在现代软件开发中,Java 虚拟机(JVM)作为 Java 应用程序运行的基础平台,其稳定性和性能直接影响到应用程序的表现。无论是大型企业系统还是小型应用,JVM 的健康状况都是确保业务连续性的关键因素之一。
然而,在实际生产环境中,JVM 时常会遇到各种各样的问题,如内存泄漏、垃圾回收频繁、线程死锁等。这些问题不仅会导致系统响应变慢,甚至可能引发服务中断,给企业和用户带来严重损失。
本指南旨在帮助开发者和运维人员快速定位并解决常见的 JVM 故障。我们将从基础知识入手,逐步深入到具体的故障现象分析与解决方案,希望能够为读者提供一套系统的故障排查方法论。

一、前置储备
1.jstack简介
jstack是JVM自带的工具,用于追踪Java进程线程id的堆栈信息、锁信息,或者打印core file,远程调试Java堆栈信息等。
而我们常用的指令则是下面这条:
# 打印对应java进程的堆栈信息
jstack [ option ] pid 对应的option常见选项如下:
-F 当正常输出的请求不被响应时,强制输出线程堆栈
-m 如果调用到本地方法的话,可以显示C/C++的堆栈
-l 除堆栈外,显示关于锁的附加信息,在发生死锁时可以用jstack -l pid来观察锁持有情况2.线程状态复习
在使用jstack排查问题之前,我们必须了解堆栈中的信息,所以我们首先必须复习一下线程中的六大状态:
- New:线程处于创建但还未启动的状态。
- RUNNABLE:RUNNABLE其实是JVM自定义的一种状态,如果和操作系统的线程状态进行等价理解的话,RUNNABLE是处于操作系统Running或者Ready状态,因为CPU在这两个状态间的切换几乎是瞬时的,所以JVM统一用RUNNABLE表示。
- Waiting:线程处于等待唤醒状态。
- Timed Waiting:在有限时间内线程等待唤醒。
- Blocked:程序等待进入同步区域,等待监视器锁中,线程处于阻塞状态。
- Terminated:线程工作完成,处于结束状态了。
了解过线程状态后,我们就可以了解一下jstack导出的dump文件中线程会基于这些状态出现的各种情况:
runnable:线程处于执行中
deadlock:死锁(重点关注)
blocked:线程被阻塞 (重点关注)
Parked:停止
locked:对象加锁
waiting:线程正在等待
waiting to lock:等待上锁
