一、关于向量化的介绍
1. 向量化是什么?

首先需要申明的是,这里的“向量化”并不是机器学习领域里的“向量化”,而是特指在大数据计算引擎里的一种技术。
那么这里的向量化(Vectorization)是什么呢?类比于上图中生产化学药剂的流水线,传统做法是每次拿一个空瓶子,做罐装,再盖盖子,送走,然后下一个瓶子;而一个高级版的生产线,每次可以灌装十几个、上百个空瓶子,灌装完成后,并行发送到下一个流水线,然后统一把瓶子盖上,处理速度会大幅提升。大数据计算引擎中的向量化也是类似的,通过硬件上的并行计算,一次性处理多条数据,可以实现非常高效的计算。
2. 列式存储

提到向量化,不得不提到另一个名词叫做:列式存储,指的是数据存储在磁盘上的一种形式。
以上图为例,一个表有 3 个字段,对应到存储就是3列多行。在通常的关系型数据库中,会逐行存储,如图中的 Row layout 所示,第一列是一个整数,第二列是一个字符串,第三列是一个浮点数,按行存储结构交叉混乱。而将数据以列的形式存储,先存第一列,存好之后再存第二列,再存第三列,如图中的 Column layout 所示,就会是一个非常整齐的结构。
列式存储的优势在于:
- 更高的压缩率。结构相近的数据存放在一起,压缩比更高。
- 更高效读取部分数据。通常我们在读某张表的时候,不会一次性读取所有列,而是只会读其中的某几列,如果数据按列式存储,读的实现会更简单,要读哪一列就直接去读那一列即可。
- 更适合向量化计算。在大数据领域,主要的数据格式基本都是列式存储的,如 Parquet、ORC 等都是常用的列式存储格式。
3. 向量化计算

前文中提到,传统计算是基于行的,就像灌装药剂时一瓶一瓶地处理。而向量化计算是基于列的,每次可以把一整列都加载到内存中进行向量计算,性能自然会更优,因此更适合于数据量大、计算复杂度高的场景。
另外一大优势是内存局部性,包括两种:数据局部性和代码局部性。数据局部性如上图所示,在计算的时候连续地访问,现代的 CPU 都会使用一些 Cache,当连续访问时,对 cache 的利用率是非常高的。代码局部性,涉及到计算逻辑,如果是行式计算,会先算第一行的第一个值,第二个值,比如先算一个整数的加法,再算一个字符串操作,再算一个浮点数,那么在代码里面跳转是比较多的。而如果基于列,连续多个加法一起算,算好第一行再算第二行,连续很多个字符串操作,那么在代码里面的跳转也是非常紧凑的。现代的 CPU 在执行代码时也会将代码加载到缓存里面,同样也会存在代码的局部性。在列式计算的场景下,两种局部性都是更优的。
硬件支持,主要是 SIMD 指令、GPU 和 DPU 这些硬件的支持。这些硬件有一个常见的设计,就是希望通过做一些简单的计算来把吞吐量做更大,这一点上,列式计算其实就对现代硬件设计表现得更具亲和性。
4. SIMD 指令(Single Instruction,Multiple Data)

再来讲一下 SIMD 指令。在现代 CPU 上,通过一条指令可以计算多条数据,比如一次算 4 个数的加法,这样比传统指令一次算一条会更快。近 10 年推出的 CPU 基本上都支持 SIMD 指令。
5. 向量化在 SQL 引擎中的使用

将行式计算变为列式计算,在 SQL 里面就是把每次处理一行改成每次处理一个批次,即 Record Batch。一个批次里面可能包含着成千上万的行,并且在内存中是一个列式的组织。计算时,Batch 在 SQL 算子之间传递,可以减少算子调用的开销,每一次调用都可以计算成千上万行。
另外,可以充分利用 SIMD 指令去加速计算,现在流行的 SQL 引擎,如 ClickHouse、Doris、TiDB、DuckDB 等等都已支持向量化计算。
二、Apache Spark 与向量化
1. Apache Spark 介绍

Spark 是目前大数据场景下最常用的分布式数据引擎之一,广泛应用于 ETL、数仓建设、报表分析、机器学习等领域。在快手数据平台上,绝大多数例行作业为 Spark SQL 作业。目前每天例行计算有数十万个 SQL,处理的数据量已经达到 EB 级别,每天计算资源开销会有数百万 CU,年化资源开销超亿元。
2. Apache Spark 工作方式

