在当今软件开发领域,Java 虚拟机(JVM)作为运行 Java 应用程序的核心组件,其性能优化显得尤为重要。无论是大型企业应用还是微服务架构,高效的 JVM 调优都能显著提升系统的响应速度、吞吐量以及稳定性。本文将从理论到实践,全面解析 JVM 的工作原理及其关键配置参数,并通过实际案例分享如何进行有效的性能调优。无论您是初学者还是有经验的开发者,相信本文都能为您带来新的启发与收获。

一、JVM常见命令介绍
篇幅原因关于JVM常见指令的使用与介绍,需要了解的读者可以移步参考笔者写的这篇文章《JVM指令集概览:基础与应用》
二、详解JVM的GC
1.定位GC情况的两种方式
获取GC日志方式大抵有两种,第一种就是设定JVM参数在程序启动时查看,具体的命令参数为:
-XX:+PrintGCDetails # 打印GC日志
-XX:+PrintGCTimeStamps # 打印每一次触发GC时发生的时间第二种则是在服务器上监控:使用jstat查看,如下所示,命令格式为jstat -gc pid 输出间隔时长 输出次数,例如笔者希望每隔1秒输出1次,并且打印5次,对应的指令如下:
jstat -gc 21608 1000 52.拆解与分析JVM的GC日志
为了演示如何查看GC日志,笔者给出下面这样一段代码并结合JVM参数配置(后文会给到)展示JVM如何进行垃圾回收,注意笔者这里新生代的垃圾回收算法是ParNew而老年代用到的是CMS:
public static void main(String[] args) {
//分配1M内存空间
byte[] bytes = new byte[1024 * 1024];
//触发minor gc,剩余512k,然后将1M空间存放至新生代,堆空间大约剩下1.5M
bytes = new byte[1024 * 1024];
//分配至新生代约2.5M
bytes = new byte[1024 * 1024];
//新生代空间不足,触发full gc,新生代空间全回收,并执行CMS GC,完成后将对象存放至新生代
byte[] byte2 = new byte[2 * 1024 * 1024];
}对应我们也给出如下JVM配置参数指明新生代、老年代堆空间大小为5M,并指明新生代Eden和survivor区的比例为8:1:1,同时我们也指定的新生代和老年代垃圾回收算法分别是ParNewGC和CMS:
-XX:NewSize=5M -XX:MaxNewSize=5M -XX:InitialHeapSize=10M -XX:MaxHeapSize=10M -XX:SurvivorRatio=8 -XX:PretenureSizeThreshold=10M -XX:+UseParNewGC -XX:+UseConcMarkSweepGC -XX:+PrintGCDetails -XX:+PrintGCTimeStamps-XX:NewSize=5M -XX:MaxNewSize=5M -XX:InitialHeapSize=10M -XX:MaxHeapSize=10M -XX:SurvivorRatio=8 -XX:PretenureSizeThreshold=10M -XX:+UseParNewGC -XX:+UseConcMarkSweepGC -XX:+PrintGCDetails -XX:+PrintGCTimeStamps对应的含义如下,读者可自行参阅:
-XX:NewSize=5M:设置新生代的初始大小为 5MB。
-XX:MaxNewSize=5M:设置新生代的最大大小为 5MB。
-XX:InitialHeapSize=10M:设置 JVM 堆的初始大小为 10MB。
-XX:MaxHeapSize=10M:设置 JVM 堆的最大大小为 10MB。
-XX:SurvivorRatio=8:设置 Eden 区与 Survivor 区的比例为 8,即 Eden 占用 8/10 的新生代空间,两个 Survivor 各占 1/10。
-XX:PretenureSizeThreshold=10M:设置对象直接进入老年代的阈值为 10MB,超过这个大小的对象会直接分配到老年代。
-XX:+UseParNewGC:启用并行新生成收集器(Parallel New Generation Collector),用于多线程环境下的新生代垃圾回收。
-XX:+UseConcMarkSweepGC:启用并发标记清除收集器(Concurrent Mark Sweep Collector),用于多线程环境下的老年代垃圾回收。
-XX:+PrintGCDetails:打印详细的垃圾回收日志信息。
-XX:+PrintGCTimeStamps:在垃圾回收日志中添加时间戳。此时我们就以逐行执行的方式讲解GC过程,首先代码执行到byte[] bytes = new byte[1024 * 1024];,此时新生代空间充裕,没有任何输出。 执行第二行代码bytes = new byte[1024 * 1024];再次进程内存分配时,发现新生代空间不足出现以此minor gc,对应输出结果如下,我们大体可以看出GC原因是Allocation Failure即新生代不能分配对象,触发一次新生代GC,新生代GC前后空间由3348K变为512K,整堆空间由3348K变为1692K,最后输出了GC耗时、系统响应耗时以及应用程序暂停时间:
2.938: [GC (Allocation Failure) 2.938: [ParNew: 3348K->512K(4608K), 0.0016244 secs] 3348K->1692K(9728K), 0.0016904 secs] [Times: user=0.00 sys=0.00, real=0.00 secs] 完成上述GC,将1M的数组存放至新生代,此时新生代的堆空间大约是1M:
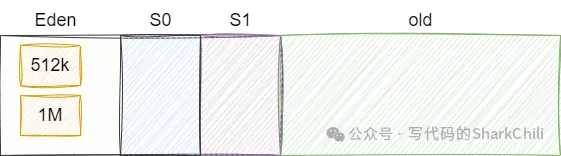
然后第三行再次分配数组,新生代空间充裕,直接存入:
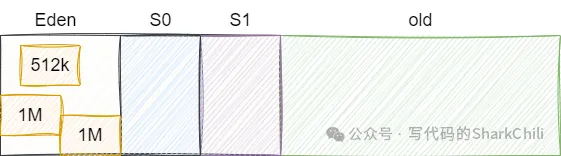
最后一次分配2M数组时,新生代空间不足且空间分配担保失败,直接触发FULL GC,从日志中我们可以看到minor gc直接将上述的所有字节数组都回收了:
9.689: [GC (Allocation Failure) 9.689: [ParNew: 2626K->0K(4608K), 0.0021520 secs] 3806K->2746K(9728K), 0.0021903 secs] [Times: user=0.00 sys=0.00, real=0.00 secs]最后就是CMS老年代GC,首先进行初始标记阶段该阶段为STW并找到所有的GC root,从日志中我们看到老年代使用的容量为2718K且总容量为5120K,后面的4766K(9728K)标记为当前堆的实际大小和总容量:
2.057: [GC (CMS Initial Mark) [1 CMS-initial-mark: 2718K(5120K)] 4766K(9728K), 0.0005690 secs] [Times: user=0.00 sys=0.00, real=0.00 secs] 然后进入并发标记阶段该阶段不会STW,先是CMS-concurrent-mark标记gc root可达对象,然后CMS-concurrent-preclean重新并发扫描进入到老年代的对象,最后时CMS-concurrent-abortable-preclean该阶段并发运行至eden区空间占用率达到满意:
2.058: [CMS-concurrent-mark-start]
2.059: [CMS-concurrent-mark: 0.001/0.001 secs] [Times: user=0.00 sys=0.00, real=0.00 secs]
2.059: [CMS-concurrent-preclean-start]
2.059: [CMS-concurrent-preclean: 0.000/0.000 secs] [Times: user=0.00 sys=0.00, real=0.00 secs]
2.059: [CMS-concurrent-abortable-preclean-start]
CMS: abort preclean due to time 7.163: [CMS-concurrent-abortable-preclean: 0.005/5.105 secs] [Times: user=0.00 sys=0.00, real=5.10 secs] 最后就到了最终标记阶段,该阶段会STW,从日志输出可以看出新生代占用2048k,当前这个重新标记阶段Rescan 花费了0.0004620 secs,其余就是处理弱引用、卸载无用的类以及清理元数据等花费时间和耗时:
7.164: [GC (CMS Final Remark) [YG occupancy: 2048 K (4608 K)]7.164: [Rescan (parallel) , 0.0004620 secs]7.164: [weak refs processing, 0.0001727 secs]7.164: [class unloading, 0.0005772 secs]7.165: [scrub symbol table, 0.0011975 secs]7.166: [scrub string table, 0.0003404 secs][1 CMS-remark: 2718K(5120K)] 4766K(9728K), 0.0030256 secs] [Times: user=0.00 sys=0.00, real=0.00 secs]最后就是并发的清理垃圾会重置标记,等待下一个周期的GC:
7.167: [CMS-concurrent-sweep-start]
7.168: [CMS-concurrent-sweep: 0.001/0.001 secs] [Times: user=0.00 sys=0.00, real=0.00 secs]