Object.wait():对象等待中
waiting for monitor entry:等待获取监视器(重点关注)
Waiting on condition:等待资源(重点关注),最常见的情况是线程在等待网络的读写3.MAT(Memory Analyzer)下载安装
mat下载地址:https://www.eclipse.org/mat/previousReleases.php
为了后续我们可以查看JVM输出的hprof日志,我们需要下载一个MAT的工具,如下图所示,选择更早版本
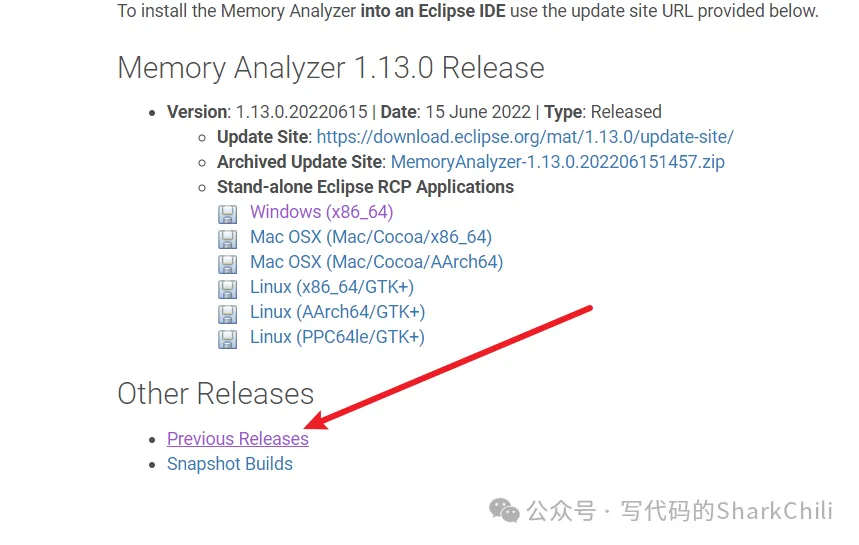
以笔者为例,笔者就选择了1.7版本
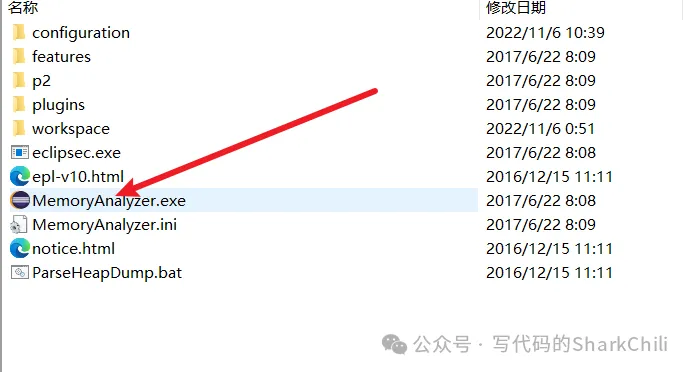
完成下载后,双击下面这个exe文件能打开就说明一切正常
二、详解线程死锁问题排查思路
1.问题代码
如下所示,笔者写了一段死锁的代码,如下所示,然后将其放到服务器中启动:
@RestController
public class TestController {
private static Logger logger = LoggerFactory.getLogger(TestController.class);
private Object lock1 = new Object();
private Object lock2 = new Object();
/**
* 模拟一个线程死锁的请求
*
* @return
*/
@GetMapping("deadLock")
public String deadLock() throws Exception {
Thread t1 = new Thread(() -> {
logger.info("线程1开始工作,先获取锁1");
synchronized (lock1) {
try {
Thread.sleep(3000);
} catch (InterruptedException e) {
e.printStackTrace();
}
logger.info("线程1获得锁1,尝试获得锁2");
synchronized (lock2) {
logger.info("线程1获得锁2成功");
}
}
});
Thread t2 = new Thread(() -> {
logger.info("线程2开始工作,先获取锁2");
