写在前面 & 笔者的个人理解
在过去的几十年里,自动驾驶算法在感知、规划和控制方面取得了重大进展。然而,评估单个组件并不能完全反映整个系统的性能,这突显了对更全面评估方法的需求。这推动了HUGSIM的发展,这是一个闭环、真实和实时的仿真器,用于评估自动驾驶算法。我们通过3DGS将捕获的2D RGB图像提升到3D空间,提高闭环场景的渲染质量,并构建闭环环境来实现这一目标。在渲染方面,我们解决了闭环场景中新视图合成的挑战,包括视点外推和360度车辆渲染。除了新视图合成外,HUGSIM还实现了全闭环仿真循环,根据控制命令动态更新自车和行为者状态和观察结果。此外,HUGSIM为KITTI-360、Waymo、nuScenes和PandaSet的70多个序列以及400多个不同的场景提供了全面的基准,为现有的自动驾驶算法提供了一个公平和现实的评估平台。HUGSIM不仅是一个直观的评估基准,还释放了在真实的闭环环境中微调自动驾驶算法的潜力。

总结来说,本文的主要贡献如下:
- 全新自动驾驶仿真器,其特点是闭环、真实和实时,弥合了城市场景新视图合成和自动驾驶仿真器之间的差距。
- 为了解决仿真器中的特定渲染挑战,我们利用物理约束和非本地参与者来提高保真度,超越了以前的新视图合成方法。
- 提出了一种高效的驾驶员轨迹生成策略,即使没有高清地图,也能仿真攻击性驾驶行为。
- 引入了一个新的基准来公平评估AD算法,与现有的基于闭环视觉的AD仿真器相比,它提供了更真实的仿真环境。此外,基准测试提供了基于多个数据集的各种场景,具有不同难度的不同场景。
相关工作回顾
Urban Scene Reconstruction
静态场景:已经进行了许多研究,使用各种方法重建城市场景。这些方法可分为四类:基于点的、基于网格的、基于NeRF的和基于3DGS的。虽然基于点和基于网格的方法展示了真实的重建,但它们很难恢复场景的各个方面,特别是在高质量的外观建模方面。相比之下,基于NeRF的模型不仅可以重建场景外观,还可以从新颖的视角进行高质量的渲染,而基于3DGS的模型则支持实时渲染而不会牺牲质量。然而,这些方法主要是为静态场景设计的,缺乏处理动态城市环境的能力。在这项研究中,我们的重点在于应对动态城市场景的挑战。
动态场景:还开发了几种方法来解决动态城市场景的重建问题。其中许多方法依赖于移动目标的精确3D边界框的可用性,以便将动态元素与静态组件分开。PNF、NeuRAD和StreetGaussians采用了一种不同的方法,利用基于单目或基于激光雷达的3D边界框预测,并在重建过程中提出了对物体姿态的联合优化。然而,我们的实验观察表明,由于没有物理约束,直接优化物体姿态会产生不令人满意的结果。另一种方法SUDS通过基于学习到的特征场对场景进行分组,避免了使用3D边界框。然而,这种方法的准确性滞后。同时,EmerNeRF和PVG遵循与SUDS类似的想法,将场景纯粹分解为静态和动态组件。在我们的研究中,我们有能力进一步分解场景中的单个动态目标并估计它们的运动。然后,该重建的运动可用于在仿真器内仿真驾驶行为。
外推视图渲染:尽管上述城市重建方法可以在插值视图中渲染高保真图像,但大多数方法都难以在外推视图中渲染,尤其是在车道上,伪影很常见。一些方法,利用扩散模型添加额外的视图进行监督,解决了城市场景重建中输入视图稀疏的问题。然而,扩散模型带来了挑战,例如视图之间的不一致性、训练复杂性的增加以及由于这些模型的繁重计算负担而导致的训练速度减慢。GGS提出了一种基于MVSplat的可推广模型,在训练过程中结合了虚拟车道生成策略来解决外推视图问题。虽然这种方法显著提高了外推视图的保真度,但MVSplat只允许少数帧作为输入,这可能会限制可扩展性并导致多视图错位。相比之下,并行工作AutoPlat和RoGS应用物理先验来约束地面高斯分布,类似于我们的方法。然而,AutoPlat依赖于LiDAR数据进行初始化,RoGS在地平面上均匀分布高斯分布,两种方法都固定高斯在平面上的位置。这些方法使用大量的高斯分布来对非纹理区域进行建模,我们发现这是不必要的,也是低效的。通过优化位置和比例等附加参数,HUGSIM在不需要太多高斯分布的情况下实现了更好的性能。
上述相关工作主要集中在新颖的视图合成上,但还没有完全开发出闭环仿真器,如表1所示。

