作者 | frostchen

导语
Linux下开发者习惯在物理机或者虚拟机环境下使用top和free等命令查看机器和进程的内存使用量,近年来越来越多的应用服务完成了微服务容器化改造,过去查看、监控和定位内存使用量的方法似乎时常不太奏效。如果你的应用程序刚刚迁移到K8s中,经常被诸如以下问题所困扰:容器的内存使用率为啥总是接近99%?malloc/free配对没问题,内存使用量却一直上涨?内存使用量超过了限制量却没有被OOM Kill? 登录容器执行top,free看到的输出和平台监控视图完全对不上?... 本文假设读者熟悉Linux环境,拥有常见后端开发语言(C/C++ /Go/Java等)使用经验,希望后面的内容能在读者面临此类疑惑时提供一些有效思路。
K8s中监控数据主要来源是 cadvisor, 容器内存使用量的相关指标有以下:
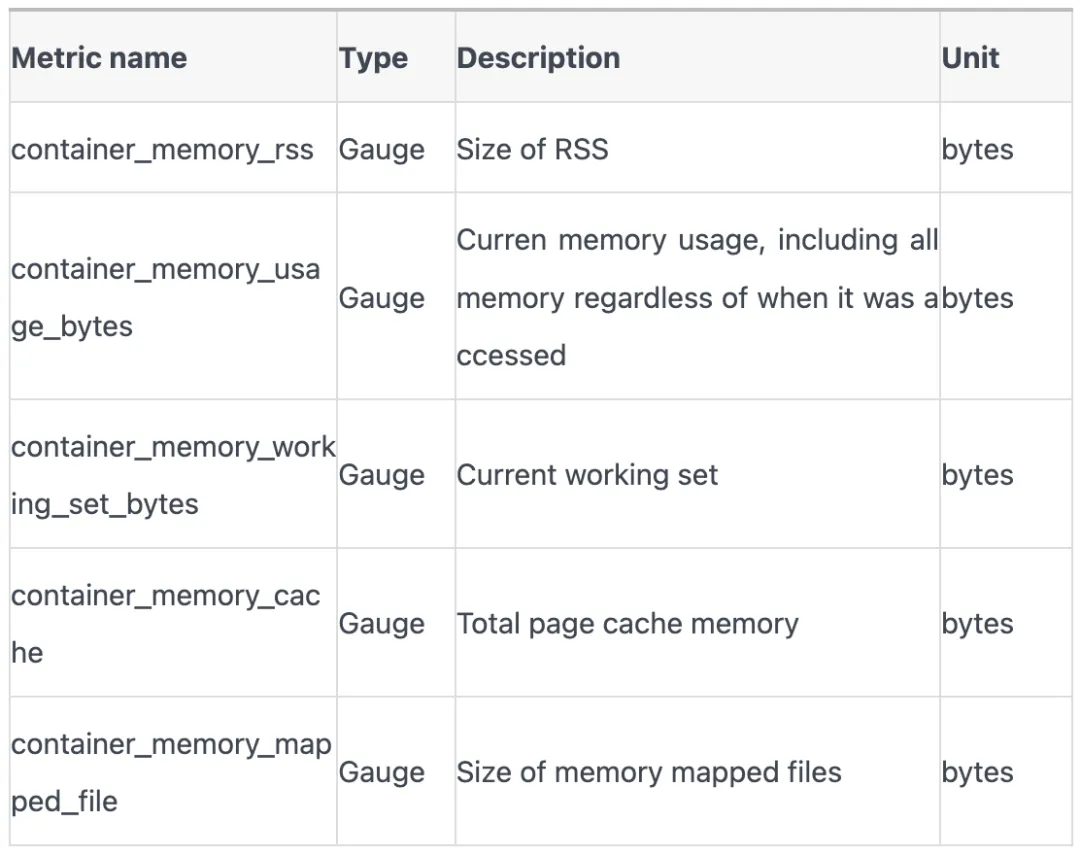
这些指标究竟是什么含义?在不同的应用场景下需要重点关注哪些指标?让我们从回顾linux进程地址空间开始,逐步挖掘容器内存使用奥秘。
一、进程是怎么分配内存的?