synchronized (lock2) {
try {
Thread.sleep(3000);
} catch (InterruptedException e) {
e.printStackTrace();
}
synchronized (lock1) {
logger.info("线程2获得锁1成功");
}
}
});
t1.setName("my-thread-1");
t2.setName("my-thread-2");
t1.join();
t2.join();
t1.start();
t2.start();
return "success";
}
}2.复现问题
由于这只是一个demo,我们日常发现这种问题的时候大概率是多线程中的业务没有结束,所以重现问题也很简单,通过命令调用一下接口即可
curl http://localhost:8888/deadLock3.排查思路
首先确定当前发生死锁的java应用,我们通过jps确定进程id,可以看到笔者服务器的进程id为23334,然后通过jstack -l查看锁以及锁的附加信息:
jstack -l 23334最终可以在jstack的最下方看到这样一段信息(Found one Java-level deadlock),由此确认出现my-thread-1持有0x00000000ec509610等待0x00000000ec509620,my-thread-2反之。
然后我们通过jstack信息即可定位到问题代码在TestController.java:53以及TestController.java:37。
Found one Java-level deadlock:
=============================
"my-thread-2":
waiting to lock monitor 0x00007f2800ac9318 (object 0x00000000ec509610, a java.lang.Object),
which is held by "my-thread-1"
"my-thread-1":
waiting to lock monitor 0x00007f27e40062c8 (object 0x00000000ec509620, a java.lang.Object),
which is held by "my-thread-2"