Benchmarks
开环:AD算法的大多数现有数据集和基准都遵循开环方法,分别评估算法的各个组件。例如,在感知组件中,评估语义分割、边界框检测和车道检测等任务,而规划组件评估路线规划、行为预测和轨迹预测等任务。尽管这些开环基准提供了对每个部分的详细和令人信服的性能评估,但它们使用专家收集的感官数据来评估AD算法的性能,缺乏偏离专家收集的感知数据的场景。如果没有闭环反馈,这些偏差的长期后果仍未得到探索,这对于理解AD系统在现实世界条件下的鲁棒性和安全性至关重要。NAVSIM提供了一个位于开环和闭环评估之间的基准。尽管它是一个非反应式仿真器,缺乏新颖的视图合成能力,但它通过预测未来几秒钟的规划轨迹来计算闭环指标。然而,NAVSIM仅限于短时间范围,并没有解决随着时间的推移累积的偏差如何影响驾驶安全的问题。
闭环:许多闭环仿真器试图解决自动驾驶中开环基准的局限性。一些仿真器提供了其他车辆的地面真实位置和旋转,缺乏AD系统的感知方面,这对全面评估至关重要。视频扩散模型的快速发展在生成真实的驾驶视频方面显示出了希望。DriveArena使用视频扩散模型构建闭环仿真器,通过场景布局控制场景生成。然而,这些模型仍然存在时间不一致和大量计算需求等问题。UniSim和NeuroNcap采用了不同的方法,创建了一个基于NeRF的仿真器,可以实现真实的闭环仿真。然而,UniSim不是开源作品,而NeuroNCAP有几个缺点,包括非实时渲染、外推视图的次优质量和完全手动的演员行为设计。相比之下,HUGSIM通过提供实时性能、提高外推视图的保真度以及高效、自动生成参与者行为来解决这些挑战。
城市场景重建
解耦场景表示
我们假设场景由静态区域和表现出刚性运动的动态车辆组成。静态区域被分解为地面和非地面区域,允许对地面应用平面约束,以在外推视图中保留车道结构。我们考虑两类动态车辆:原始驾驶数据集中存在的本地动态车辆和从360度捕获图像重建的非本地动态车辆。
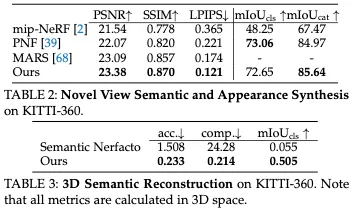
非地面静态高斯:遵循3DGS,我们使用3D高斯对城市场景的所有区域进行建模。除了3D高斯的原始定义外,我们还建议对每个3D高斯的语义logit 进行额外建模,以允许渲染2D语义标签。此外,我们可以通过在两个不同的时间戳t1和t2将3D位置μ投影到图像空间并计算运动,自然地获得每个3D高斯的渲染光流。我们提供了多模态渲染的详细信息。

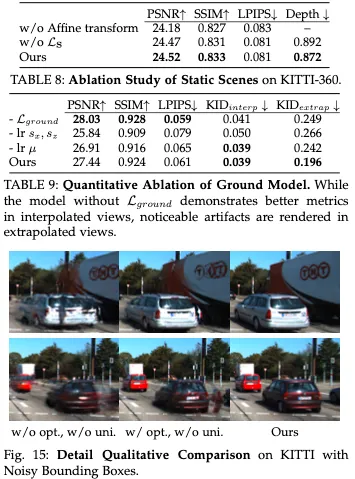
地面高斯:车道在AD算法的感知中起着至关重要的作用。然而,如图3所示,大多数现有的重建方法都难以在外推视图中准确渲染车道几何形状。这些失真的原因是地面高斯分布倾向于过度拟合训练视图,无法重建正确的地面几何。我们的初步实验表明,直接监督渲染深度并不能解决问题,因为具有不正确几何形状的高斯人仍然可以渲染出看起来准确的2D深度图。此外,我们正则化地面高斯分布以形成平面结构,得到如图4所示的正确几何。

一个天真的假设是将场景的地面视为一个单一的平面,允许地面高斯分布在相同的高度。然而,这一假设忽略了更复杂的情况,如斜坡道路。为了解决这个问题,我们提出了一个多平面地面模型,其中我们假设地面仅在有限的距离内是平面的,记为∆Z。在该模型中,假设每个局部平面相对于最近的相机具有固定的高度。由于相机姿态反映了表面坡度,这种多平面方法有效地仿真了这种复杂的场景。具体来说,我们优化了地面高斯分布,并通过将采样高斯补丁的高度方差限制在相应相机坐标系中的小∆Z内来约束高斯分布在3D空间中。请注意,局部平面彼此重叠,从而避免了边界伪影。更正式地说,我们的地面模型的约束可以表示为优化目标:

与之前使用密集拼接或LiDAR初始化高斯的方法不同,如RoGS和AutoPlat所示,我们发现使用稀疏分布的高斯可以有效地表示地面,因为地面纹理不是均匀分布的。因此我们保留了颜色、位置、不透明度、二维尺度作为可优化参数,同时也纳入了密度控制策略。我们的方法能够实现高质量的地面渲染,而不需要过多的3D高斯分布,正如我们的实验所证明的那样。
本地动态车辆高斯模型和单循环模型:对于动态车辆,我们假设根据输入的RGB图像预测3D边界框,从而在目标坐标空间中实现3D高斯建模。为了解决预测中的噪声问题,我们通过使用自行车模型进行正则化来共同优化它们。

非本地全观测车辆高斯模型:AD仿真器需要从所有360度渲染高保真度的参与者,特别是在将交互式参与者集成到闭环仿真中时。然而原始重建场景中的车辆仅从有限的一组视点捕获,从训练视角之外的角度观察时会产生明显的伪影。为了解决这个问题,我们使用密集捕获的真实世界数据集3DRealCar重建车辆,该数据集提供了对真实世界车辆的360度观测。我们的实验表明,当以随机视角插入仿真场景时,真实世界捕获的车辆表现优于原始场景中的车辆。

3DRealCar数据集提供了车辆的掩码。我们利用掩码信息来确保3D高斯模型仅对汽车前景进行建模。这是通过在香草渲染损失之外考虑阿尔法掩模损失来实现的。重要的是,直接插入没有阴影的前景车辆通常看起来就像它们漂浮在空中。然而,逆渲染需要精确的环境地图,这很难从透视相机中获得。尽管一些工作解决了高斯散斑中逆渲染的挑战,但它仍然是一个计算成本很高的操作。为了简化问题,我们假设光源(太阳)直接在头顶,这意味着阴影应该出现在车辆下方。为了渲染车辆阴影,我们将平面高斯分布图放置在规范空间中车辆的底部,如图5所示。这些高斯分布的α属性根据它们与底部中心的距离平滑地减小。尽管这是一个简化的假设,但我们观察到,在许多情况下,插入的非本地车辆似乎是合理的,在效率和照片真实感之间取得了良好的平衡。
整体城市高斯分布

Semantic Reconstruction:

Optical Flow:



Loss Functions
图像损失:

2D分割损失:

基于物理的正则化:




仿真
Graphicial Configuration Interface
我们开发了一个图形用户界面(GUI),以方便在仿真器中配置测试场景。GUI配置包括几个步骤。第一步是配置相机设置,包括相机数量、相机内参和车辆外参。第二步是配置自车参数,包括指定自车的运动学模型、控制频率和启动状态。最后一步涉及配置参与者,包括具有不同指定行为的本地和非本地车辆。所有这些演员的外观都可以从3DRealCar重建的100多辆候选3D车辆中选择。
闭环仿真
- Simulator-User communication
- Controller
- Ego-Vehicle Kinematic Model
- Collision Detection
Actor Driving Behaviors
- Replayed Driving Behavior
- Normal Driving Behavior
- Aggressive Driving Behavior

渲染评测











结论
本文介绍了HUGSIM,这是一种用于自动驾驶的全新真实闭环仿真器,具有在外推视图中实时、高质量渲染和高效生成演员行为的特点。具体来说,我们使用3D高斯重建城市场景,并引入地面模型以及单车辆重建,以提高外推视图的渲染质量。对于参与者行为,我们提出了一种基于攻击成本的轨迹交互式搜索,以仿真参与者的攻击性驾驶行为。
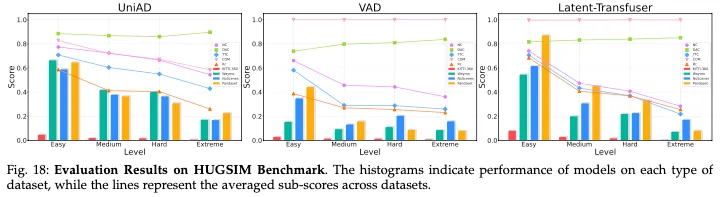
此外,我们在包括方差序列在内的多个数据集上建立了HUGSIM基准,设计了300多个用于评估和训练AD算法的场景。我们在基准上评估了几个基线。我们的结果表明,HUGSIM基准对现有的AD算法提出了重大挑战。这一闭环基准测试揭示了自动驾驶性能的巨大改进空间。我们希望我们的数据集和基准将促进跨社区的新研究,推动实现完全自主的最终目标。
对于未来的工作,HUGSIM可以通过多种方式进行增强。首先,我们假设所有动态目标都遵循刚性运动,这可能会导致行人等非刚性运动目标的模糊。这可以通过将非刚性动态重建方法纳入我们的框架来解决。虽然我们的方法改进了外推视点的渲染,但它在远离输入或非常接近目标的视图上难以实现高保真渲染。这些挑战可以通过利用2D生成模型的先验来缓解。此外,由于我们的方法为在真实的闭环环境中微调AD算法开辟了可能性,这为未来的探索提供了一条有前景的途径。