这里简单介绍一下 Spark SQL 计算的工作方式。首先 SQL 进来会做一些词法语法的处理,然后做一些优化,生成执行计划,其中包括一个个算子,这些算子在执行的时候会最终转化为 Spark 的 RDD 去运行。这里特别标明了 RDD 是基于 Internal Row 的,即行式计算,是没有向量化的。
3. 为什么要研究 Spark+向量化

那么我们为什么要去研究 Spark+向量化呢?刚才讲到 Spark 是基于行的,没有做向量化,所以在计算上的开销非常大,如果能够把向量化技术运用到 Spark 上,就可以获得很大的性能提升和资源上的收益。这里简单做一个 Spark 行式计算和向量化计算的对比:
- 数据读写:因为大数据存储一般都是 Parquet、ORC 等列存的格式,那么向量化计算天然就可以比行式计算减少一次列到行的转换。
- 计算模型:基于火山模型,并使用 WholeStageCodeGen 技术优化,这里不做详细介绍。
- SIMD 特性:向量化对于 SIMD 特性是天然支持的,而行式计算就比较难支持。
- Native 支持:因为 Spark 是用 Java 实现的,是跑在 JVM 上的,如果用向量化技术重新去实现集成层,可以用一些 native 的语言,比如 C++、Rust,这些语言会比 Java 运行速度更快,因此会带来一些性能上的收益。
- 硬件支持:除了 SIMD 之外,也可以用到 GPU、DPU。最近比较火的技术,就是把大数据计算的一些逻辑用硬件实现,那么在向量化下它也是能够更好的支持。
4. Spark + 向量化在行业内的探索

再来介绍一下业内关于 Spark+向量化的一些探索。目前业内的向量化技术解决方案都是通过 Spark 本身的插件机制,把 Spark 算子翻译成用向量化实现的功能等价的算子。
- 业界最先开始相关工作的是 Databricks,他们在 2019 年就开始做 Photon 引擎,目前已商业化。
- 百度近期也公开了一个 Spark native 的引擎,基于 C++,可以把 Spark 算子转成可以 ClickHouse 的算子,目前正在商业化试用阶段。
- 开源领域名气比较大的就是 Gluten,是由英特尔和 Kyligence 主导的,与 Facebook 共建的一个项目。它底层也是 C++,有 Facebook Velox 和 ClickHouse 两个可选的引擎。
- 接下来是快手自研的 Blaze,其底层技术实现采用的是 Rust,是基于 Apache 的 DataFusion 引擎开发的。目前在快手内部处于大规模并开源。
五、Blaze 引擎
1. Blaze 引擎是什么?

接下来介绍 Blaze 引擎。它是快手自研的,基于向量化技术开发的一套 Native 执行引擎,可以充分利用 Native 代码和 SIMD 指令向量化优势,以实现减少资源开销、加速执行的目的。在公司内部已有大规模的应用,对公司降本增效起了很大作用。
简而言之,只要给 Spark 装上 Blaze 引擎,就可以在用户零感知的情况下提升 SQL 的执行效率,并极大地减少 SQL 运行的资源开销。
2. 我们为什么要做 Blaze 引擎?

最初我们做 Blaze 的愿景其实就是降本增效。整个项目于 2021 年底开始调研,2022 年立项开发。当时也是受到经济环境的影响,对降本增效的需求比较迫切。项目需要满足以下几点要求:
- 正确:系统必须保证计算作业的正确执行,计算结果与原生 Spark 一致,这是做数据的底线。
- 高效:系统能够实现较大的性能提升。如果提升的收益太小,连投入的成本都达不到,就没有意义了。这也是为什么我们要做底层向量化,而不是在 Spark 自身做开发的原因了。因为 Spark 本身已经开源很多年了,很难将其性能大幅提升。
- 易用:快手内部运行的 SQL 非常多,如果一个系统需要用户做很多调整,比如改 SQL 或是加一些很复杂的配置,那么即使新系统能带来性能提升,整个项目的成本也会非常高,是难以接受的。因此我们希望这套系统对用户来说是透明的,当加上这一系统之后,SQL 可以跑得更快,用的资源更少,并且是无感知。
为什么没有用已有的开源方案?其实也是与时间点相关,目前做得比较好的开源系统 Gluten,在时间点上与我们的项目是重合的,所以当时并没有现成的开源方案可以借鉴。
3. 项目发展历程