7.168: [CMS-concurrent-reset-start]
7.168: [CMS-concurrent-reset: 0.000/0.000 secs] [Times: user=0.00 sys=0.00, real=0.00 secs] 最后我们查看内存使用情况可以看到,新生代的2M就是我们最后分配的数组,在eden区,而老年代使用了1677K:
Heap
par new generation total 4608K, used 2089K [0x00000000ff600000, 0x00000000ffb00000, 0x00000000ffb00000)
eden space 4096K, 51% used [0x00000000ff600000, 0x00000000ff80a558, 0x00000000ffa00000)
from space 512K, 0% used [0x00000000ffa00000, 0x00000000ffa00000, 0x00000000ffa80000)
to space 512K, 0% used [0x00000000ffa80000, 0x00000000ffa80000, 0x00000000ffb00000)
concurrent mark-sweep generation total 5120K, used 1677K [0x00000000ffb00000, 0x0000000100000000, 0x0000000100000000)
Metaspace used 3124K, capacity 4486K, committed 4864K, reserved 1056768K
class space used 327K, capacity 386K, committed 512K, reserved 1048576K三、了解JVM几种GC的区别
- Minor GC:发生在年轻代的空间回收,包含eden和survivor,也叫做Young GC。
- Major GC:在老年代堆区进行空间回收。
- Full GC:清理所有堆区的内存空间的垃圾内存,包括年轻代和老年代。
四、频繁的 minor gc 和major gc
1.问题复现
我们尝试编写一个程序,设置该程序的堆内存新生代为5M,按照8:1:1的比例分配,这也就意为着Eden区内存大小为4M,然后S区分别是512K,这也就意味着在待分配对象加Eden区堆空间超过4M就会触发minor gc:
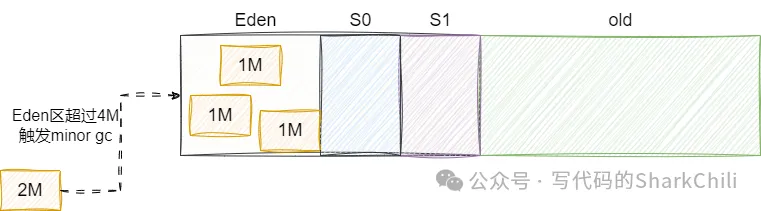
基于上述说法,我们给出下面这段代码:
public static void main(String[] args) throws Exception {
while (true) {
//分配3M数组
byte[] bytes = new byte[1024 * 1024];
bytes = new byte[1024 * 1024];
bytes = new byte[1024 * 1024];
//创建2M的新对象触发GC
byte[] byte2 = new byte[2 * 1024 * 1024];
Thread.sleep(1000);
}
}为了演示年轻代的回收行为,我们需要在对这个应用程序的年轻代堆内存改为5M,且Eden区和S区的比例为8:1:1,同时也打印GC日志信息:
-XX:NewSize=5M -XX:MaxNewSize=5M -XX:InitialHeapSize=10M -XX:MaxHeapSize=10M -XX:SurvivorRatio=8 -XX:PretenureSizeThreshold=10M -XX:+UseParNewGC -XX:+UseConcMarkSweepGC -XX:+PrintGCDetails -XX:+PrintGCTimeStamps输出结果如下,GC日志显示每秒基本都会触发一次Minor GC,进而间接导致频繁的major gc:

2.问题拆解与修复
结合我们的配置可知,我们频繁分配对象导致新生代进行频繁的GC,又因为S区大小无法容纳存活的对象,进而使得这些对象提前进入老年代,导致major GC也随之频繁,所以解决的办法也比较简单,按照等比例调整大堆空间,即将新生代堆空间调整至10M,保证S区各有2M空间以容纳新生代存活的对象:
-XX:NewSize=10M -XX:MaxNewSize=10M -XX:InitialHeapSize=100M -XX:MaxHeapSize=100M -XX:SurvivorRatio=8 -XX:PretenureSizeThreshold=10M -XX:+UseParNewGC -XX:+UseConcMarkSweepGC -XX:+PrintGCDetails -XX:+PrintGCTimeStamps可以看到经过调整之后,基本上Minor gc就能解决问题:

3.将年轻代空间调大,是否会更加耗时?
