在分布式系统中,事务处理一直是一个复杂的话题。想象一下,当你在网上商城购物时,整个过程涉及:
- 订单系统创建订单
- 库存系统扣减库存
- 支付系统完成支付
- 积分系统增加积分
这些操作分布在不同的服务中,如何保证它们要么全部成功,要么全部失败?这就是分布式事务需要解决的问题。

一、分布式事务的挑战
1.传统事务的局限
在单体应用中,我们习惯使用数据库的 ACID 事务:
但在分布式环境下,这种方式行不通了,因为:
- 跨多个数据库
- 跨多个服务
- 网络可能失败
- 服务可能宕机
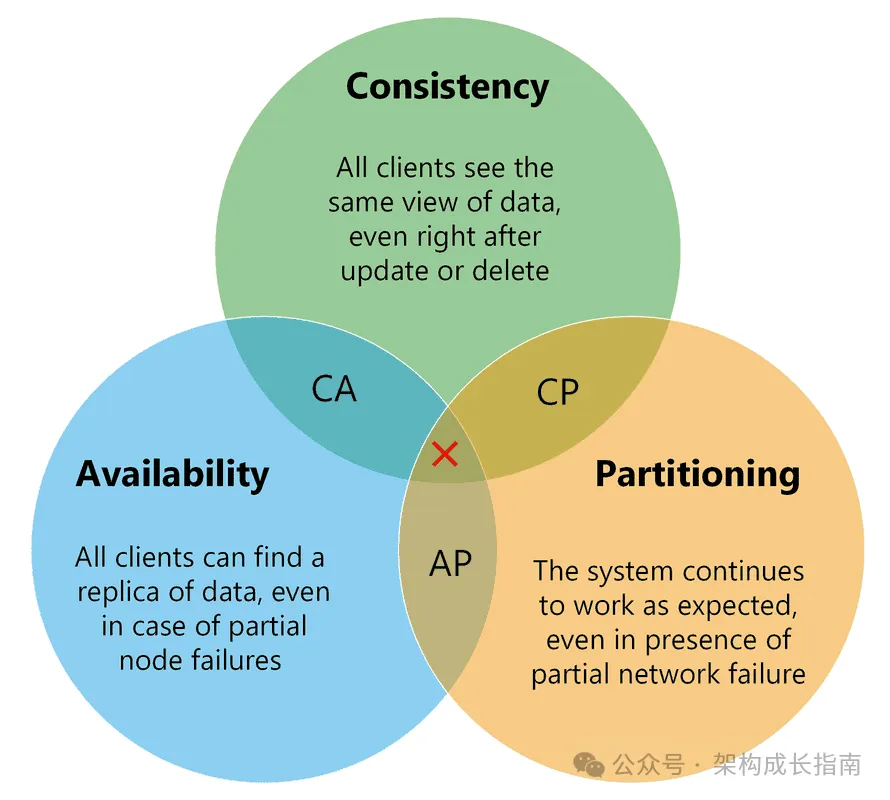
2.CAP 理论的限制
在分布式系统中,我们不得不在以下三个特性中做出选择:
- 一致性(Consistency)
- 可用性(Availability)
- 分区容错性(Partition tolerance)
二、TCC 模式介绍
1.什么是 TCC?
TCC(Try-Confirm-Cancel)是一种补偿性事务模式,它将一个完整的业务操作分为二步完成:
(1) Try: 尝试执行业务
- 完成所有业务检查
- 预留必要的业务资源
(2) Confirm: 确认执行业务
- 真正执行业务
- 不做任何业务检查
- 只使用 Try 阶段预留的资源
(3) Cancel: 取消执行业务
- 释放 Try 阶段预留的资源
- 回滚操作
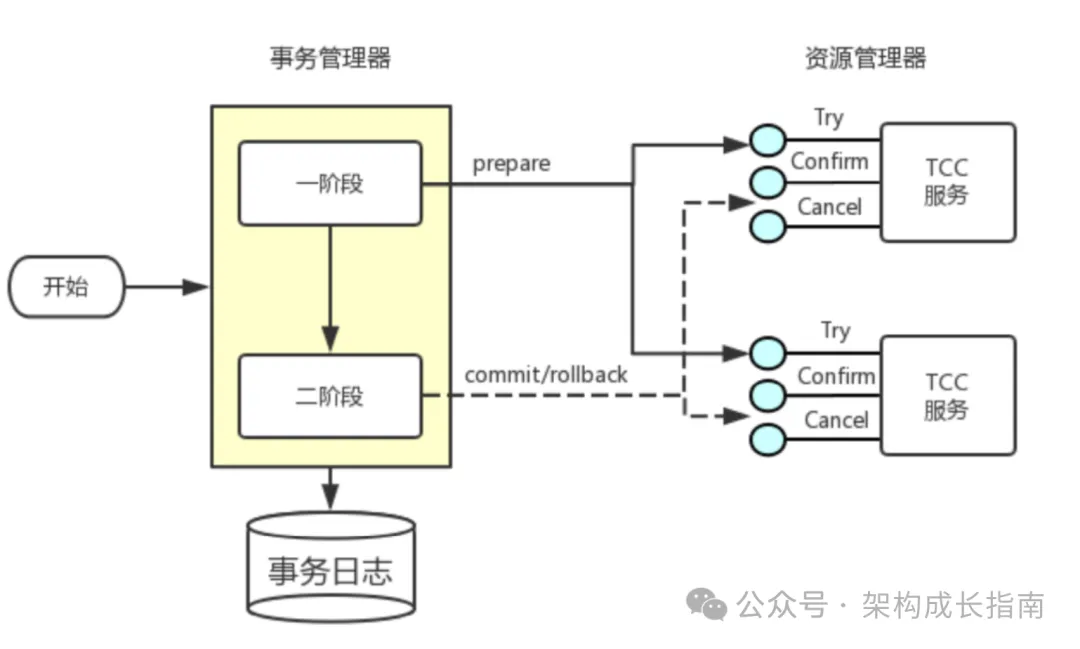
来源:seata
2.TCC 示例:订单支付流程
让我们通过一个具体的订单支付场景来理解 TCC:
3.TCC 事务协调器
为了协调整个 TCC 流程,我们需要一个事务协调器:
三、TCC 实现要点
1. 业务模型设计
在实现 TCC 时,业务模型需要考虑预留资源的状态:
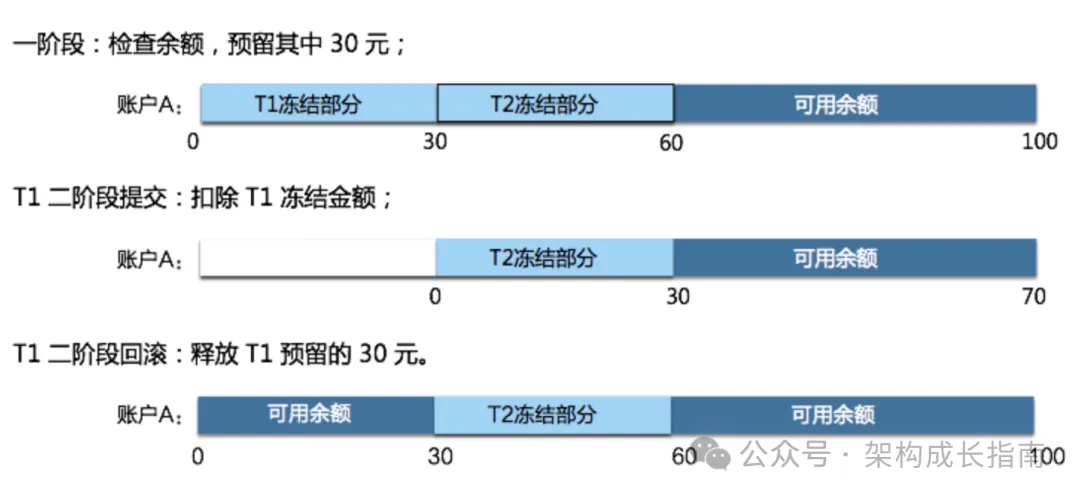
图 3: TCC 中的资源状态变化,来源 seata
2. 幂等性设计
所有操作都需要保证幂等,因为在网络异常时可能会重试:
3. 防悬挂设计
(1) 为什么需要防悬挂?