回忆一下linux进程虚拟地址空间分布图。
在linux内核里描述上述图的结构是mm_struct,它还可以展开得更详细:
可以发现,linux进程地址空间是由一个个vm_area_struct(vma)组成,每个vma都有自己地址区间。如果你的代码panic或者Segmentation Fault崩溃,最直接的原因就是你引用的指针值不在进程的任意一个vma区间内。你可以通过 /proc/<pid>/maps 来观察进程的vma分布。
1. malloc分配内存
malloc函数增大了进程虚拟地址空间的heap容量,扩大了mm描述符中vma的start和end长度,或者插入了新的vma;但是它刚完成调用后,并没有增大进程的实际内存使用量。
以下是个代码示例证明上述言论。
可见输出:
阶段总结1
当memset 128MB长度的数据完成后,我们立刻观察到进程发生了32768次minor pagefault, 同时RSS内存占用提升到129MB。注意 32768 * 4096正好等于128MB,而4096正好是linux page默认大小。可以在程序sleep的时段用top观察监控统计进一步证实结论。
进一步说,malloc申请到的地址,在得到真实的使用之前,必须经历缺页中断,完成建立虚拟地址到物理地址的映射。完成物理页分配的虚拟地址空间才会被计算到内存使用量中。
二、container_memory_rss
1.. 进程的RSS
进程的RSS(Resident Set Size)是当前使用的实际物理内存大小,包括代码段、堆、栈和共享库等所使用的内存, 实际上就是页表中物理页部分的全部大小。
更精确地说,根据内核的 get_mm_rss, RSS由FilePages, AnnoPages和ShmemPages组成。
以下是一个例子,分别展示了这三种内存的申请和使用方式,FilePages, AnnoPages和ShmemPages 分别为4MiB, 8MiB和10MiB,供给22MiB.
观察top -p $pid的输出:
通过top发现,进程的RSS 是24184KiB, 比我们申请的22MiB,也就是22528KiB, 要大1656KiB。
进一步观察/proc/$pid/status,发现:
VmRSS和top里看到RES完全一致。RssAnno 比8092KiB多了120KiB,因为它还包括了stack。RssFile比 4096KiB多了1536KiB,因为它还包括了共享库。内核mm_struct计数并不总是完全及时和精准的。
阶段总结2
进程RSS组成 | 描述 |
匿名页 | 通常来源于 malloc,进入 brk 或者 mmap 匿名映射 |
共享内存 | 来自 shmget 系列调用 |
mmap 文件映射 | 通过 mmap 调用映射文件到进程地址空间 |
栈 (stack) | 进程的调用栈 |
二进制文件 | 加载进程本身的二进制文件占用的内存 |
动态链接库 | 加载的动态链接库(共享库)占用的内存 |
页表 | 内核中存储页表的部分 |
2. 容器(memcg)的RSS
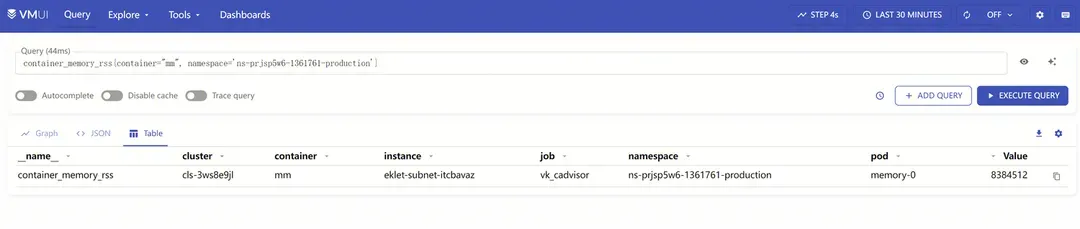
K8s容器环境下,容器里的进程都归属同一个cgroup控制组,本文只关注内存控制组(memcg)。把刚才的代码做成容器镜像,部署在TKEx环境里, 观察容器内存使用相关指标。

观察到container_memory_rss只有2047 * 4096 Bytes, 略小于8MiB, 远远低于上一节top观察到的24MiB,这是为什么?
1.1中通过观察/proc/$pid/status和top的输出,我们得出了进程的RSS估算方法,即:
- 占主要部分的 malloc导致的匿名页(brk/mmap匿名映射) + 使用shmem共享内存 + mmap文件映射;
- stack部分,text部分和动态链接库部分,页表部分,通常占比很小。
那memory cgroup的RSS的计算方法是不是就是简单地把memcg下归属的所有的进程RSS简单求和呢?显然不是。通过追溯cadvisor相关代码, 发现这个数值来来自容器所属cgroup path下的memory.stat文本中的rss字段。
(1) 如何找到容器对应的memcg path?
