













目标检测技术,这一受人类视觉能力启发的计算机视觉技术,已在数字图像和视频领域取得显著进展。YOLOv10,作为YOLO系列的最新力作,以其卓越的性能和效率,继续在目标检测领域保持领先地位。本文将探讨YOLOv10的技术特性、架构结构、优势和潜在劣势。

目标检测技术的进步不断推动着计算机视觉领域的发展。YOLO(You Only Look Once)系列算法以其快速准确的目标检测能力而闻名,其最新版本YOLOv10更是在性能和效率上取得了重大突破。2024年5月,清华大学的研究人员王等人(2024年)推出了YOLOv10算法,该算法通过双重标签分配和效率-准确性策略,有效降低了计算负荷并提升了性能。
YOLOv10的核心创新之一是引入了一致双重分配(Consistent Dual Assignments)的新方法,这一方法旨在克服在推理过程中用于过滤冗余预测的非最大抑制(NMS)的困难和不一致性。通过这种方式,YOLOv10在目标检测过程中消除了对NMS的需求,显著降低了检测延迟。为此,YOLOv10在头部区域创建了一个结合一对一和一对多匹配方法的双重标签分配策略。
在一对一匹配中,每个真实样本都被分配一个预测,从而消除了对NMS的需求,并实现了端到端的分布。这种方法虽然可能导致监督较弱,影响准确性和收敛速度,但在一对多匹配中,提供了更丰富的监督信号,尽管推理过程仍需要NMS。在训练期间,一对一和一对多的头部结构被共同优化,使用一对多匹配的丰富内容进行监督,而推理仅使用一对一匹配的头部,绕过了NMS的需求,实现了高效率且无需额外推理成本。

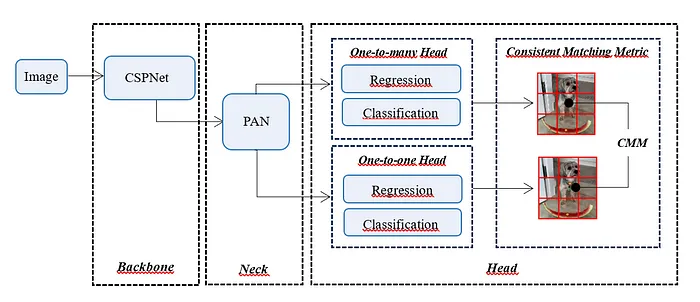
一致匹配度量(Consistent Matching Metric)是双重标签分配策略的关键组成部分,用于评估预测和实际实例之间的一致性。在这个度量中,σ和β分别代表语义预测和位置回归任务,s表示预测的连接点是否在样本内,p代表分类得分。这个度量包括分类得分和预测与实际边界框之间的IoU(交集比并集),通过将一对一头部的监督与一对多头部的监督对齐,提高了模型在推理期间的预测质量。
YOLOv10算法的第二个策略是效率-准确性策略,该策略优化了各个组件以减少计算负荷,同时提高性能。
- 轻量级分类头部显著降低了与以前版本相比的计算成本,这得益于头部的3x3和1x1卷积层。
- 空间-通道解耦下采样允许分别处理图像的不同通道(例如RGB通道),以更好地分析每个通道的空间特征,显著降低了计算成本和参数数量,同时保留了更多信息。
- Rank-Guided 块设计通过简化整体架构来提高计算效率,优化了这些块在模型中的放置,增加了模型的学习容量,减少了处理时间,并带来了整体更好的性能。
- Large-Kernel 卷积可以一次处理更大的像素区域,提取更深层次的特征,更好地捕捉远距离像素之间的连接,并将更多的像素合并到单个特征图中,以创建更丰富、更密集的特征图。
然而,这种技术在计算上昂贵且容易过拟合,需要精心设计和优化。部分自注意力模块帮助模型关注输入数据中的相关特征,提高了其准确检测和分类对象的能力。
Tips: YOLOv10的改进和创新包括设计了一个无需NMS的模型,通过使用双重标签分配策略和效率-准确性策略减轻了计算负担并提高了准确性,并通过在头部区域使用一致匹配度量提高了模型的推理质量。
YOLOv10的优势在于提出了新的战略和技术,在低计算量的情况下实现了高准确性。为了客观比较YOLO系列模型,我们分析了原始论文中的性能结果,确保使用的是共同的数据集和评估指标。从YOLO v2开始,COCO 2017数据集被用作所有YOLO版本的训练和测试集。每个模型都使用来自同一数据集的640张图像进行测试。根据这些结果,观察到模型性能随时间提高,并从YOLOv5开始设计不同大小的模型。下表显示了v5及以后版本的性能结果。
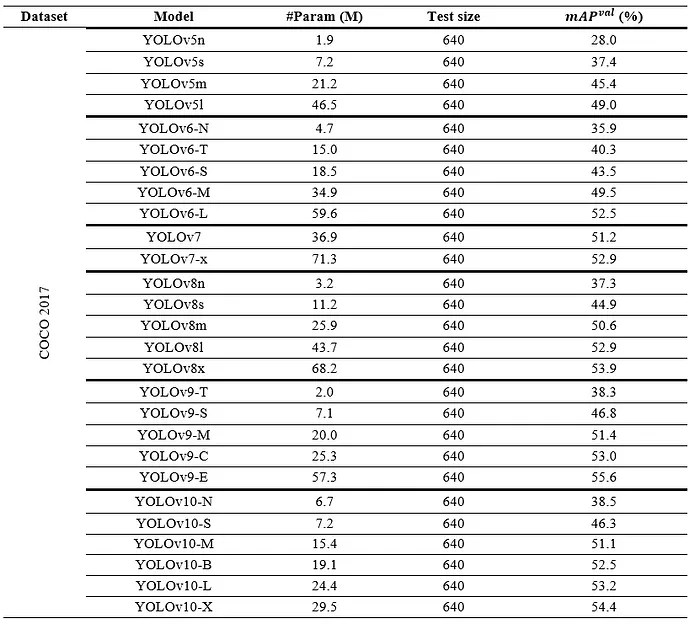
观察到模型的参数数量和结构变化影响模型性能。例如,YOLOv6-N模型有35.9%的mAP和4.7M参数,而YOLOv9-T有38.3%的mAP和2.0M参数。两者都有各自版本中最低的参数。然而,YOLOv9-T比YOLOv6-N快约2倍,因为它的参数数量大约少了2倍,并且成功率高约2.5%。这主要是由于在模型结构中添加和修改的算法。
结论
YOLOv10以其创新的架构和策略,为实时端到端目标检测领域带来了新的突破。其无需NMS的设计、双重标签分配策略和效率-准确性策略,不仅提高了检测效率,还保持了高准确性。随着YOLO系列的不断发展,我们可以期待未来在目标检测技术方面取得更多突破。


