这里简单介绍一下整个项目的发展历程。
第一阶段为“POC 阶段“。我们从 2022 年初开始开发,用了三个月的时间做了第一个 POC,跑通了一个简单 SQL 的用例,验证了我们这套理论的可行性。
第二阶段为“原型版本“阶段。也是用三个月的时间,实现了最常用的一些算子,跑通了 TPC-DS 基准测试的所有用例。
第三阶段为“生产环境可用“阶段。这个阶段持续了近一年,主要工作是持续提升表达式和算子的覆盖度和性能,并且去做一些实际生产环境的适配,比如支持 UDF、内存管理等场景。经过近一年的迭代,跑通了线上大多数作业 SQL,基本达到了生产环境可用的状态。
第四阶段为“线上灰度&开源”阶段。从 2023 年 4 月一直到现在,持续放量,并且通过一个双跑工具来验证结果,以保证改造前后计算结果是一致的。经过双跑之后,加大灰度规模,同时对 bad case 持续迭代优化。最近,我们也开始做 Blaze 项目的开源和社区的建设。
4. Blaze 引擎是如何工作的?

下面介绍 Blaze 引擎的工作原理。上图中展示了原生 Spark SQL 架构,从上往下来看,整个架构可以分成三层: 前端(Spark Catalyst)、后端(Spark Tungsten)和执行层(Spark Core)。
前端主要是负责 SQL 的词法、语法解析优化,然后生成执行计划;后端负责实现执行计划具体的执行逻辑;执行层就是对后端的执行逻辑去做资源的分配调度,使用分布式资源完成计算。
5. Blaze 架构+Spark SQL

Blaze 利用了 Spark 插件机制,在 Spark 原生架构的后端去做改造。当前端把执行计划生成好之后,Blaze 会插入一段翻译逻辑,如果在 Spark 执行计划中的算子能使用 native 向量化算子去做等价替换的话,就去做翻译,把 Spark 算子翻译成我的 native 算子,接着通过一个 native 引擎编译成一个动态链接库,一个 .so 文件打包到 Java 里面去。在执行的时候,它就会把这一套东西发送到执行层,然后使用向量化的逻辑,将翻译后的执行计划执行完成。
6. Blaze 架构之 Native Engine 架构

下面介绍一下 Native 引擎生成的 .so 文件,其中是一些与 Spark 算子相等价的使用向量化计算的算子。对于这些算子,早期我们完全复用了 Apache DataFusion 里面的算子,但后来发现,因为其不是专门面向 Spark 开发的,在某些场景会有局限性,所以重写了这些算子,使其更适用于 Spark 的场景。
除此之外,我们还对一些公共的模块进行了重写,包括内存管理、UDF 框架,以及对外部的 IO,如访问 HDFS、读 Broadcast,与 Shuffle Service 对接等模块。
7. Benchmark

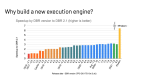
上图中展示了部分测试结果。
目前 Blaze 已经支持了 Spark 3.0-3.5 各版本,均跑通了 TPC-DS 和 TPC-H 测试集。我们专门针对 TPC-H 做了一些优化,比如强制使用 Hash Join。第一个图就是使用了针对性优化的测试结果,相比 Spark3.3,性能提升了近 300%。这种为了测试 Benchmark 而进行的调优,其实对生产的意义并不大,得出来的结果也只是为了跟同类产品做比较。
第二个图是在实际生产环境上测试的 Benchmark。我们去掉了定制的优化,完全使用真实的生产参数。在这个环境下再和原生 Spark3.5 做对比,测试结果显示,执行效率提升了 220%,同时资源开销也下降了一半以上。
四、从 Benchmark 到实战 Blaze 落地生产环境的挑战
1. Benchmark 与生产环境的区别

在这一章节中将介绍 Blaze 是如何落地到快手生产环境中的。首先需要再次指出,尽管我们很早就跑通了 TPC-DS、TPC-H 这些测试集,但是要从 Benchmark 应用到生产环境,其实还有很多工作要做。
- 输入数据方面:在生产环境中,我们会面临各种复杂的数据类型,并且文件格式也可能是 parquet 的各种版本,甚至会包含一些异常数据。
- 计算逻辑方面:用户写的 SQL 各种各样,可能有成千上万行,还会包括一些 UDF。
- 配置方面:快手的数据平台允许用户自定义配置,内存大小不一,可能有多种 Spark 参数。
- 执行环境方面:我们使用的 Hadoop 是内部修改过的,一些 Shuffle Service 也是内部自己开发的,没有直接使用开源的。
- 上线要求方面:上线到生产环境需要保证数据完全一致,并且对用户无感知。
接下来,将介绍我们为生产环境做的一些开发和优化。
2. 适应非标准环境的存储系统