Java stack information for the threads listed above:
===================================================
"my-thread-2":
at com.example.jstackTest.TestController.lambda$deadLock$1(TestController.java:53)
- waiting to lock <0x00000000ec509610> (a java.lang.Object)
- locked <0x00000000ec509620> (a java.lang.Object)
at com.example.jstackTest.TestController$$Lambda$582/2089009876.run(Unknown Source)
at java.lang.Thread.run(Thread.java:748)
"my-thread-1":
at com.example.jstackTest.TestController.lambda$deadLock$0(TestController.java:37)
- waiting to lock <0x00000000ec509620> (a java.lang.Object)
- locked <0x00000000ec509610> (a java.lang.Object)
at com.example.jstackTest.TestController$$Lambda$581/1994255298.run(Unknown Source)
at java.lang.Thread.run(Thread.java:748)
Found 1 deadlock.三、详解CPU 飙升问题排查思路
1.问题复现
导致CPU 100%的原因有很多,一般来说都是编码不当导致的,所以常规的排查思路为:
- 定位进程号,如果是Java进程则查看是哪个线程导致的。
- 定位导致CPU 飙升的线程号,转为16进制。
- 导致JVM锁信息日志,使用线程号定位代码。
- 排查并修复代码问题。
首先笔者准备了一个导致CPU飙升的问题代码,可以看到线程池中的线程不会停止不断工作
private ExecutorService threadPool = Executors.newFixedThreadPool(100);