每个容器的 Memory Cgroup 路径根据其 QoS 类别和唯一标识符来确定。路径的基本格式如下:
Burstable:
BestEffort:
Guaranteed:
可以通过查看Pod Yaml里的Status来确认Pod的Qos类别。
找到memcg path后,可以发现目录下有很多记录文件,这里关注memory.stat:
(2) memory.stat里的 rss 是怎么计算的?
追溯linux memory cgroup(后面记做memcg)的相关源码,memcg统计了以下内存使用:
跟踪MEMCG_RSS的记录情况,发现只有匿名页的数量被统计到MEMCG_RSS里,这和前面观察的进程的RSS不一样。共享内存page只被计入MEMCG_CACHE,即便它位于匿名LRU。
而我们之前观察到 container_memory_cache接近14MiB, 包括了Shmem和mmap文件映射的部分。这样得出的结论是,memory cgroup的RSS只统计了上述代码中malloc分配出的内存,不包含另外两部分。
阶段总结3
类别 | 进程的 RSS | 容器的 RSS |
brk 分配 | ✔ | ✔ |
mmap 匿名映射 | ✔ | ✔ |
共享内存 | ✔ | |
mmap 文件映射 | ✔ | |
栈 (stack) | ✔ | ✔ |
二进制文件 | ✔ | ✔ |
动态链接库 | ✔ | ✔ |
页表 | ✔ | ✔ |
三、container_memory_cache
1. 初识PageCache
Page cache 是操作系统内核用来缓存文件系统数据的一种机制。它通过将文件数据缓存到内存中,从而减少磁盘 I/O 操作,提高文件读取的性能。当应用程序读取文件时,内核会首先检查 page cache,如果数据已经在缓存中,则直接从内存中读取,避免了磁盘访问。
以下是一个C语言小程序来演示如何通过读写文件来产生PageCache, 这个程序写100MiB数据到指定的文本文件中。
在执行这个程序前,做一次drop cache操作,用来清理系统已有的pagecache:
然后记录此时系统pagecache的信息。
编译运行小程序,再次查看系统 pagecache信息。
观察发现 /proc/meminfo中的Cached增加了102996KiB,约100.5MiB;free -m中buff/cache输出增长了104MiB,两者都约等于我们写入的文件大小, 之所以略有不同,是因为系统还有其他进程也在运行影响pagecache。
2. Active File和 Inactive File
仔细观察刚才/proc/meminfo的内容可以发现, 增加的100MiB pagecache全部体现在Inactive(File)这一项, Active(File) 基本没有变化。
事实上,第一次读写文件产生的pagecache,都是Inactive的,只有当它再次被读写后,才会被对应的page放在Active LRU链表里。Linux使用了2个LRU链表来分别管理Active 和Inactive pagecache,当系统内存不足时,处于Inactive LRU上的pagecache会优先被回收释放,有很多情况下文件内容往往只被读一次,比如日志文件,它们占用的pagecache需要首先被回收掉。
下面我们再测试一个小程序,创建一个文件并写入100MiB数据,然后连续两次读文件,观察/proc/meminfo前后变化。
测试前进行dropcache并记录数据。
完成测试,再次记录数据。
这时发现,Active(File)增长了103MiB,说明第二次读文件后,对应的pagecache被移动到Active LRU中。
3. 容器中的pagecache
追溯cadvisor的源码可以发现,container_memory_cache 来自memcg中memory.stat里的cache字段。再追溯linux源码,可以发现cache的取值源自memcg中的MEMCG_CACHE统计字段。注意memcg中的MEMCG_CACHE不仅包含了前面提到的ActiveFile和InactiveFile pagecache,它还包括了前面1.1中提到的共享内存。
将2.2中的程序稍作修改令其常驻不退出,然后制作成容器镜像,部署在TKEx平台中,观察内容监控数据如下。

可以发现接近pagecache占了接近100MiB,而rss使用量非常少。必须认识到,pagecache也属于容器内存使用量。
开发者可能很少感知自身程序pagecache的使用情况,容器平台会对程序的内存使用做限制,那么是否需要担心pagecache的上涨导致程序内存使用量超过容器内存限制,导致程序被OOM Kill?