快手使用的 HDFS 是经过内部改造的,对一些开源的客户端是不适用的,比如说现在 native 实践在访问 HDFS 的时候,使用的都是 libhdfs3 库,但是在快手内部,因为我们是修改过的,这个库没办法直接去用。所以为了解决这个问题以及方便后期适配更多的文件系统,我们把访问 IO 改成了直接使用 JNI。这样就可以完全兼容 Spark 支持的所有存储系统,并且这些关于存储系统的配置在以后可以直接复用。如此对生产环境的适用就更加泛化了。
3. 支持用户 UDF、细粒度回退

第二个优化是对用户 UDF 的支持。因为 Spark 的 UDF 是用 Java 写的,没有办法走 native 执行。主流的向量化引擎,像 Photon 或者 Gluten 都需要对算子去做回退,也就是当算子里面有不支持的表达式,这个算子无法翻译到 native 去执行时,就需要把这个算子放回 Spark 去执行。这里的回退就会涉及到一个列转行的操作,因为我们的数据在向量化这边是列式存储,到了 Spark 里面要转成行才能去计算,而列转行的开销是非常大的,如果线上用的 UDF 比较多,就会有频繁的列转行,那么优化效果就没有了,甚至可能就退化了。
所以我们做了一个优化,尽量把回退的力度做到最小。比如查 100 个字段,有 1 个 UDF 计算,那么只回退 UDF 的参数,将参数转回到 Spark,在 Spark 把 UDF 算好,再把结果转成列,传到 native 去参与后续的计算,这样就可以使行列互转的粒度最小。比如一些 UDF 只有一个参数,那么我们甚至不用做列转行,直接把这个参数通过 FFI,甚至不需要内存拷贝,直接放回到 Spark 去计算。这样就能够支持很多线上 UDF 的场景。
4. 小内存场景

再来讲一下对小内存的支持。
在快手内部,默认的 Spark SQL 作业的内存配置是比较小的,可能每个 Execute 上就只有几 GB 的内存,并且在 native 代码里面,由于 JVM 的限制,它只能直接运行在堆外内存,是一个特别小的内存。为了在这种小内存的场景下也能够用起来,尽量减少用户去改配置的成本,我们提供了对小内存的支持,做了一个多级的内存管理。
因为我们知道 Spark 在计算一些如排序聚合这样的算子的时候,它需要把这个数据暂存到内存,这种算子是特别吃内存的。针对这个问题,我们做了一个多级的 Spill 管理。当数据占满了堆外内存之后,不是直接去做磁盘溢写,而是先去检查堆内内存是不是还有空间。因为 native 是跑在堆外内存,一般堆内内存它是比较空闲的。我们尝试把数据做一个轻量的压缩,然后暂存到堆内内存,这样可以把 Spark 堆外堆内内存都充分地利用起来,最终的效果就是即使用户默认的内存配置很小,即便不修改内存配置,也能够有一个很好的优化效果。因为我们 native 的代码是用 C++ 和 Rust 来实现的,它用的内存可能比 JVM 要小,甚至在小内存下可能跑的比 Spark 默认还要更稳定。
5. 针对性优化:JSON 解析场景

下面要介绍的是对 JSON 解析的优化。
在使用 Spark 做 ET L的时候,经常会碰到这样的场景:有一个特别大的 JSON 字段,需要从字段里面去解析出几十个 key 出来。这种场景在快手有很多,在这种场景下 Spark 的实现效率比较低,每次解析一个 key,都需要去把字段的 JSON 重新 parse 一下。这里做了一个简单的 Benchmark,就是解析 1 个字段到解析 5 个字段,可以看到蓝色的是 Spark3.5,其开销增长基本上是线性的。
在 Blaze 里面,我们专门针对这种场景进行了优化。在计算的时候,去识别每个表达式是不是有公共的部分,我们发现解析 JSON 时,它解析的某一部分其实是可以公共的。解析同一个字段,可以取多个 key 的值,这样就能够减少重复解析字段的成本,图中橙色柱状是 Blaze 的开销,可以看到,在做了对重复解析的优化之后,不管解析几个字段,其开销基本上持平的,不再是线性增长的情况。
6. 灰度方案