private static Object lock = new Object();
private static Logger logger = LoggerFactory.getLogger(TestController.class);
public TestController() {
}
@GetMapping({"/test"})
public void test() {
for(int i = 0; i < 100; ++i) {
this.threadPool.execute(() -> {
logger.info("加法线程开始工作");
long sum = 0L;
Object var2 = lock;
synchronized(lock){}
try {
while(true) {
sum += 0L;
}
} finally {
;
}
});
}
}然后我们发起请求:
curl http://localhost:9550/test2.排查过程
此时使用top命令查看,可以看到24411号进程CPU占用百分比飙升。此时我们就需要进一步定位这个进程的哪一个线程出问题了。
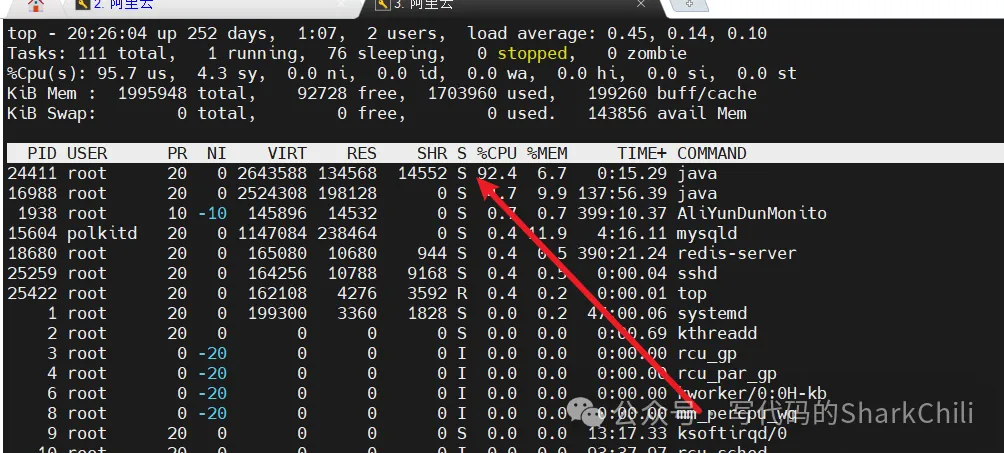
所以我们需要进一步定位这个问题是哪一个线程导致的,命令如下所示,使用线程模式查看对应pid的线程情况
top -Hp 24411可以看到25321这个线程CPU占用过高,此时我们就可以通过thread dump定位导致问题的代码段
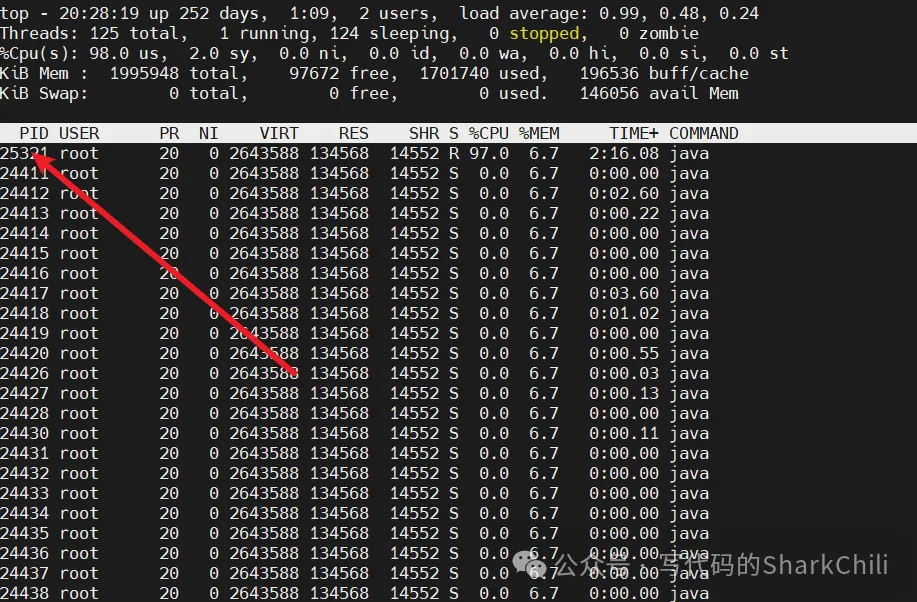
键入jstack -l 24411 >/tmp/log.txt到处日志,然后将线程号25321转为16进制,这里笔者使用了一个在线的网站地址
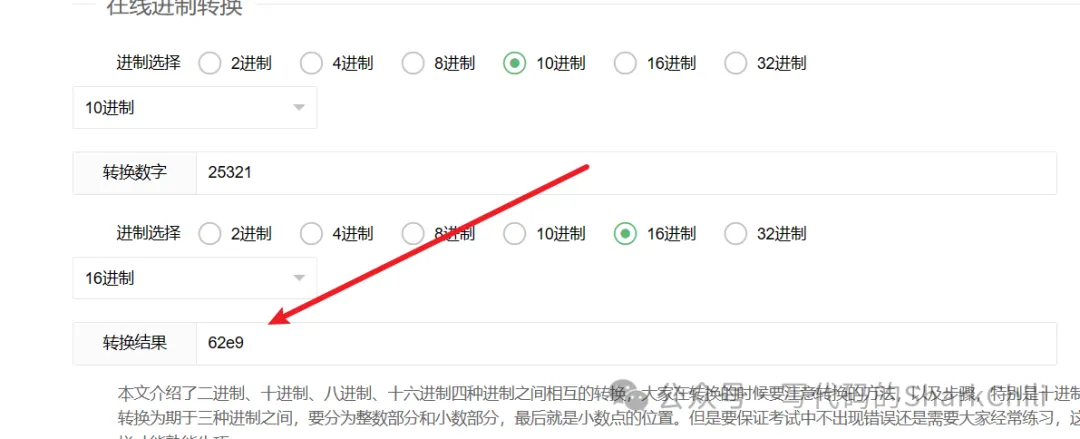
16进制转换:https://www.sojson.com/hexconvert.html
可以看到25321转换为16进制值为62e9,所以我们就使用62e9到导出的日志文件中查看这个线程堆栈情况。
使用转换的值从刚刚导出的日志中定位,可以看到该线程处于运行状态,很明显这个线程一直处于运行中,有一段逻辑肯定在不停的消耗CPU资源,所以我们查看代码位置在TestController.java:32,由此得到问题代码并修复问题。

四、详解OOM问题排查思路
1.复现问题