实验探索这个问题。在一个1GiB Memory Limit容器中,已经通过malloc/memset使用了0.8GiB的rss内存,然后通过读100MiB磁盘文件产生100MiB左右的pagecache,此时容器内存使用量大约为0.9GiB,距离1GiB的限制量还差100MiB。
这时候程序还能malloc/memset 150Mi内存吗? 程序是否会因为超过memcg limit而被Kill?
编写如下程序然后制作容器镜像,部署到TKEx平台,将容器内存限制设置为1GiB。
运行发现最后这150MiB内存是可以分配使用的,程序并没有被Kill。
这是申请150MiB内存前,容器的内存使用监控记录:

这是申请150MiB内存后,容器的内存使用监控记录。

发现rss确实增长了150MiB,pagecache少了45MiB,总内存达到1023MiB, 并没有超过1GiB的限制。原因是在memset进入缺页中断分配物理页时,系统发现内存使用量会超过memcg limit的情况下,会先尝试回收pagecache以满足分配需求, 优先回收前面提到的Inactive File。由此可知,进程的rss不超过memcg limit的前提下, 可以放心申请使用内存,系统会及时释放pagecache来满足需求。pagecache属于内核,不属于用户,当用户需要内存时,内核会通过回收pagecache来归还内存,但这可能是有代价的。
代价是什么?
- pagecache用于提升磁盘文件读写性能,pagecache被回收意味着程序IO性能下降,延迟增加。因此生产环境一般严禁dropcache操作。
- 缺页中断进入更复杂的流程,page申请变慢, 直接阻塞用户进程,造成应用程序性能下降。
频繁进行文件读写的容器经常会遇到内存使用率一直接近99%的情况,就是由于linux为了提升文件读写性能,在memcg的限制内,尽可能地分配更多的pagecache。
阶段总结4
容器中的cache占用统计既包含了读写文件产生的pagecache,也包括了使用共享内存的大小。
容器环境下, 内存使用量接近memcg限制时候,继续尝试申请分配内存会先触发pagecache回收,以满足分配需求。
四、container_memory_mapped_file
1. mmap文件映射
mmap不仅可以为程序分配匿名页, 它还是一种内存映射文件的方法,允许将文件或设备的内容映射到进程的地址空间中。通过 mmap,可以直接访问甚至修改文件内容,就像访问内存一样,这通常比传统的文件 I/O 操作更高效。例如以下程序:
先初始化一个100MiB的文本文件,内容全部是字母A; 然后通过mmap将文件映射到程序地址空间里,通过memset将文件内容全改成字母B。借助mmap文件映射,使用内存操作就能完成文件读写。相较于标准buffered io, mmap文件映射会拥有更好的性能,因为它避开了用户空间和内核空间的相互拷贝,这个优势在一次读写几十上百MiB的场景下尤为突出。
将这个程序制作成容器镜像,部署在TKEx平台中,观察内存监控记录。

可以发现, mmap, 即container_memory_mmaped_file的监控值接近100MiB,而容器的rss依然非常低。观察/proc/<pid>/status:
发现进程的rss依然约101MiB。因此和前面提到的共享内存一样,mmap文件映射部分的大小属于进程的rss而不属于容器的rss。
2. mmap共享内存
(1) 共享文件映射
基于4.1的启发,只要多个进程mmap相同一个文件,就可以通过这个文件实现共享内存,完成多进程通信,这种方式叫做共享文件映射。
调用 mmap 进行文件映射的时候,内核首先会在进程的虚拟内存空间中创建一个新的虚拟内存区域 VMA 用于映射文件,通过 vm_area_struct->vm_file 将映射文件的 struct flle 结构与虚拟内存映射关联起来。
在缺页中断处理过程中,如果vma非匿名(即文件映射),linux首先通过 vm_area_struct->vm_pgoff激活对应的pagecache并预读部分磁盘文件内容到pagecache中,然后在页表中创建PTE并与pagecache文件页关联,完成缺页中断,此后对vma的访问实质上都是对pagecache的访问。进程1和进程2的共享文件映射,实质上是各自vma里的file字段最终指向了相同的文件,即相同的inode。进程1和进程2对各自vma的访问也实质上是对相同的pagecache进行访问,这就是基于文件映射实现共享内存的原理。当然,对vma的内容修改也会导致对pagecache的修改,最终通过脏页回写完成对磁盘文件的修改,因此这种共享内存的方式会产生真实的磁盘IO。