下面介绍一下 Blaze 系统的上线过程,也就是我们的灰度方案。由于数据正确性是底线,所以我们开始上线的时候,需要去做严格的双跑对比来确保数据是准确的。具体来说,我们会选取用户的单个时间分区内的一个 SQL,然后将其写表这部分逻辑去掉,替换成一个校验逻辑,会对每条数据算一个哈希值,然后做一个求和,然后把数据的条数和其哈希值都存下来。同样的数据,用 Spark 跑一次,用 Blaze 跑一次,将结果进行严格的一致性对比,并且还要检验性能,保证在 Blaze 里的执行性能优于 Spark,同时资源开销更小。只有这些完全通过后,才会真正上线。这就是我们早期的初步灰度方案。
后来,随着 Bad Case 不断修复,我们对整个系统更加有信心,并且我们希望加快整体进度,所以后面到了大规模上线阶段,我们会引入几个指标,首先判断一个作业是否是核心作业,并对其复杂程度做一个标识。如果一个作业不是核心作业,并且比较简单,我们就考虑将严格双跑改成抽样双跑,可能用户的每个分区每个表只取其中的一个小文件,用以对比计算的正确性,对于性能可以不做考虑,只要满足抽样通过,就可以直接上线。
当然,对于核心作业或者是逻辑较为复杂的作业,还是要通过严格对比才能上线。
7. 上线效果与最终目标

下面从几个方面来分享上线效果。
- 在资源使用方面,因为快手内部资源比较紧张,所以作业的执行时间波动会比较大,这里我们主要考虑资源开销。目前 Blaze 引擎在快手已覆盖近一半的例行作业,每天使用的资源开销占据整个集群总量的 30%(这里可以看到一些优化的效果,本来这部分作业占的资源达到了 40-50%,切换到 Blaze 之后,开销下降到了 30%)。
- 上线作业 native 算子占比达到了 93%,剩下尚未实现的部分,一个是 UDAF 用户自定义的聚合函数,这块目前还在调研中,还没有找到一个很好的办法去做比如单 UDAF 的回退,另外还有一些用户自定义的窗口函数还没有支持到,可能还有少部分的算子是要回退的。
- 资源开销方面,我们将上线前 7 天和上线后 7 天的平均资源开销进行了对比,平均降低 30%,比如上线前可能要跑 10 分钟,上线后仅需 7 分钟,那么资源开销就能够下降 30%。节约的资源开销折算的年化收益已达到数千万。
我们最终的目标就是希望快手数据平台的所有 SQL 作业都默认打开 Blaze。
五、Blaze 开源计划
1. 为什么要将 Blaze 开源?

我们希望通过开源社区能够让 Blaze 项目有更长远的发展。所以我们最近也在做开源社区的建设,希望借助社区力量,一起把 Blaze 引擎优化效果用起来,同时进一步提升我们的影响力和技术水平。
2. 当前进展

这里是目前我们在社区取得的一些进展:
- 首先整个项目的构建,在经过社区很多同学的优化之后,已经逐渐健壮起来。目前项目的构建过程也变得相当简单,只要在 GitHub 上提交了代码,它就会在 GitHub 上直接编译出一个可用的包,并且可以在 GitHub 上去跑一个小规模的 TPC-DS 验证。整个编译是非常简单的,欢迎大家试用。
- 另外,对 Spark 多版本提供了支持。目前已覆盖 Spark 3.0~3.5 版本。
- 第三是对 ORC 格式的支持。因为快手内部用的都是 Parquet,原本对 ORC 是没有支持的,经过社区的运营,有热心的同学加上了对 ORC 的支持。
- 最后是我们与阿里的合作,对 Apache Celeborn 提供了支持。Celeborn 是阿里研发的一个 Shuffle Service 服务,也是由阿里那边去做开发,完成了 Blaze 对 Celeborn 的支持。
- 当前社区项目已经有 1.3k star,有多家公司试用并取得预期收益。
3. 未来规划

未来主要工作包括以下几个方向:
- 首先,我们的科研重点还是 Blaze 的生态圈。比较紧迫的是数据湖方面,会考虑对 Hudi 或者 Iceberg 这些数据湖引擎的支持。在 Shuffle Service 方面,我们已经支持了阿里的 Celeborn,后续也会提供对腾讯 Uniffle 的支持。目前也在调研,是否能够把我们的 native 引擎集成到 Flink 上去。
- 第二块是多版本的支持。现在 Spark 4 即将推出,我们会保持对 Spark 版本的跟进。
- 第三是性能优化,这始终是最核心的工作。
- 最后是提升项目的社区影响力,我们也有计划把整个项目加到 Apache 中去,目前正在推进中。