出现OOM问题大抵是有两个原因:
- 大流量导致服务器创建大量的对象把内存打爆了,面对这种情况我们除了熔断以外别无他法。
- 程序编写不规范导致,大流量情况下出现垃圾内存进而出现OOM,笔者本地探讨的就是这种情况。
如下所示,笔者初始化了一个程序,创建一个线程池,模拟无数个线程池将不断将内存写入4M的数据,并且不清理。
RestController
public class TestController {
final static ThreadPoolExecutor poolExecutor = new ThreadPoolExecutor(100, 100, 1, TimeUnit.MINUTES,
new LinkedBlockingQueue<>());// 创建线程池,通过线程池,保证创建的线程存活
final static ThreadLocal<Byte[]> localVariable = new ThreadLocal<Byte[]>();// 声明本地变量
@RequestMapping(value = "/test0")
public String test0(HttpServletRequest request) {
poolExecutor.execute(() -> {
Byte[] c = new Byte[4* 1024* 1024];
localVariable.set(c);// 为线程添加变量
});
return "success";
}
}完成后部署到服务器上,并使用以下命令启动,可以看到笔者调整的jvm堆内存大小(笔者服务器内存为1g故这里设置为100m),以及设置OOM输出参数
java -jar -Xms100m -Xmx100m # 调整堆内存大小
-XX:+HeapDumpOnOutOfMemoryError -XX:HeapDumpPath=/tmp/heapdump.hprof # 表示发生OOM时输出日志文件,指定path为/tmp/heapdump.hprof
-XX:+PrintGCTimeStamps -XX:+PrintGCDetails -Xloggc:/tmp/heapTest.log # 打印日志、gc时间以及指定gc日志的路径
demo-0.0.1-SNAPSHOT.jar完成后我们启动项目使用HTTP接口请求工具进行压测,可以看到服务器不久之后就出现了OOM问题:
java.lang.OutOfMemoryError: Java heap space
Dumping heap to /tmp/heapdump.hprof ...
Heap dump file created [151939570 bytes in 1.112 secs]
Exception in thread "pool-1-thread-5" java.lang.OutOfMemoryError: Java heap space
at com.example.jstackTest.TestController.lambda$test0$0(TestController.java:25)
at com.example.jstackTest.TestController$$Lambda$582/394910033.run(Unknown Source)
at java.util.concurrent.ThreadPoolExecutor.runWorker(ThreadPoolExecutor.java:1149)
at java.util.concurrent.ThreadPoolExecutor$Worker.run(ThreadPoolExecutor.java:624)
at java.lang.Thread.run(Thread.java:748)
Exception in thread "pool-1-thread-7" java.lang.OutOfMemoryError: Java heap space
at com.example.jstackTest.TestController.lambda$test0$0(TestController.java:25)
at com.example.jstackTest.TestController$$Lambda$582/394910033.run(Unknown Source)
at java.util.concurrent.ThreadPoolExecutor.runWorker(ThreadPoolExecutor.java:1149)
at java.util.concurrent.ThreadPoolExecutor$Worker.run(ThreadPoolExecutor.java:624)
at java.lang.Thread.run(Thread.java:748)
Exception in thread "pool-1-thread-9" java.lang.OutOfMemoryError: Java heap space2.排查思路
我们直接锁定java进程号之后,使用top -Hp pid查看进程的线程信息,可以看到这里面的每一个线程基本都把堆区内存打满了,我们不妨查看任意一个线程:
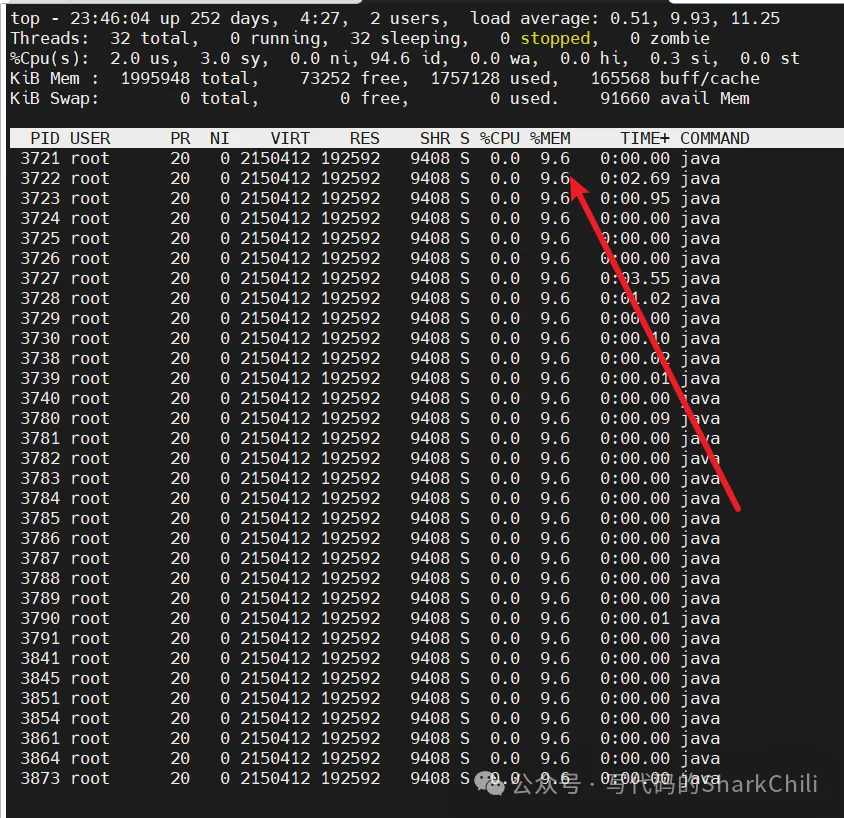
我们首先使用jstack -l 3721将日志导出,这里就以3873转为16进制查看线程状态,可以发现线程处于等待状态,而且日志中并没有存在死锁的信息,所以我们必须进一步查看堆区情况确认是否是因为内存泄漏导致的。

然后使用jmap查看堆区使用情况:
jmap -heap 3721从下面的日志可以看出老年代使用率高达82%,很明显有一些长期没有释放的对象在内存中导致OOM问题。
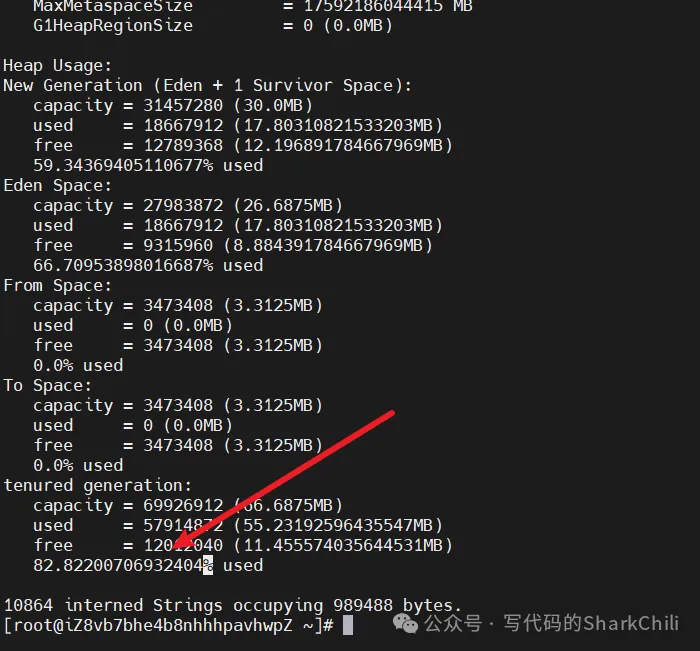
我们从上文设置的oom日志路径中找到日志/tmp/heapdump.hprof,导出到本地,使用MAT打开,找到使用率最高的Byte数组,点击下图Histogram ,点击内存占用最高的选项展开。
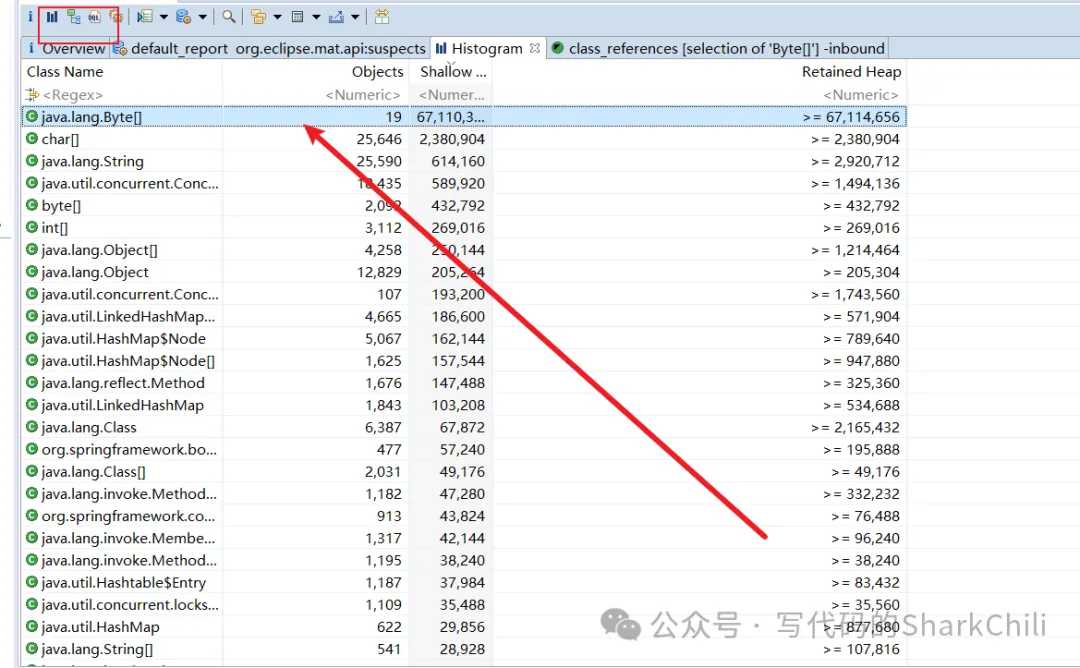
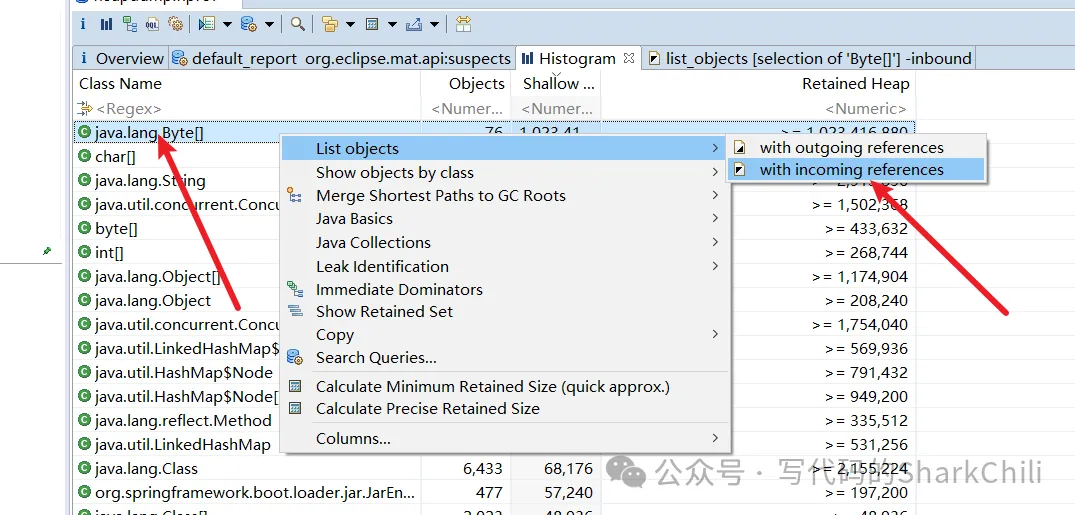
这里补充一下截图中看到的两个选项:
- with incoming references: 表示的是 当前查看的对象,被外部的应用。
- with outGoing references: 表示的是 当前对象,引用了外部对象。
所以我们的选择with incoming reference:
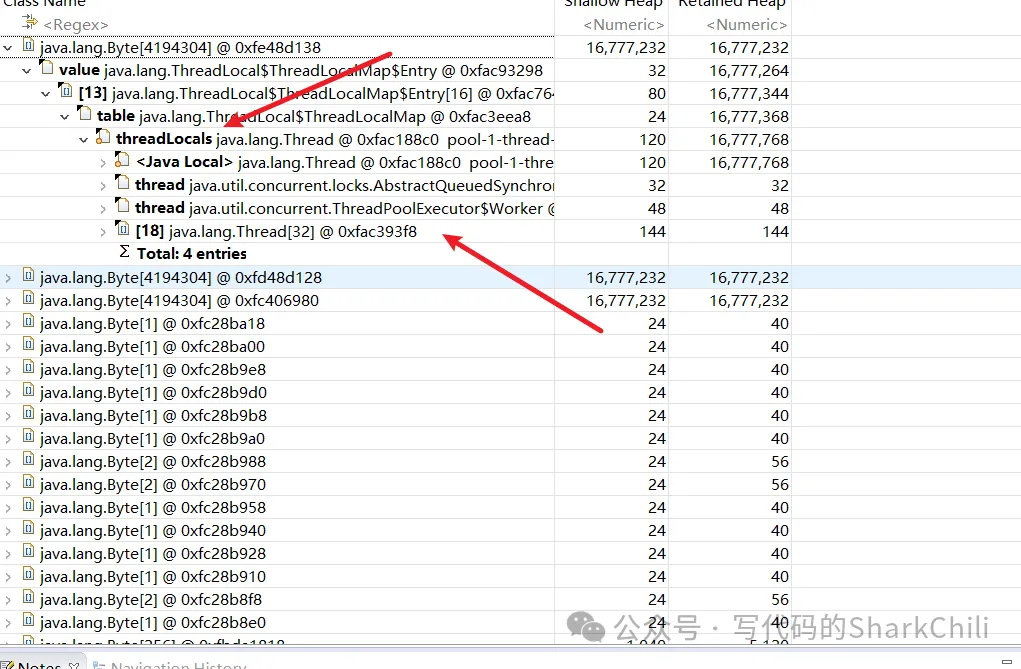
可以定位到就是我们一个线程池中的threadLocal使用不当导致OOM问题了
小结
通过本指南的学习,我们希望读者能够对 JVM 的内部机制有更深入的理解,并掌握一系列有效的故障排查方法和工具。JVM 作为 Java 应用程序的核心组件,其稳定性和性能对于业务的成功至关重要。
在实际工作中,面对复杂的生产环境和多变的应用需求,仅仅依赖于理论知识是远远不够的。因此,我们鼓励读者在实践中不断积累经验,结合实际情况灵活运用所学的知识和技术。只有这样,才能在遇到问题时迅速定位并解决问题,确保系统的高效运行。