












目标检测在计算机视觉中是一个至关重要的任务,而YOLO(You Only Look Once)因其速度和准确性而脱颖而出。在本指南中,我将带你了解如何微调一个YOLO模型,以检测各种道路标志和物体,例如:
- 车辆
- 行人
- 不同颜色的交通灯
- 人行横道
- 速度限制标志
- 禁止标志
- 警告标志

本指南适用于使用Linux的用户。对于Windows用户,Poetry和Cuda的安装可能会有所不同。如果你只是想尝试完成的模型,请选择选项1。如果你想自己训练模型,请选择选项2。
选项1:测试完成的模型
要测试完成的模型,请按照以下步骤操作:
(1) 克隆仓库:
将GitHub上的仓库复制到你的本地机器。
git clone https://github.com/Mkoek213/road_detection_model.git(2) 检查文件夹:
- Models文件夹包含你可以用来的已训练模型。
- test_images文件夹包括用于评估的测试视频。
(3) 运行代码:
导航到road_detection_model/road_detection_model目录,其中包含live.py。
在live.py中,你会发现代码可以运行模型,无论是在实时网络摄像头输入还是静态视频文件上。你可以将设置参数设置为'live'用于网络摄像头或'static'用于视频,并根据需要提供你的视频文件路径。该脚本还包括指定模型路径、类别名称和其他参数的说明。
选项2:自己训练模型
按照以下步骤设置你的环境,下载必要的数据,处理它,并训练你的模型。
1. 设置你的环境
安装Poetry
Poetry是Python中用于依赖管理和打包的工具。它将帮助我们有效地管理项目的依赖关系。Pipx用于在虚拟环境中隔离的同时全局安装Python CLI应用程序。
#Install Poetry
pipx install poetry使用Poetry安装依赖项:
# Clone project's repository from Github
git clone https://github.com/Mkoek213/road_detection_model.git
cd road_detection_model # navigate to folder
poetry install # poetry will install all dependencies
poetry shell # this command starts the virtual environment with the downloaded dependencies安装的项目将包含以下内容:
├── notebooks
│ ├── data
│ │ └── bdd100k.names
│ └── data_processing.ipynb
