译者 | 布加迪
审校 | 重楼
高质量的数据在数据科学中非常重要,但这类数据常常来自许多地方,格式混乱。一些数据来自数据库,另一些数据来自文件或网站。这些原始数据很难立即使用,因此我们需要先对其进行清理和组织。

ETL是帮助完成这项任务的过程。ETL代表提取、转换和加载。提取意味着从不同的来源收集数据。转换意味着清理和格式化数据。加载意味着将数据存储在数据库中以便访问。构建ETL管道使这个过程实现了自动化。稳健的ETL管道可以节省时间,并确保数据可靠。
我们在本文中将了解如何为数据科学项目构建ETL管道。
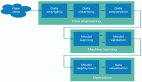
什么是ETL管道?
ETL管道将数据从源端移动到目标端。它分为三个阶段:
1. 提取:从多个来源(比如数据库或文件)收集数据。
2. 转换:清理和转换数据以供分析。
3. 加载:将清理后的数据存储在数据库或其他系统中。
为什么ETL管道很重要?
ETL管道很重要,有这几个原因:
- 数据质量:转换通过处理缺失值和修复错误来帮助清理数据。
- 数据可访问性:ETL管道将来自许多来源的数据放到一个地方,以便访问。
- 自动化:管道自动执行重复性任务,让数据科学家可以专注于分析。
现在,让我们用Python构建一个简单的ETL管道。
数据摄取
首先,我们需要得到数据。我们将从一个CSV文件中提取数据。
import pandas as pd
# Function to extract data from a CSV file
def extract_data(file_path):
try:
data = pd.read_csv(file_path)
print(f"Data extracted from {file_path}")
return data
except Exception as e:
print(f"Error in extraction: {e}")
return None
# Extract employee data
employee_data = extract_data('/content/employees_data.csv')
# Print the first few rows of the data
if employee_data is not None:
print(employee_data.head())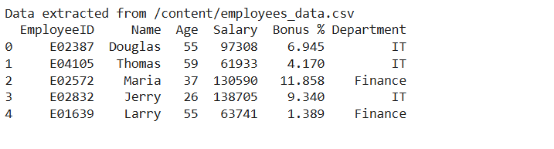
数据转换
收集数据后,我们需要对其进行转换。这意味着要清理数据,并确保其正确。我们还将数据更改为可用于分析的格式。下面是一些常见的转换:
- 处理缺失的数据:删除或填写缺失的值。
- 创建衍生的特征:创建新的列,比如工资区间或年龄组。
- 编码类别:将部门名称等数据更改为计算机可以使用的格式。
# Function to transform employee data
def transform_data(data):
try:
# Ensure salary and age are numeric and handle any errors
data['Salary'] = pd.to_numeric(data['Salary'], errors='coerce')
data['Age'] = pd.to_numeric(data['Age'], errors='coerce')
# Remove rows with missing values
data = data.dropna(subset=['Salary', 'Age', 'Department'])
# Create salary bands
data['Salary_band'] = pd.cut(data['Salary'], bins=[0, 60000, 90000, 120000, 1500000], labels=['Low', 'Medium', 'High', 'Very High'])
# Create age groups
data['Age_group'] = pd.cut(data['Age'], bins=[0, 30, 40, 50, 60], labels=['Young', 'Middle-aged', 'Senior', 'Older'])
# Convert department to categorical
data['Department'] = data['Department'].astype('category')
print("Data transformation complete")
return data
except Exception as e:
print(f"Error in transformation: {e}")
return None
employee_data = extract_employee_data('/content/employees_data.csv')
# Transform the employee data
if employee_data is not None:
transformed_employee_data = transform_data(employee_data)
# Print the first few rows of the transformed data
print(transformed_employee_data.head())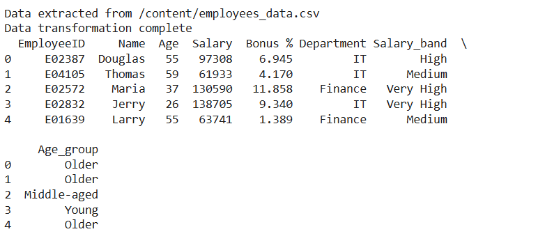
数据存储
最后一步是将数据加载到数据库中,使得用户易于搜索和分析。
在本文中,我们使用SQLite。它是一种存储数据的轻量级数据库。我们将在SQLite数据库中创建一个名为employees(员工)的表。然后,我们将转换后的数据插入到该表中。
import sqlite3
# Function to load transformed data into SQLite database
def load_data_to_db(data, db_name='employee_data.db'):
try:
# Connect to SQLite database (or create it if it doesn't exist)
conn = sqlite3.connect(db_name)
cursor = conn.cursor()
# Create table if it doesn't exist
cursor.execute('''
CREATE TABLE IF NOT EXISTS employees (
employee_id INTEGER PRIMARY KEY,
first_name TEXT,
last_name TEXT,
salary REAL,
age INTEGER,
department TEXT,
salary_band TEXT,
age_group TEXT
)
''')
# Insert data into the employees table
data.to_sql('employees', conn, if_exists='replace', index=False)
# Commit and close the connection
conn.commit()
print(f"Data loaded into {db_name} successfully")
# Query the data to verify it was loaded
query = "SELECT * FROM employees"
result = pd.read_sql(query, conn)
print("\nData loaded into the database:")
print(result.head()) # Print the first few rows of the data from the database
conn.close()
except Exception as e:
print(f"Error in loading data: {e}")
load_data_to_db(transformed_employee_data)
运行完整的ETL管道
现在我们已完成了提取、转换和加载等步骤,就可以将它们组合起来了。这将创建一个完整的ETL管道。该管道将获取员工数据,并清理和更改数据。最后,它将把数据保存在数据库中。
def run_etl_pipeline(file_path, db_name='employee_data.db'):
# Extract
data = extract_employee_data(file_path)
if data is not None:
# Transform
transformed_data = transform_employee_data(data)
if transformed_data is not None:
# Load
load_data_to_db(transformed_data, db_name)
# Run the ETL pipeline
run_etl_pipeline('/content/employees_data.csv', 'employee_data.db')现在大功告成了:我们的ETL管道已实现完毕,现在就可以执行了。
ETL管道的几个最佳实践
下面是需要遵循的几个最佳实践,以便构建高效可靠的ETL管道:
1. 利用模块化:将管道分解为更小的、可重用的函数。
2. 错误处理:在提取、转换或加载期间为日志问题添加错误处理机制。
3. 优化性能:为大型数据集优化查询和管理内存。
4. 自动化测试:自动测试转换和数据格式,以确保准确性。
结语
ETL管道是任何数据科学项目的关键。它们有助于处理和存储数据,以供进行准确的分析。我们演示了如何从CSV文件中获取数据,然后我们清理和更改了数据,最后我们将其保存在SQLite数据库中。
一个好的ETL管道可以确保数据井然有序。这种管道可加以改进,以处理更复杂的数据和存储需求。它有助于创建可扩展且可靠的数据解决方案。
原文标题:Developing Robust ETL Pipelines for Data Science Projects,作者:Jayita Gulati