在分布式系统中,网络延迟、服务故障等原因可能导致一个奇怪的现象,Cancel 操作比 Try 操作先执行。这就是所谓的"悬挂"问题。具体场景如下:
事务管理器在调用 TCC 服务的一阶段 Try 操作时事务时,由于网络拥堵,Try 请求没有及时到达,事务管理器超时后,发起了 Cancel 请求完成后,此时原来的 Try 请求才到达,如果在执行这个延迟的 Try 请求,将导致资源被错误锁定
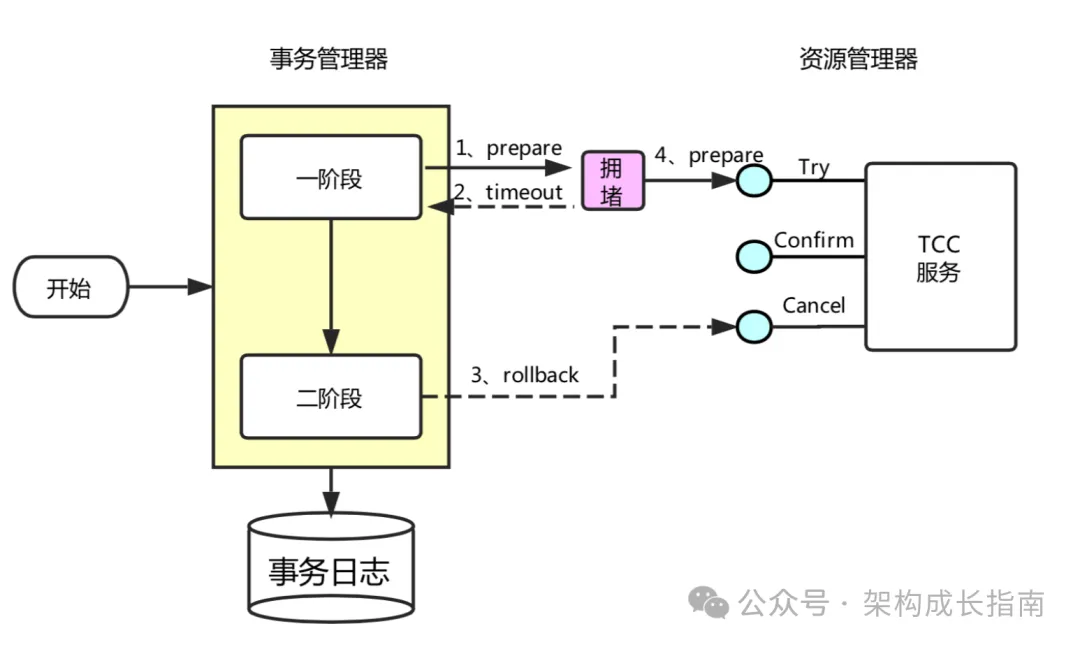
*图: TCC 悬挂问题示意图,来源:seata
(2) 解决方案
核心思路是记录每个事务的执行状态,并在执行 Try 操作前进行检查:
4. 超时处理
(1) 为什么需要超时处理?
在分布式环境下,超时是不可避免的,可能由于以下原因导致:
- 网络延迟或故障
- 服务器负载过高
- 服务进程崩溃
- 死锁
如果不处理超时,会造成严重后果:
- 资源被无限期锁定
- 事务无法正常结束
- 系统可用性降低
- 用户体验变差
(2) 超时处理机制
定时扫描超时事务:
超时配置管理:
监控和告警:
(3) 最佳实践
超时时间设置:
- 根据业务特点设置合理的超时时间
- 考虑网络延迟和服务响应时间
- 为复杂业务预留足够的处理时间
- 不同类型的事务可以设置不同的超时时间
重试机制:
- 实现指数退避算法
- 设置最大重试次数
- 合理的重试间隔
- 重试时要考虑幂等性
监控和告警:
- 监控超时事务数量
- 监控 Cancel 操作的成功率
- 监控资源占用情况
- 设置合理的告警阈值
人工干预:
- 提供管理后台
- 支持手动触发 Cancel
- 提供事务状态查询
- 记录详细的操作日志
通过这些机制的组合,我们可以构建一个健壮的 TCC 事务处理系统,能够:
- 及时发现并处理超时事务
- 防止资源被长期锁定
- 提供完善的监控和运维能力
- 在出现问题时及时告警并支持人工介入
四、最佳实践
资源预留:
- Try 阶段要预留足够的资源
- 预留资源要考虑并发情况
- 预留时间要合理设置
状态机制:
- 明确定义每个阶段的状态
- 状态转换要有清晰的规则
- 保存状态转换历史
异常处理:
- 所有异常都要有补偿措施
- 补偿操作要能重试
- 重试策略要合理设置
监控告警:
- 监控每个阶段的执行情况
- 设置合理的告警阈值
- 提供人工干预的接口
五、适用场景
TCC 模式适合:
- 强一致性要求高的业务
- 实时性要求高的场景
- 有资源锁定需求的操作
不适合:
- 业务逻辑简单的场景
- 对性能要求特别高的场景
- 补偿成本过高的业务
六、结论
TCC 是一种强大的分布式事务解决方案,它通过巧妙的补偿机制来保证事务的一致性。虽然实现较为复杂,但在某些场景下是不可替代的选择。
关键是要:
- 理解业务场景
- 合理设计补偿逻辑
- 做好异常处理
- 重视监控告警
通过合理使用 TCC 模式,我们可以在分布式系统中实现可靠的事务处理。