意义。
值得一提的是,柏睿RDMA Socket在测试中还展现出了良好的稳定性和可靠性。在长时间高负载的测试环境中,柏睿RDMA Socket能够保持稳定的低时延和高带宽表现,没有出现明显的性能波动或故障情况。这一优势使得柏睿RDMA Socket在构建高性能、高可靠性的大数据和AI应用方面具有广阔的应用前景。
面对英伟达“凭借实力取胜”的回应,柏睿RDMA以低时延、高带宽、稳定性和可靠性等优势证明了自己的高性能实力,为国产替代方案提供了有力支持。650 Group预计,到 2028 年,RDMA 网络市场规模将超过 220 亿美元。未来,随着RDMA技术的不断发展和应用,我们有理由相信,柏睿数据等国产厂商将在全球市场上展现出更加强劲的竞争力和影响力。















