一、背景
vivo 作为一家以设计驱动创造伟大产品,以智能终端和智慧服务为核心的科技公司,服务全球5亿+用户,用户持续增长,同时数据量也持续增长,在数据库运维过程中遇到如下问题:
- 分库分表:随着业务数据量的不断增长,MySQL 实例数据量超过了单机容量限制,业务分库分表的需求越来越多,分库分表的改造成本和风险比较高,需要能够兼容 MySQL 的分布式数据库解决分库分表的问题。
- 成本压力:业务用户基数比较大,每年的数据自然增长规模也很大,需要持续采购新的服务器来满足数据增长需求,存在一定的成本管理压力。
基于上述问题,我们调研了目前市面上兼容 MySQL 且较为成熟的分布式数据库产品后,最终选择了 OceanBase,期待其原生分布式和分区表特性解决 MySQL 的分库分表问题;其极致的数据压缩能力与组户级资源隔离节省存储成本、运维成本。
1.1 原生分布式和分区表特性
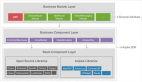
OceanBase 的原生分布式架构分为 OBProxy 层, OBServer 层,前者负责数据路由转发,后者负责数据存储与计算。OceanBase 通过可用区(Zone)来划分节点,以便集群内的自动容灾处理和优化策略能更好地工作,根据不同的场景部署不同高可用方案,如:同城三机房三副本部署,三地五中心五副本部署等,同时,通过增加节点实现透明水平扩展,支持业务快速的扩容和缩容,解除我们的单机容量限制。

OceanBase 分布式架构
(图片来源: OceanBase 官网)
1.2 数据压缩能力与组户级资源隔离
OceanBase 的表可设计为分区表,每个分区均衡分布到不同的 OBServer 节点上,每个物理分区有一个用于存储数据的存储层对象,叫做 Tablet,Tablet 有多个副本分布在不同的 OBSever 节点,使用日志流(Log Stream)来做数据持久化和副本之间的数据同步,正常情况下主副本提供服务,当主副本故障时会自动切换从副本,从而保证数据的安全性与可用性,一个集群可创建多个互相之间隔离的数据库"实例",叫做租户(Tenant),可为多个独立业务提供服务,租户间数据隔离,降低部署和运维成本。此外,得益于 LSM-Tree 的存储引擎,OceanBase 具备极致的数据压缩能力,据官方文档及企业案例介绍,可以使存储成本降低60%以上。
总的来说,OceanBase 的原生分区表能很好地解决业务架构中分库分表带来的问题,分区表对上层业务无感知,可以节省大量的改造成本与时间,并降低风险,提高业务可用性,数据压缩能力可以极大地节省我们的存储空间,此外,OceanBase 的性能、可用性、安全性、社区支持等方面也都符合运维预期,满足业务需求。
二、OceanBase 落地实践
为了更顺畅的实现迁移和运维 OceanBase 数据库,在正式迁移前,我们部署了 OceanBase 运维 OCP 平台、日志代理工具 oblogproxy、迁移工具 OMS,具备了集群部署管理、监控报警、备份恢复、日志采集、迁移等运维能力,结合内部数据库运维管理平台,实现了元数据管理、数据查询、数据变更等能力,能够满足 DBA 运维和业务查询变更需要,具备生产上线的条件。
2.1 OCP 平台部署
OceanBase 云平台(OceanBase Cloud Platform,OCP)是一款以 OceanBase 为核心的企业级数据库管理平台,提供对 OceanBase 集群和租户等组件的全生命周期管理服务,也对 OceanBase 相关的资源(主机、网络和软件包等)提供管理服务,能够更加高效地管理 OceanBase 集群,降低企业的 IT 运维成本。

OCP 架构
(图片来源: OceanBase 官网)
OceanBase 云平台包括管理 Agent(Management Agent)、管理服务(Management Service)、元信息数据库(Metadata Repository)、监控数据库(Monitor Repository)、管理控制台(Management Console)和 OBProxy(OceanBase 专用反向代理) 这六个模块,每个模板之前协同工作。OCP 还提供高可用方案,一主多备,解决单点故障问题。
在部署时,我们将 OCP 元数据,管理服务等均使用三节点跨机房部署,避免单一节点故障,实现高可用性。由于公司已有一套告警平台,所以在部署时,我们通过 OCP 的告警通道自定义脚本功能实现 OCP 与公司告警服务的对接,让 OCP 的告警能更好地兼容到公司的告警平台。
OCP 工具的另一项重要功能是备份与恢复。在 OCP 中,物理备份由基线数据、日志归档数据两种数据组成,数据备份优先选择 Follower 副本进行备份,当用户发起数据备份请求时,该请求会首先被转发到 RS 所在的节点上,RS 会根据当前的租户和租户包含的 PG 生成备份数据的任务,然后把备份任务分发到 OBServer 节点上并行地执行备份任务,把备份文件数据存放在指定的网络存储,如NFS、S3等。