├── poetry.lock
├── pyproject.toml
├── README.md
└── road_detection_model
├── data_finetune.yaml
├── data.yaml
├── __init__.py
├── live.py
├── Models
│ ├── fine_tuned_yolov8s.pt
│ ├── pre_trained_yolov8s.pt
│ └── yolov8n.pt
├── runs
│ ├── detect
│ │ ├── train
│ │ ├── train2
│ │ ├── val
│ │ └── val2
│ └── fine_tuning
│ ├── train
│ ├── train2
│ └── train3
├── test_images
│ └── test_film.mp4
├── train.py
└── validate.py将虚拟环境添加到Python内核。要在Jupyter笔记本中使用你的虚拟环境,你需要按照以下步骤操作:
python -m pip install --upgrade pip
pip install ipykernel
python -m ipykernel install --user --name="your venv name"确保你将内核更改为虚拟环境,如下所示:
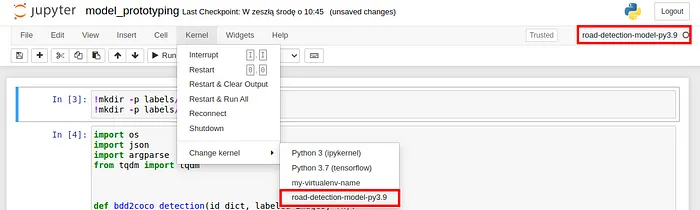
(2) 安装CUDA和cuDNN进行GPU训练
然后你需要安装CUDA和cuDNN以在GPU上训练模型,这将显著加速整个过程。
- 安装CUDA Toolkit:访问NVIDIA CUDA Toolkit下载页面,选择你的操作系统。按照提供的安装说明进行。
- 安装cuDNN:访问NVIDIA cuDNN下载页面,下载与你的CUDA安装兼容的版本。按照提供的安装说明进行。
2. 下载数据
下载连续预训练阶段所需的数据:下载模型连续预训练(在已经训练过的模型上进行迁移学习)所需的数据(来自汽车摄像头的公开可用图像,以及用于检测汽车、人员、交通标志等的标签):https://dl.cv.ethz.ch/bdd100k/data/
下载以下文件:
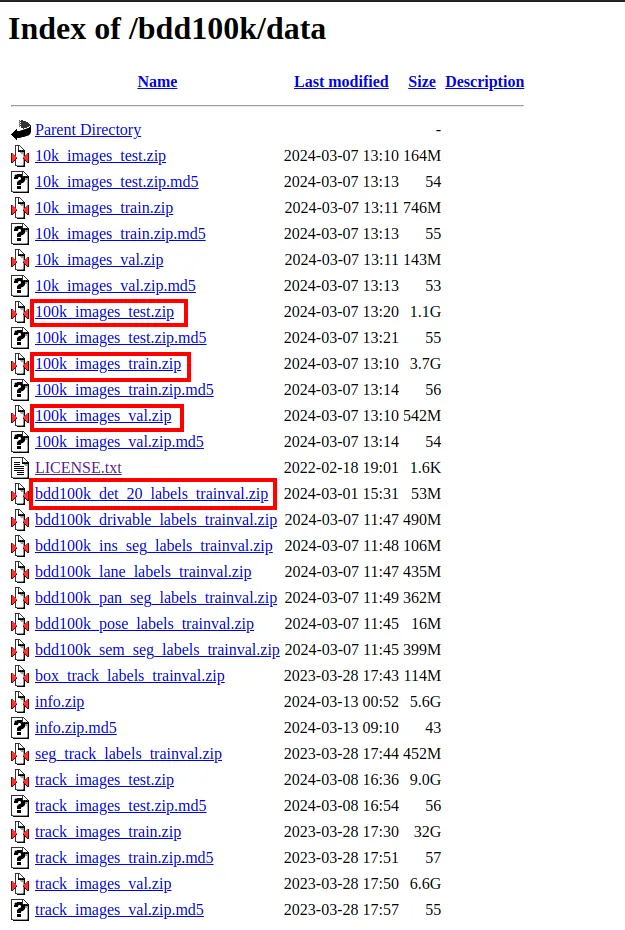
下载后,解压缩文件并将它们移动到/road_detection_model/notebooks/data 文件夹(在Linux上,你可以使用以下命令):
cd Downloads
unzip 100k_images_val.zip
unzip 100k_images_test.zip
unzip 100k_images_train.zip
unzip bdd100k_det_20_labels_trainval.zip