Github地址:https://github.com/kwai/blaze
以上是 Blaze 项目的开源地址,欢迎大家关注并试用(点击阅读原文可直接跳转),也欢迎大家加入我们的技术交流群,谢谢大家!
六、Q&A
Q1:前面讲到的采样和双跑,是要对 SQL 进行改造,还是 Blaze 自带的功能?
A1:这个是我们做在 Spark 里面的一个功能,在读表的时候,表里面可能有很多文件,但我们采样只用读一个就行,目的是验证它执行的逻辑是否正确,如果正确就不用去读全表。对性能也是有信心的,所以采样时就不用管。这块对于 SQL 的改造是 Blaze 自带的。
Q2:灰度测试以及后面的引擎切换是需要手动切换吗?
A2:这块切换是完全在引擎上去做的,只需要改一下参数配置。这块对于用户来说是不可见的,用户关注的只是我们执行的效率和结果。当然我们会做一些对用户的通知,告知作业已切换到 Blaze。
Q3:分享中提到,相比原生的 Spark3.3 和 Spark3.5 的速度,两次 Benchmark 分别提升 300% 和 220%,速度提升意味着它的时效也会提升,对吧?比如计算时间缩短,只要原来的 1/3 了?
A3:是的。如果在资源的配置不变的条件下,那么假设原来执行 10 分钟,那么切换到 Blaze 之后,执行可能就只要 5 分钟了,这里就会有一个时效性的提升,资源开销就下降了一半。
Q4:切换到 Blaze 是有一个开关一样的配置是吧?那什么样的任务才能去切换,比如基于什么样的规则,还是通过人工去筛选?
A4:目前在我们大规模灰度测试的话,其实依据是我们对于历史任务的一个分析。例如我们在记录例行任务的时候会加上一些标识信息,就可以知道它的任务的核心程度、核心等级和复杂程度和它的子算子等信息。通过这些信息,我们可以去判断测试用例是否需要双跑,方式是采样还是全量,然后分别去做这些验证,最后在我们引擎这边把它的作业加到灰度,这些对于用户其实也还是没有感知的。
Q5:如果大规模的任务做了灰度切换之后,怎么去保障它的计算结果是准确的?有没有好的方法去验证?
A5:首先刚才讲到,我们在切换之前有一个双跑,如果双跑通过,那么我们就认为其没有问题了。当然也有过比较极端的 case,特别是 JSON 解析这一块,因为我们用的是不同的解析库,它其实会有一些问题,比如有些不规范的 JSON,里面有一些特殊字符,例如有一些表情包之类在里面,我们已经踩过了很多坑,所以现在有充足的信心,如果双跑通过,就能够保证后面的数据是对的。
Q6:介绍中提到的都是 Spark SQL 的一些案例迁移到Blaze引擎去执行。如果是用 Java 或 Scala 写的那种算子,就是 Jar 包类型的任务,或者是通过 PySpark 去实现的任务,也能应用到这个引擎吗?
A6:目前可以对纯 SQL 任务或者 Spark Jar、PySpark 任务中的 SQL 部分做优化,我们还是对 SQL 生成的算子支持的比较好,因为 SQL 是一些比较标准逻辑的,我们只要去遵守标准即可。但如果是用户自己实现的一些 RDD 的操作,这块目前还是做不到。
Q7:在 Spark 切换的时候,Spark 用户经常有很多 UDF 代码,这些代码基本上是按行的形式去存储的,这种情况下很容易打断向量化执行,是否有一些手段让用户的这些 UDF 自动转成向量式的处理?
A7:我们针对一些常用的 UDF 比如 Brickhouse 系列的 UDF 做了一个在 native 的实现,像这部分是可以直接用 native 去执行的。这块因为目前我们暂时还没有一个 native 的 UDF 框架,如果需要,可以去改 Blaze 的代码去编译,后续我们会考虑加一个 native 的 UDF 框架。例如刚才问到的,怎么样把 Java 的 UDF 转成 native,其实目前 ChatGPT 可以做这个事情,我们也试过,还是效果比较好的。