OCP 备份架构
(图片来源: OceanBase 官网)
OceanBase 数据库支持的备份介质丰富,包括 NFS、阿里云 OSS、腾讯云 COS、AWS S3 ,以及兼容 S3 协议的对象存储。此处值得一提的是,在 OCP上创建备份策略,存储介质为S3,集群发起备份时要把备份文件存放在指定S3目录,如下图所示。

2.2 oblogproxy 工具部署
oblogproxy(OceanBase LogProxy,即 OceanBase 日志代理)是 OceanBase 的增量日志代理,它可以与 OceanBase 数据库建立连接并进行增量日志读取,为下游服务提供变更数据捕获(CDC)的能力。其 Binlog 模式为兼容 MySQL binlog 而诞生,支持现有的 MySQL binlog 生态工具来同步 OceanBase,现有的 MySQL binlog 生态工具可以平滑切换至 OceanBase 数据库。

oblogproxy 架构
(图片来源: OceanBase 官网)
oblogproxy 启动 bc 模块用于拉取 OceanBase clog 并将其转换为 binlog 格式,转换后将其写入到文件,即 binlog 文件,MySQL binlog 生态工具(图中为 Canal 或 Flink-CDC)发起 binlog 订阅请求到 OBProxy,OBProxy 收到 binlog 订阅请求后将其转发至 oblogproxy,接收到 OBProxy 转发的 binlog 订阅请求后启动 bd 模块,bd 模块启动后读取 binlog 文件并对外提供订阅服务,即 binlog dump 。我们通过网络共享存储存放元数据的方式实现oblogproxy 多节点部署,避免单一节点故障,实现高可用。
2.3 OMS 工具部署
OceanBase 迁移服务(OceanBase Migration Service,OMS)是 OceanBase 数据库提供的一种支持同构或异构数据源与 OceanBase 数据库之间进行数据交互的服务,具备在线迁移存量数据和实时同步增量数据的能力。

OMS架构
(图片来源: OceanBase 官网)
OMS 主要服务包含:
- DBCat,数据对象采集和转换组件。
- 增量拉取组件 Store、增量同步组件 Incr-Sync、全量导入组件 Full-Import 和全量校验组件 Full-Verification。
- 基础服务组件,包括集群管理、资源池管理、高可用组件和元数据管理等多个组件,以保证迁移模块的高效调度和稳定运行。
- 管理控制台,进行一站式迁移调度。
在部署 OMS 时,我们对于 OMS 元数据、迁移服务均使用三节点跨机房部署,避免单一节点故障,实现高可用。在使用 OMS 进行数据迁移、同步等监控与告警方面, OMS 没有重复实现相关组件,而是通过调用 OCP 的告警通道来发送告警。
三、数据库迁移方案与实践
3.1 MySQL 迁移 OceanBase 实践
为了防止迁移过程出现难以解决的问题,我们对迁移可行性进行了评估。经过性能压测、兼容性测试(表结构,查询 SQL,账号等)均符合要求。在进行分区适应性测试时,发现业务使用分区表时,表结构需要做兼容性修改,查询 SQL 也要适配分区表,但结合业务改造成本评估,结果也符合预期。
我们使用 OMS 将 MySQL 数据迁移到 OceanBase,迁移链路支持全量和增量,保证数据的实时同步和全量校验并提供反向增量同步,迁移异常时业务能快速回滚,保证业务可用性。

OMS 数据迁移项目
迁移流程分为8个步骤:
- 第一步,迁移前配置校验。
- 第二步,验证 OceanBase租 户与账号。
- 第三步,数据一致性校验。
- 第四步,DDL 表结构修改暂停。
- 第五步,数据同步延迟校验。
- 第六步,应用切换数据库连接配置,或者修改域名解析。
- 第七步,KILL 源库残余连接,确保应用连接到OceanBase。
- 第八步,停止 OMS 数据正向同步,开启反向同步,用于回滚。

以上流程是为确保切换成功,减少迁移风险,并提供了回退预案,最大程度保证业务的可用性与安全性。
迁移了5套 MySQL 集群近20T的数据到 OceanBase 集群,带来如下收益:
- 云服务存储了海量数据并且数据还在持续快速增长,原本 MySQL 分库分表方案的维护与管理需要巨大成本,而且存在较大的可用性风险。OceanBase 分区表替代了分库分表方案,不仅解除了维护管理成本,高压缩特性也节省了存储成本。
- 风控集群数据写入量较大,导致主从延迟一直居高不下,存在数据丢失风险,OceanBase 数据强一致性很好的解决这个问题并且存储空间节省70%。
- 金服归档库使用 tukodb 存储,存在唯一索引失效的问题,tukodb 官方也不再维护,可用性得不到保证,迁移 OceanBase 后,该问题迎刃而解,查询与 DDL 性能有大幅度的提升,分布式水平扩展解决单机容量问题。
3.2 某分布式数据库迁移 OceanBase 实践
由于此前在一些边缘业务应用某分布式数据库,自 OceanBase 上线后,我们也决定将这部分业务统一迁移到 OceanBase。我们考虑了两种迁移方案,第一种方案是基于某分布式数据库的增量同步工具和 KAFKA+OMS,第二种方案是基于 CloudCanal,并进行了方案对比,如下:

CloudCanal 虽然架构简单,但不支持反向同步,增量同步性能较差,不满足业务迁移需求;CDC+KAFKA+OMS 架构虽较复杂,但其与 OceanBase 兼容性更好,支持反向同步便于业务回退,整体性能也更好。因此,最终选择基于 CDC+KAFKA+OMS 的架构方案进行全量迁移和增量同步,同时进行全量校验,并提供反向增量同步。

CDC 把集群的增量数据解析为有序的行级变更数据输出到下游的 Kafka,OMS 通过消费 Kafka 的增量数据写入 OceanBase 完成增量同步。Kafka的数据默认保留7天,如果考虑到数据延迟较大的情况,可以适当调整 Kafka 数据保留时间,同时,OMS 也可以通过增加并发等配置来提高同步速度。
在进行近500亿全量数据同步时,RPS(行/秒)非常低,只有 6000-8000,需要几周才能迁移完成,这显然是不符合预期的。经过分析,发现数据源与目标端均无压力和异常,OMS 服务主机负载也正常,显然问题不在这里。继续分析发现源表的自增主键ID不是连续的,且跨度很大, OMS 默认使用主键来做数据分片,导致全量同步时每次只同步到少量的有效数据,致使 RPS 比较低。
我们修改 source.sliceBatchSize(每个分片记录数)为12000,并把内存调大,调整之后RPS有明显的提高:39,257 /39,254,但仍未达到预期。
通过分析 OMS 的全量同步的 msg/metrics.log 日志,发现wait_dispatch_record_size": 157690,这个指标很高,显示异常:wait_dispatch_record_size 大于 0,表示 OMS 内部计算数据归属分区存在瓶颈,分区表情况下一般都会有积压,分区计算比较耗时,关闭分区计算 sink.enablePartitinotallow=false,并调大 srink.workerNum,RPS 平均能达到50-60W左右,至此迁移性能基本符合预期。
此外,在数据迁移时,我们也遇到三个问题,以下列出问题及解决方案,供大家参考。
问题1
OMS 迁移任务提示 The response from the CM service is not success 。
解决方案:
分析任务 connector.log 日志,提示 CM service is not success,但查看CM服务状态是正常的,分析同步任务的内存使用情况,发现内存严重不足,FGC 次数非常高,导致服务异常,调整CM内存:进入 OMS 容器,修改:
/home/admin/conf/command/start_oms_cm.sh,jvm修改为 -server -Xmx16g -Xms16g -Xmn8g
问题2
增量同步 RPS 过低,加大并发后基本也就是 8000 左右,而且数据库与 OMS 并没有明显的压力。
解决方案:
分析增量任务 connector.log 日志,发现增量追平全量同步位点时还一直提示有大量的 PRIMARY 冲突,但发现源和目标端的数据并没有异常,不存在数据冲突问题,最后发现是 CDC 写入重复数据的原因,进而使 OMS 无法批量写入,导致 RPS 过低。目前 OMS 版本还没有针对这个场景优化,只能加大写入并发数让 RPS 有一定的提升。
问题3
索引空间放大问题,在集群空间使用率只有50%左右,空间充裕时创建索引时报空间不足:ERROR 4184 (53100): Server out of disk space。
解决方案:
分析集群节点空间使用率,集群的节点剩余空间还有一半,空间还是比较充裕的,正常来说不应该会空间不足。从 OBServer 日志可见,索引创建时空间放大了5.5 倍,需要5.41TB,而目前集群只剩余1.4TB,明显空间不足。
OceanBase 4.2.3之前的版本存在索引放大的原因是:
- 排序时落盘的中间结果,同时有元数据记录;
- 外部排序有两轮数据记录;
- 排序的时候,数据是解压缩解码的。
OceanBase 4.2.3及更高版本进行了优化,使用紧凑格式存放中间结果并做压缩,同时,让数据一边写一边释放空间。目前,索引空间放大优化到1.5倍,因此,对于数据较大且增量数据较大的场景可以使用4.2.3之后的版本。
四、总结
总结而言,vivo 互联网业务使用 OceanBase 解决了使用 MySQL 遇到的痛点问题。OceanBase 的性能与数据压缩能力比较优秀,其丰富的生态工具也提供了较为完善的运维能力。后续我们将持续深入 OceanBase 的能力探索,同时期待 OceanBase 对于运维工具的功能细节更加完善,开放更多功能,解决我们遇到的问题。