想必大家在面试的时候都被问到过数据库的分库分表应该怎么做。
分库分表指的是是将大型数据库分割成多个小型数据库或表格的技术,旨在通过分散数据来提升性能、增加可扩展性和简化管理。随着数据量的增长,传统的单体数据库可能会遭遇性能瓶颈,而分库分表能有效解决这些问题,支持系统线性扩展,确保高效的数据处理和响应速度,同时降低运维复杂度和成本。
今天我就分享一下我对此的一些见解。(如有错误,欢迎指正)
一、选择合适的数据库驱动和ORM框架(如果使用)
- 数据库驱动
Golang支持多种数据库驱动,如database/sql包提供了与数据库交互的标准接口。对于MySQL,常用的驱动是github.com/go - sql - driver/mysql。确保在项目中正确导入和初始化驱动,例如:
- ORM框架(可选)
如果项目使用ORM框架,如GORM,它可以简化数据库操作,包括分库分表的实现。GORM提供了方便的API来定义模型和执行数据库操作。导入GORM和相关的数据库驱动(以MySQL为例):
二、确定分库分表策略
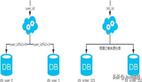
- 水平分表策略
对于用户表,按照用户ID进行哈希取模分表。假设要将用户数据分散到10张表中,可以计算user_id % 10,根据结果将用户数据存储到user_0、user_1等对应的表中。在查询用户数据时,同样先计算哈希值,然后确定要查询的表。
例如,对于抽奖记录,按照时间范围进行分表。可以每月创建一张新表,表名可以采用lottery_records_202401(表示2024年1月的抽奖记录)这样的格式。在代码中,需要根据抽奖时间来确定操作哪一张表。
按范围划分
按哈希划分
- 垂直分库策略
按照业务模块划分数据库。例如,将用户信息存储在一个数据库(user_db)中,抽奖规则存储在另一个数据库(lottery_rule_db)中,抽奖结果存储在第三个数据库(lottery_result_db)等。在代码中,需要根据操作的业务模块来选择不同的数据库连接。
三、实现分库分表逻辑
- 基于SQL操作实现(不使用ORM)
在查询用户数据时:
水平分表操作示例(按哈希划分用户表)
- 垂直分库操作示例(选择不同数据库连接)
假设已经有两个数据库连接userDB和lotteryRuleDB:
- 基于ORM框架(如GORM)实现
可以通过自定义GORM插件来实现分表逻辑。首先定义插件结构体:
水平分表操作示例(按哈希划分用户表)
在初始化GORM时注册这个插件:
- 垂直分库操作示例(选择不同数据库连接)
在GORM中,可以通过定义不同的数据库连接实例来操作不同的数据库。假设已经定义了userDB和lotteryRuleDB两个GORM数据库实例:
四、数据迁移和同步
- 初始数据迁移
当实施分库分表策略时,需要将原有数据迁移到新的数据库结构中。如果是水平分表,可以编写数据迁移脚本,按照分表策略将数据从旧表复制到新表。例如,对于按时间范围分表的抽奖记录:
- 数据同步机制
在分库分表后,可能需要建立数据同步机制,以确保数据的一致性。例如,在分布式系统中,当一个服务更新了用户表的数据,可能需要通过消息队列(如Kafka)将更新事件发送到其他相关服务,其他服务收到消息后对相应的分表进行更新操作。以下是一个简单的示例,使用Kafka进行数据同步:
五、性能测试和优化
- 性能测试
在实施分库分表后,需要对系统进行性能测试,以验证是否达到了预期的性能提升效果。可以使用性能测试工具,如go - bench来测试数据库操作的性能。例如,测试查询用户数据的性能:
- 优化调整
根据性能测试结果,对分库分表策略和代码进行优化调整。例如,如果发现某些查询操作仍然较慢,可以考虑优化索引策略、调整分片规则或者增加缓存机制等。如果是使用ORM框架,还可以优化ORM的配置,如调整GORM的Preload和Joins策略来减少不必要的数据库查询。
本文转载自微信公众号「王中阳」,作者「王中阳」,可以通过以下二维码关注。

转载本文请联系「王中阳」公众号。