今天给大家分享一个强大的算法模型,卷积神经网络。
卷积神经网络(CNN)是一类专门用于处理具有网格结构数据(如图像)的深度学习模型,广泛应用于图像处理、计算机视觉等领域。
CNN 通过模仿生物视觉系统的结构,通过层级化的卷积和池化操作,自动从输入数据中提取特征并进行分类或回归。CNN 的优势在于其自动特征提取能力,不需要人工设计特征,非常适合处理图像等高维数据。
 图片
图片
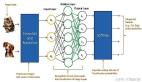
卷积神经网络的基本结构
卷积神经网络主要由卷积层、池化层和全连接层组成。
卷积层
卷积层是 CNN 的核心层,它的核心思想是通过卷积操作提取图像的局部特征。
在卷积操作中,使用一组(多个)可训练的卷积核(也称为滤波器)在输入图像上滑动,并与图像的局部区域进行卷积计算。
 图片
图片
每个卷积核提取图像的某一特征(如边缘、纹理、颜色等)。
卷积操作后的结果是一个特征图(Feature Map),表示了该特征在图像中的空间分布。
关键概念
- 卷积核(Filter/Kerner)
卷积核是一个小的矩阵,通常是 3x3 或 5x5。 - 卷积核数量
定义了卷积层的输出特征图的数量。每个卷积核产生一个特征图,多个卷积核可以提取多种不同的特征。 - 步幅(Stride)
步幅是卷积核在输入数据上滑动的步长。步幅决定了卷积操作的输出尺寸。步幅越大,输出特征图越小。 - 填充(Padding)
为了保持输入和输出特征图的尺寸一致,卷积操作通常会在输入数据的边缘添加额外的像素。这些额外的像素值通常设置为0。 - 卷积运算
卷积核与输入数据的每个局部区域进行逐元素相乘并求和的操作。
例如,3x3的卷积核在图像上滑动时,会与图像的每个 3x3 区域进行卷积计算,生成对应位置的特征图。
 图片
图片
池化层
池化层用于降低特征图的空间尺寸,减少计算量和参数数量,同时保留重要的特征信息
常用的池化操作有最大池化(Max Pooling)和平均池化(Average Pooling)。
- 最大池化(Max Pooling),从特定区域中选取最大值。
 图片
图片
- 平均池化(Average Pooling),取特定区域的平均值。
 图片
图片
全连接层
在卷积层和池化层提取了局部特征后,CNN 通常会通过一个或多个全连接层将这些特征映射到最终的输出。例如,图像分类问题中,全连接层的输出就是各个类别的预测值。
 图片
图片
CNN的优势
- 局部感知和权重共享
卷积操作利用局部感知特性,能够在图像的不同区域提取相似的特征(如边缘、角点等)。
卷积核在整个图像上共享权重,从而减少了参数的数量,避免了全连接网络中参数过多带来的问题。 - 平移不变性
由于卷积操作具有平移不变性,CNN 能够有效地识别图像中的目标,无论它们的位置如何。 - 自动特征学习
CNN 能够自动从原始数据中学习到特征,而无需人工设计特征。
通过卷积层、池化层和全连接层的逐层组合,网络能够从简单到复杂地学习图像的层次化特征。
案例分享
下面是一个使用卷积神经网络(CNN)进行手写数字识别的示例代码。
首先,我们加载 MNIST 数据集。
接下来我们将创建一个简单的 CNN 模型。
接下来,我们将使用训练数据来训练模型。
训练完成后,我们可以使用测试集评估模型的性能。
 图片
图片