(2) 共享匿名映射
相对于共享文件映射,共享匿名映射也能实现共享内存,但只适用于父子进程之间。实现原理相对于共享文件映射略有类似,同样依赖了pagecache,但这里的文件不再是具体的磁盘文件,而是tmpfs。tmpfs是一个基于内存实现的文件系统,因此基于tmpfs的共享内存不会产生真实的磁盘IO。后面会了解到,基于ipc的共享内存,即1.1里通过shmget和shmat实现的共享内存,也是依靠tmpfs完成的。
3. 容器中的mapped file
回到cadvisor源码里,container_memory_mapped_file取值于memcg memory.stat里的mapped_file字段,实际上就是memcg中的NR_FILE_MAPPED字段。所有mmap调用产生的文件页,都会被统计到container_memory_mapped_file中。根据3.2.1的描述,mmap文件映射的原理与pagecache的行为紧密相关, mapped_file也会伴随着pagecache一起出现。
此外,mapped_file还包括tmpfs的使用量,下面来介绍tmpfs和shmem。
五、tmpfs与shmem
1. emptyDir的问题
emptyDir允许用户选择内存作为挂载介质。

当这么做的时候,会发现挂载点(下图的/data)对应的文件系统是tmpfs,这意味着/data里的数据实际上都存储在内存中。
如果没有为emptyDir卷设置sizeLimit,/data目录下的文件将占用Pod的内存;如果Pod没有设置内存limit,则/data可能消耗掉Node上全部的内存。
日常排障中经常收到客户的工单疑惑,进程似乎没有内存泄漏的情况,但内存使用量一直在上涨。通过面板发现pagecache一路上涨,最后发现挂载在tmpfs的/data/目录一直在输出程序log。 因此,请注意不要将emptyDir以内存为介质挂载后,将其作为输出日志目录。
2. System V IPC 共享内存
公司内部存在大量的IPC共享内存的使用场景,比如spp服务端框架。例如以下C语言程序例子:
(1) Writer
(2) Reader
分辨编译执行5.2.1和5.2.2,会发现5.2.2能读取到来自5.2.1的 Hello, this is a message from the writer process!。
同时执行 ipcs -m可以看到我们分配到的36MiB共享内存。
这时需要注意的是,当Writer和Reader进程都退出后,这部分内存依然在机器的tmpfs中,必须通过ipcrm命令来显示删除释放。
来到容器环境中,某个容器退出后,原进程中共享内存中的数据同样不会消失。如果剩余的容器没有使用该共享内存,这部分内存用量则只计入Pod Level Memcg的使用量。
如果你发现Pod的内存使用量明显大于所有容器内存使用量之和,可以通过ipcs查看是否存在Shmem数据。
六、监控实践
1. 程序自监控内存用量的小技巧
linux提供了一个系统调用getrusage(2)用于获取进程自身以及其子进程的资源使用情况,在1.1中我们已经初步接触过了,再提供一个go语言的调用示例。
可见,getrusage(2) 还能帮助开发者自监控CPU使用率。
2. Top和Pid Namespace
在容器内执行top查看到的cpu和memory使用率通常并不是容器的真实使用率,因为/proc/stat和/proc/meminfo的视野是整个机器而非Pod或者容器。详情见以下。
Node类型 | CVM Node | TKE Serverless Node |
CPU/内存使用率范围 | Node全部,包括其他Pod | 包括自身容器和虚机其他进程,如洋葱安全,eklet-agent等 |
如果你的容器部署在TKE Serverless节点中,TKEx和TKE AppFabric也提供了Pod所在虚机的基础监控,如下图所示。
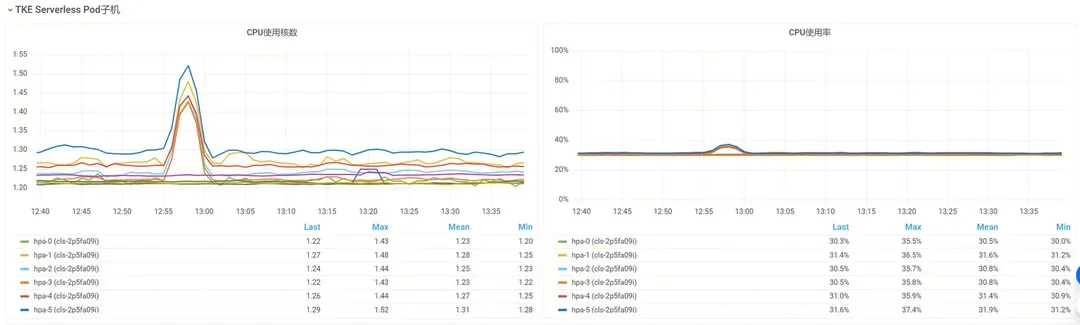
虚机的监控数据与Top的输出吻合。
如果你在容器内使用top观察进程的监控数据,需要明确的是Pod内不同容器的Pid Namespace默认是不共享的,你无法观察另一个容器的进程数据。
开启Pid Namespace共享可以获得更多的观测手段,比如使用带有dlv, gdb等调试工具的sidecar容器来调试主容器进程。但需要开启对应的特权,比如ptrace,以及不能使用Systemd拉起富容器的模式部署业务。
3. 我的容器内存使用率超过了100%
我好像白薅了平台的内存,这是怎么回事?