mv ~/Downloads/bdd100k ~/road_detection_model/notebooks/data/下载微调阶段所需的数据
你需要的微调阶段数据库,可以从Kaggle下载:https://www.kaggle.com/datasets/mikoajkoek/traffic-road-object-detection-polish-12k
下载后,解压缩文件并将它们移动到/road_detection_model/road_detection_model/datasets文件夹(在Linux上,你可以使用以下命令):
unzip archive.zip
mkdir -p ~/road_detection_model/road_detection_model/datasets
mv ~/Downloads/road_detection ~/road_detection_model/road_detection_model/datasets3. 处理数据
要使用下载的bdd100k数据库训练我们的模型,我们需要将标签和文件夹结构格式化为YOLO模型接受的格式。当使用Ultralytics YOLO格式时,按照以下方式组织你的训练和验证图像和标签:
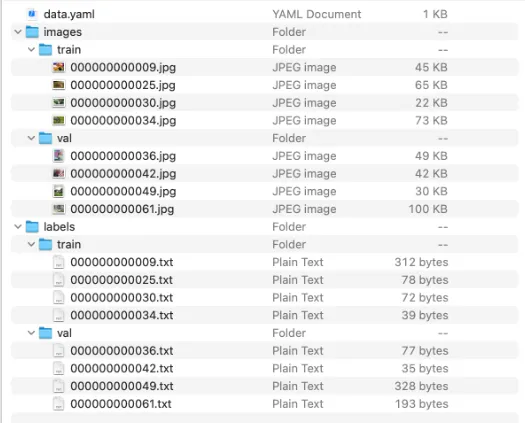
标签结构如下:
<class_id> <X> <Y> <Width> <Height>
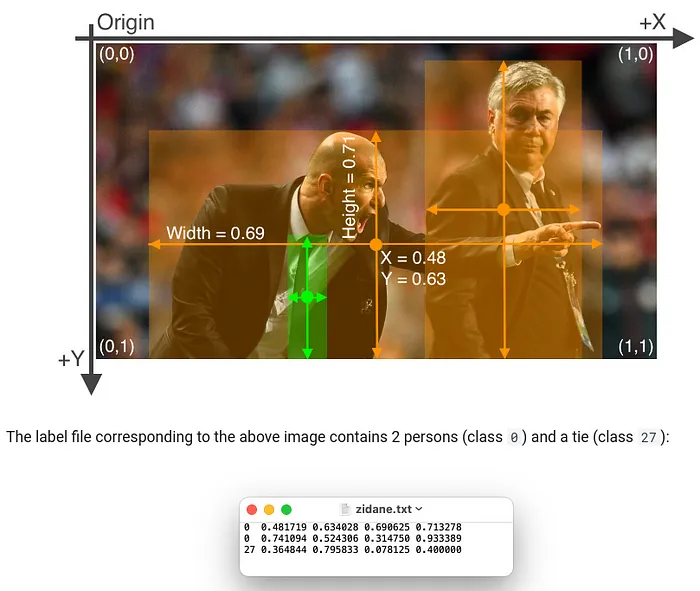
要准备BDD100k数据库数据以训练YOLO模型:
- 启动Jupyter Notebook:确保你激活了你打算用于这个项目的虚拟环境。
- 打开笔记本:导航到notebooks文件夹并打开名为data_processing.ipynb的文件。
- 编译代码:逐个执行笔记本单元格,确保每个函数编译并成功运行。特别注意coco_to_yolo函数:对于训练数据,设置配置并运行单元格。对于验证数据,在运行单元格之前,注释掉训练数据配置并取消注释验证数据配置。
按照这些步骤,BDD100k数据集将被处理并准备好用于YOLO模型训练。
4. 连续预训练YOLO模型
在road_detection_model/road_detection_model文件夹中,打开train.py文件。要执行连续预训练,取消注释标记为“Pre-training stage”的块,并注释掉标记为“Fine-tuning stage”的块。
使用time参数,你可以为训练设置特定时长。我训练模型42小时,结果是69个周期。你可以在road_detection_model/road_detection_model/runs/detect/train2文件夹中找到我用于训练的参数。
在训练期间,监控GPU使用情况很有帮助,因为模型训练应该大量使用GPU。你可以使用以下命令进行:
watch nvidia-smi # real-time statwatch nvidia-smi # real-time stat完成模型的选定指标
你可以在road_detection_model/road_detection_model/runs/detect/val目录中找到所有验证指标的已训练模型。
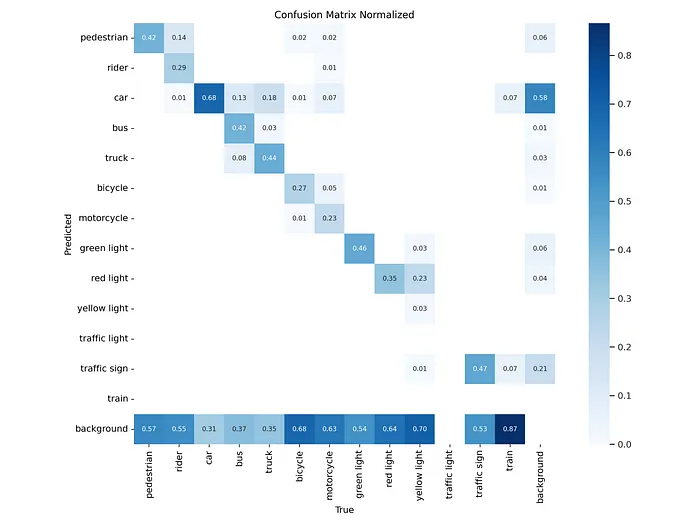
预训练阶段后的混淆矩阵
混淆矩阵显示模型对每种物体类型的分类准确性:
验证集的标注图像
标注图像显示模型在验证集上的预测带有边界框:

预训练后的模型性能指标
在road_detection_model/road_detection_model目录中,你会找到validate.py文件,它允许你在测试数据集上评估你的训练模型。
- 平均精度均值(mAP):衡量所有类别和IoU阈值的整体检测准确性。对于我们的模型,mAP是0.231
- IoU=0.50时的平均精度(AP50):在IoU阈值为0.50时的精度分数,为模型的准确性提供标准评估。我们模型的AP50是0.422
- F1分数:平衡精确度和召回率,提供单一的性能分数。所有类别的平均F1分数是0.438
5. 在自定义数据集上微调预训练的YOLO模型
在road_detection_model/road_detection_model文件夹中,打开train.py文件。要执行微调,取消注释标记为“Fine-tuning stage”的块,并注释掉标记为“Pre-training stage”的块。
由于在过去100个周期中没有改进(耐心参数),训练提前停止。在511周期观察到最佳结果,并在18小时内完成了611个周期。
完成模型的选定指标
可以在road_detection_model/road_detection_model/runs/detect/val2目录中找到所有验证指标的已训练模型。
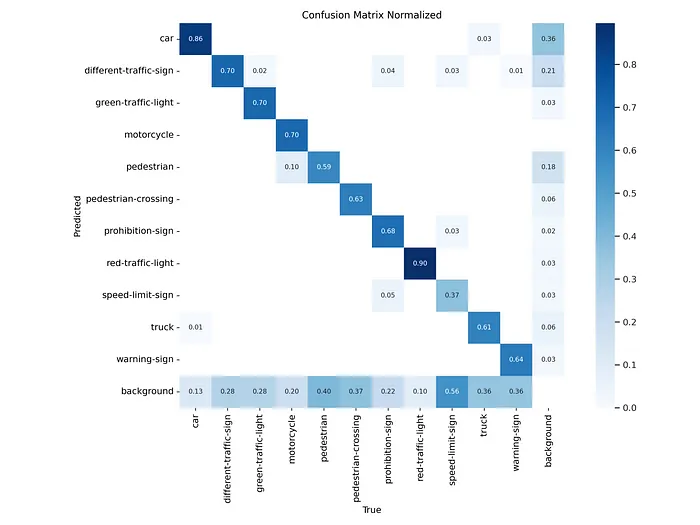
微调阶段后的混淆矩阵
混淆矩阵显示模型对每种物体类型的分类准确性。
验证集的标注图像
标注图像显示模型在验证集上的预测带有边界框:

微调后的模型性能指标
在road_detection_model/road_detection_model目录中,你会找到validate.py文件,它允许你在测试数据集上评估你的训练模型。
- 平均精度均值(mAP):衡量所有类别和IoU阈值的整体检测准确性。对于我们的模型,mAP是0.443
- IoU=0.50时的平均精度(AP50):在IoU阈值为0.50时的精度分数,为模型的准确性提供标准评估。我们模型的AP50是0.732
- F1分数:平衡精确度和召回率,提供单一的性能分数。所有类别的平均F1分数是0.732


























