EchoMimic V2是阿里达摩院开源的一款基于音频驱动的肖像动画生成工具。
这一工具不仅能让虚拟形象开口说话,实现口型同步,还能在音频驱动下添加头部和身体动作,将数字形象的表现力提升到一个全新的高度。
如果你对AI数字人、AI配音、AI动画等制作感兴趣,那么EchoMimic V2绝对是一个不容错过的工具!
主要特点
(1) 音频驱动的半身人物动画
- 支持通过音频驱动生成逼真的半身人物动画效果,适用于多种应用场景,如数字人直播、虚拟主播、视频编辑、AI配音等。
- 实现音频驱动的人物说话、表情和肢体动作的协调一致。
(2) 引人注目的动作表现力
通过新颖的音频姿势动态协调策略,包括姿势采样和音频扩散,增强半身细节、面部和手势表现力。
(3) 简化的生成流程:
减少条件冗余,简化生成流程,提高模型的实用性和灵活性。
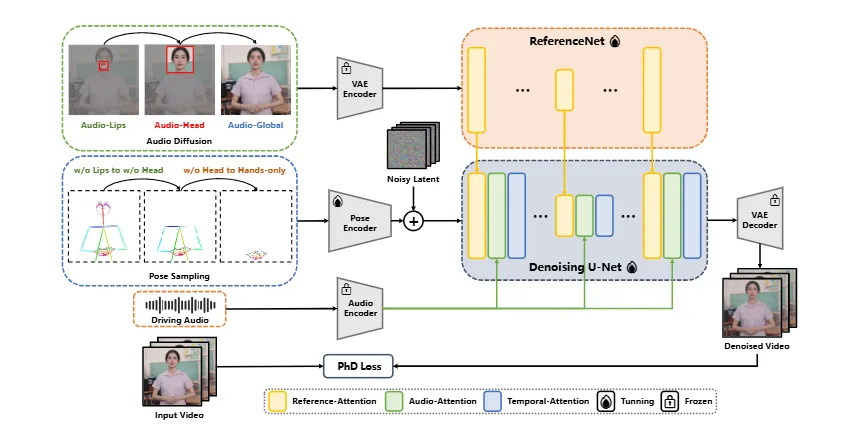
实现策略
(1) Audio-Pose Dynamic Harmonization策略:
- Pose Sampling:通过姿态采样技术,增强半身细节和面部及手势的表现力。
- Audio Diffusion:利用音频扩散技术,进一步提升动画的自然性和连贯性。
(2) Head Partial Attention:
为了弥补半身数据的稀缺,使用头部部分注意力机制,将头像数据无缝集成到训练框架中。在推理阶段,这一部分可以被省略,从而提供一个“免费午餐”给动画生成。
(3) Phase-specific Denoising Loss:
设计了特定阶段的去噪损失函数,分别指导动画在不同阶段的运动、细节和低层次质量。
核心亮点
(1) 数字人全方位进化
相比 V1 仅支持数字人,V2 将动画范围扩展到自定义人物,提供从头部到身体的完整动画表现:
- 表情与嘴型同步:输入一段音频,即可让虚拟角色匹配语音内容精准“开口说话”。通过音频驱动,实现口型与语音内容的高度同步,使虚拟角色的对话更加自然和真实。
- 头部与手势动作:通过参考手势视频生成连贯自然的动作效果。不仅限于面部表情,还包括头部和手势动作,打造更具沉浸感的数字人。动作流畅、自然,增强了虚拟角色的表现力和互动性。
(2) 简单易用
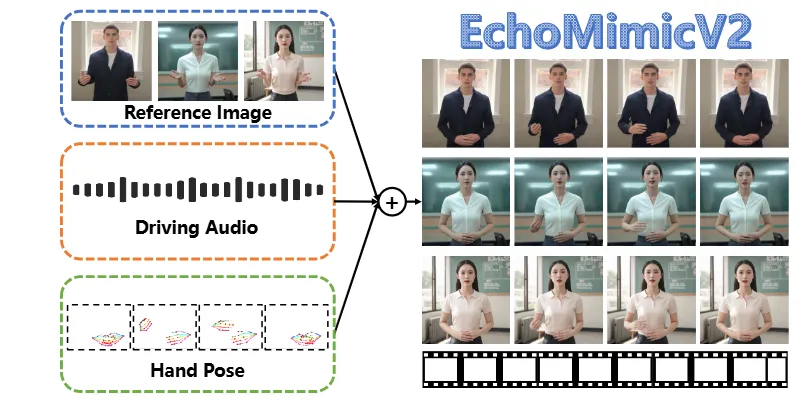
只需提供以下三项内容,即可轻松生成高质量动画:
- 参考图像:用户上传任意照片作为虚拟角色的基础。参考图像可以是任意人物的照片,系统会根据该图像生成相应的虚拟角色。
- 音频剪辑:用于驱动嘴型和表情动画。输入的音频内容将直接影响虚拟角色的口型和表情,确保动画与语音内容的高度一致。
- 手势视频:为动画添加丰富的身体动作与动态细节。手势视频可以是任何包含手势动作的视频片段,系统会参考这些动作生成自然的身体动作。
快速上手
(1) 硬件要求
- 英伟达显卡:建议使用16GB显存,较小的显卡也能运行,但是性能会有所下降。
- Python版本:需要Python 3.10及以上版本。
(2) 部署步骤
① 下载项目包:
git clone https://github.com/antgroup/echomimic_v2
cd echomimic_v2② 设置python环境
- 测试系统环境:CentOS 7.2 / Ubuntu 22.04
- 测试GPU:A100(80G) / RTX4090D (24G) / V100(16G)
- 测试Python版本:3.8 / 3.10 / 3.11
创建conda环境(推荐)
conda create -n echomimic python=3.10
conda activate echomimic③ 安装依赖包
pip install pip -U
pip install torch==2.5.1 torchvision==0.20.1 torchaudio==2.5.1 xformers==0.0.28.post3 --index-url https://download.pytorch.org/whl/cu124
pip install torchao --index-url https://download.pytorch.org/whl/nightly/cu124
pip install -r requirements.txt
pip install --no-deps facenet_pytorch==2.6.0④下载和配置ffmpeg-static
wget https://johnvansickle.com/ffmpeg/releases/ffmpeg-release-64bit-static.tar.xz
tar -xvf ffmpeg-release-64bit-static.tar.xz
export FFMPEG_PATH=$(pwd)/ffmpeg-4.4-amd64-static⑤ 下载预训练权重模型
git lfs install
git clone https://huggingface.co/BadToBest/EchoMimicV2 pretrained_weights预训练权重目录结构
./pretrained_weights/
├── denoising_unet.pth
├── reference_unet.pth
├── motion_module.pth
├── pose_encoder.pth
├── sd-vae-ft-mse
│ └── ...
├── sd-image-variations-diffusers
│ └── ...
└── audio_processor
└── tiny.pt⑥ 启动Gradio界面
python app.py运行上述命令后,会启动一个Gradio界面。
- 在Gradio界面上,可以上传一张参考图像(你自己的头像或任何人物照片)。
- 上传一段音频剪辑,EchoMimic V2会根据音频制作出相应的口型同步动画。
- 上传一段手势视频,系统会生成与音频相匹配的身体动作。
- 系统将根据提供的参考图像、音频剪辑和手势视频生成完整的动画视频。
(3) 附录
- GitHub仓库:https://github.com/antgroup/echomimic_v2
- 在线Demo:https://huggingface.co/spaces/fffiloni/echomimic-v2
实例效果