答案是不会的,原因有以下两点:
- JVM操作本质上都是内存操作,相对而言不会太慢。
- 我们将一次GC的时间拆分为t1和t2,t1是扫描年轻代空间是否有垃圾的时间,这个时间的几乎可以忽略不计。而t2则是将eden空间存活的对象复制到survivor区的时间,这个复制操作则是t1时间的10倍。
由此可以看出,避免耗时的正确做法是合理评估新生代堆空间,减少非必要的复制操作,所以说调整新生代的空间并不会导致进一步的耗时问题。
五、频繁的FULL GC
1.复现问题
我们现在模拟一个场景,我们的应用中有一个定时任务,这个定时任务每隔1s会想另一个定时任务线程池中提交100个任务,每个任务都会针对Obj 对象进行方法调用:
@Component
public class Task {
private static Logger logger = LoggerFactory.getLogger(Task.class);
private static final ScheduledThreadPoolExecutor executor =
new ScheduledThreadPoolExecutor(50,
new ThreadPoolExecutor.DiscardOldestPolicy());
private static class Obj {
private String name = "name";
private int age = 18;
private String gender = "man";
private LocalDate birthday = LocalDate.MAX;
public void func() {
//这个方法什么也不做
}
//返回count个Obj对象
private static List<Obj> getObjList(int count) {
List<Obj> objList = new ArrayList<>(count);
for (int i = 0; i != count; ++i) {
objList.add(new Obj());
}
return objList;
}
}
@Scheduled(cron = "0/1 * * * * ? ") //每1秒执行一次
public void execute() {
logger.info("1s一次定时任务");
//向线程池提交100个任务
Obj.getObjList(100).forEach(i -> executor.scheduleWithFixedDelay(
i::func, 2, 3, TimeUnit.SECONDS
));
}
}完成后我们设置下面这段JVM参数后,将其启动:
-Xms20M -Xmx20M -XX:+UseParNewGC -XX:+UseConcMarkSweepGC -XX:+PrintGCDetails -XX:+PrintGCTimeStamps不久后,控制台出现频繁的full gc,如果在生产环境,频繁的full gc导致stw会导致系统吞吐量下降:
.......
1288.133: [Full GC (Allocation Failure) 1288.133: [CMS1288.142: [CMS-concurrent-preclean: 0.012/0.012 secs] [Times: user=0.01 sys=0.00, real=0.01 secs]
(concurrent mode failure): 13695K->13695K(13696K), 0.0610050 secs] 19839K->19836K(19840K), [Metaspace: 29026K->29026K(1077248K)], 0.0610521 secs] [Times: user=0.06 sys=0.00, real=0.06 secs]
1288.258: [Full GC (Allocation Failure) 1288.258: [CMS: 13695K->13695K(13696K), 0.0612134 secs] 19839K->19836K(19840K), [Metaspace: 29026K->29026K(1077248K)], 0.0612676 secs] [Times: user=0.06 sys=0.00, real=0.06 secs]
1288.320: [GC (CMS Initial Mark) [1 CMS-initial-mark: 13695K(13696K)] 19836K(19840K), 0.0041303 secs] [Times: user=0.03 sys=0.00, real=0.00 secs]
......2.排查思路
我们定位到程序号后,使用jstat -gc pid10000 10观察其gc情况,可以看到每隔10s,就会增加大量的full gc:
S0C S1C S0U S1U EC EU OC OU MC MU CCSC CCSU YGC YGCT FGC FGCT GCT
640.0 640.0 0.0 640.0 5504.0 665.5 13696.0 11176.2 31488.0 28992.6 4352.0 3889.5 39 0.084 15 0.100 0.184
640.0 640.0 0.0 640.0 5504.0 1487.2 13696.0 11176.2 31488.0 28992.6 4352.0 3889.5 39 0.084 25 0.142 0.227
640.0 640.0 0.0 640.0 5504.0 1697.8 13696.0 11176.2 31488.0 28992.6 4352.0 3889.5 39 0.084 35 0.185 0.269
......再查看jmap -heap pid查看堆区使用情况,可以看到老年代的使用率还是蛮高的:
Attaching to process ID 26176, please wait...
Debugger attached successfully.
Server compiler detected.
JVM version is 25.212-b10
using parallel threads in the new generation.
using thread-local object allocation.