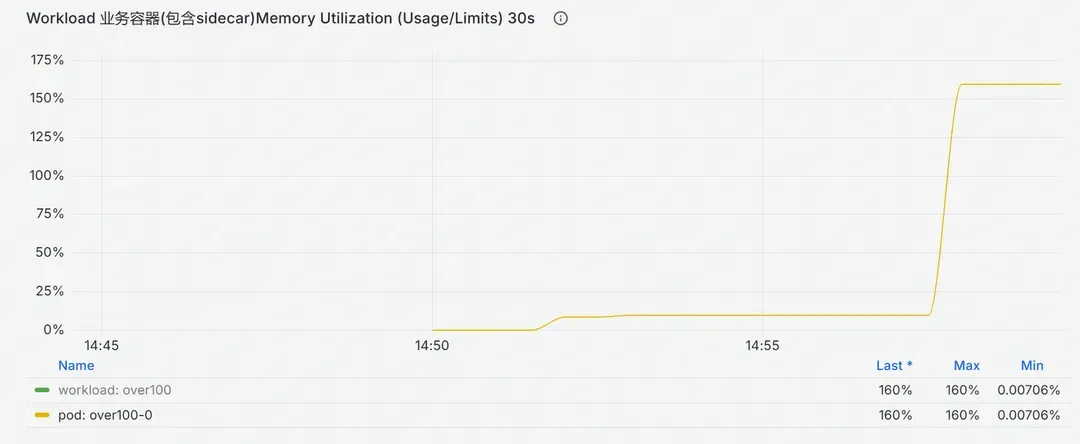
如上图所示,内存使用量已经大幅度超过了容器本身的内存限制量,按照常识,容器会被OOM Kill。然而现网中存在一些明显超过内存限制量却依然在正常运行的容器。
前文说过,K8s为容器设置了Pod和Container级的memcg内存限制,任何一个容器内存使用量突破了Container层级的限制,会触发OOM Kill; 所有容器内存使用和突破了Pod层级的限制,也会触发OOM Kill。出现超限使用意味着这两道限制都已经失效。
排查发现,这类超限运行Pod普遍存在2个特征:
- 存在一个用Systemd拉起的富容器,Systemd版本早于236;
- 存在一个未配置Limit的sidecar容器。
两个特征同时满足的时候,K8s设置的两层限制都会失效。如果容器开启特权并且/sys/fs/cgroup被挂载,Systemd会覆盖K8s为容器设置的cgroup limit;任意一个未配置Limit的容器会使得Pod的QOS降级到Burstable甚至BestEffort, Pod层级的内存限制变成无穷大。
超限使用内存会导致Node的内存被占用,滋生稳定性风险。建议使用较新的ubuntu/centos/tlinux基础镜像,搭载较新版本的Systemd拉起业务容器,避免超限使用内存。
4. 我担心OOM Kill,配置哪个指标做内存使用告警?
通常基于container_memory_working_set_bytes做内存使用告警,内存使用率的计算公式为:
container_memory_working_set_bytes在memcg的全部使用量的基础上,减去了Inactive File部分, 认为这部分pagecache可以迅速回收而不会给业务进程造成显著的负载压力,可以不计入容器的内存使用量。如下是cadvisor的统计代码细节。
七、结尾
一路过来,我们了解缺页中断的概念,RSS的统计,认识了Linux Memcg内存控制组,观察了pagecache的分配和回收,初识了tmpfs,以及在容器中使用共享内存等等。读到这里,文章开头提到的几个问题应该有了清晰的答案。祝大家的程序稳如泰山,永不OOM。