Concurrent Mark-Sweep GC
Heap Configuration:
MinHeapFreeRatio = 40
MaxHeapFreeRatio = 70
MaxHeapSize = 20971520 (20.0MB)
NewSize = 6946816 (6.625MB)
MaxNewSize = 6946816 (6.625MB)
OldSize = 14024704 (13.375MB)
NewRatio = 2
SurvivorRatio = 8
MetaspaceSize = 21807104 (20.796875MB)
CompressedClassSpaceSize = 1073741824 (1024.0MB)
MaxMetaspaceSize = 17592186044415 MB
G1HeapRegionSize = 0 (0.0MB)
Heap Usage:
New Generation (Eden + 1 Survivor Space):
capacity = 6291456 (6.0MB)
used = 5088288 (4.852569580078125MB)
free = 1203168 (1.147430419921875MB)
80.87615966796875% used
Eden Space:
capacity = 5636096 (5.375MB)
used = 5088288 (4.852569580078125MB)
free = 547808 (0.522430419921875MB)
90.28036428052326% used
From Space:
capacity = 655360 (0.625MB)
used = 0 (0.0MB)
free = 655360 (0.625MB)
0.0% used
To Space:
capacity = 655360 (0.625MB)
used = 0 (0.0MB)
free = 655360 (0.625MB)
0.0% used
concurrent mark-sweep generation:
capacity = 14024704 (13.375MB)
used = 13819664 (13.179458618164062MB)
free = 205040 (0.1955413818359375MB)
98.53800836010514% used
12064 interned Strings occupying 1120288 bytes.在排除内存泄漏的问题后,我们通过jmap定位进程中导致是什么对象导致老年代堆区被大量占用:
jmap -histo 7476 | head -n 20可以看到前20名中的对象都是和定时任务相关,有一个Task$Obj对象非常抢眼,很明显就是因为它的数量过多导致的,此时我们就可以通过定位代码确定如何解决,常见方案无非是: 优化代码、增加空间两种方式,一般来说我们都会采用代码优化的方式去解决。
$
num #instances #bytes class name
----------------------------------------------
1: 50760 3654720 java.util.concurrent.ScheduledThreadPoolExecutor$ScheduledFutureTask
2: 30799 2901552 [C
3: 88986 2847552 java.util.concurrent.locks.AbstractQueuedSynchronizer$Node
4: 50700 1622400 com.example.jstackTest.Task$Obj
5: 50760 1218240 java.util.concurrent.Executors$RunnableAdapter
6: 50700 811200 com.example.jstackTest.Task$$Lambda$587/1605553313
7: 6391 707928 java.lang.Class
8: 29256 702144 java.lang.String
9: 13577 434464 java.util.concurrent.ConcurrentHashMap$Node
10: 6363 341016 [Ljava.lang.Object;
11: 1722 312440 [B
12: 3414 230424 [I
13: 4 210680 [Ljava.util.concurrent.RunnableScheduledFuture;
14: 5223 208920 java.util.LinkedHashMap$Entry
15: 2297 202136 java.lang.reflect.Method
16: 2262 193760 [Ljava.util.HashMap$Node;
17: 5668 181376 java.util.HashMap$Node而本次问题也很明显,任务是一个个提交到定时任务线程池中,是由于定时任务队列DelayedWorkQueue不断堆积任务导致内存被打满。所以最终改成将一个批处理一次性提交到定时任务中立刻将这一批对象回收从而避免耗时任务堆积一堆对象:
@Scheduled(cron = "0/1 * * * * ? ") //每1秒执行一次
public void execute() {
logger.info("1s一次定时任务");
//向线程池提交100个任务
executor.scheduleWithFixedDelay(() -> {
Obj.getObjList(100).forEach(i -> i.func());
}, 2, 3, TimeUnit.SECONDS
);
}3.频繁FULL GC的原因和解决对策
总的来说原因可以频繁FULL GC分为3个:
- 用户频繁调用System.gc():这种情况需要修改代码即可,我们不该频繁调用这个方法的。
- 老年区空间过小:视情况适当扩大空间。
- 大对象过多:这种情况视情况决定是扩大老年代空间或者将大对象拆分。
一般来说,我们优先考虑调整堆内存空间,其次才是针对业务逻辑的代码处理进行更进一步的优化。