













一、介绍
想象一下,家里有一个机器人助手。现在想象一下漫长一天后的混乱——衣服散落各处,玩具到处都是,各种物品都放错了地方。这个机器人如何识别和整理每一项物品,尤其是如果它以前从未见过这些物品中的一些?传统的目标检测器将难以完成这项任务。进入“YOLO World”,这是计算机视觉中一个革命性的新模型,承诺改变机器理解和与周围环境的互动方式。
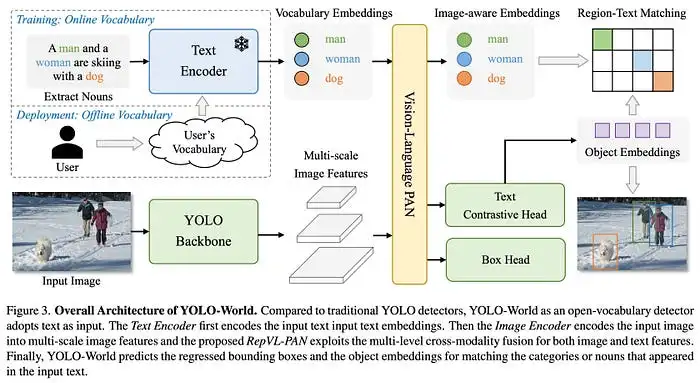
YOLO-World比领先的零样本目标检测器快20倍,体积小5倍。
- 传统目标检测器(Faster R-CNN、SSD、YOLO)——小而快,但只能检测其训练数据集中预定义的固定类别中的对象
- 开放词汇目标检测(GLIP和Grounding DINO)——灵活但计算密集,需要同时编码图像和文本进行预测
根据论文“YOLO-World: Real-Time Open-Vocabulary Object Detection”(https://arxiv.org/abs/2401.17270),YOLO-World的L版本达到了35.4 AP和52.0 FPS,S版本达到了26.2 AP和74.1 FPS。(在没有量化或TensorRT的V100上测量)
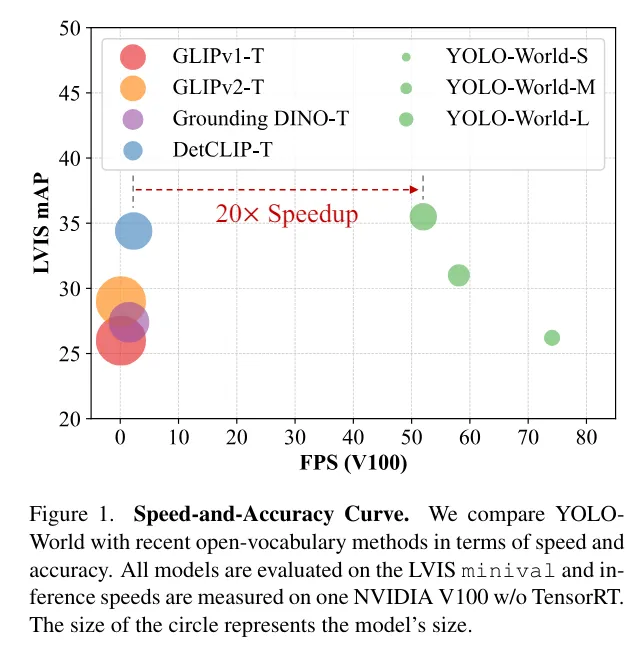
二、传统目标检测器存在的问题
像Faster R-CNN、SSD或原始YOLO这样的传统目标检测器,被构建来识别预定义类别集中的对象。例如,一个在COCO数据集上训练的模型可以检测多达80种不同的对象。然而,如果你引入一个新项目,例如,一种特定的玩具或一个独特的瓶子,模型就无法识别它。这种限制可以通过创建新数据集、注释图像和重新训练新模型来解决——这是一个耗时且成本高昂的过程。这种僵化阻碍了现实世界应用所需的适应性,其中各种新对象频繁出现。
1.引入YOLO World
YOLO World以其开放词汇方法打破了这些限制。将YOLO World想象成一个经验丰富的侦探,不仅拥有已知嫌疑人名单,还具备即时推断和学习的能力。与前辈不同,YOLO World可以识别它没有明确训练过的对象。YOLO World通过结合图像的视觉线索和文本描述来实现这一点,有效地从上下文和先验知识中学习。
2..YOLO World如何工作?
YOLO World的学习过程涉及研究充满图像和相应描述的大型数据集。例如,它可能会分析一张带有“带有蓝色毯子的床”标题的卧室图片。它还使用复杂的辅助模块,如理解描述“橙色条纹猫”的CLIP,以及将图像特征与这些描述链接起来以获得更深入理解的Reveal Pan。
当你向YOLO World展示一张照片时,它会执行基本的目标检测,识别熟悉的物品,如椅子和桌子。但它更进一步,通过突出不寻常或未知的对象,展示其开放词汇能力。想象一下,看着一个杂乱的房间,不仅仅是看到一个“椅子”或“桌子”,还能识别出“不寻常的玩具”或“稀有瓶子”,即使它以前没有见过这些特定的对象。

在LVIS上进行零样本推理的可视化结果。我们采用预训练的YOLO-World-L,并在COCO val2017上使用LVIS词汇表(包含1203个类别)进行推理
三、技术细节和架构
YOLO World的速度和效率的核心是其三个主要组件:
- YOLO检测器,
- CLIP文本编码器,
- 用于跨模态融合的定制网络。
YOLO检测器从图像中提取多尺度特征,而CLIP编码器将文本描述转换为嵌入。这些嵌入被缓存,使模型能够在实时中重用它们,而无需重新编码文本,显著提高了模型的速度。这种架构与之前的模型如Grounding DINO形成鲜明对比,后者虽然令人印象深刻,但由于严重依赖基于变换器的架构,处理图像的速度要慢得多。YOLO World更轻的基于CNN的主干和提示然后检测范式使其快20倍,同时保持高准确率。
实际应用和实验
YOLO World的多功能性在各种实际应用中大放异彩,从帮助例如机器人整理家庭到处理实时视频流。想象一个机器人助手有效地导航一个杂乱的房间,挑选和分类玩具、书籍和其他物品,全部实时进行,我们还没有它,所以我们还得再等等。
“遇见可以整理你的房间和分类你的洗衣物的AI机器人”
所以,因为我们没有机器人或真实的硬件设置,我们将在这一部分在Google Colab上运行我们的实验,以展示YOLO World通过处理图像和视频的能力。
设置涉及安装库,例如Roboflow Inference和Supervision,使用简单的pip install。
# supervision lib to be used for visualization
pip install -q supervision==0.19.0rc3
# inference
pip install -q inference-gpu[yolo-world]==0.9.13
# download some image and video examples
wget -P . -q https://media.roboflow.com/notebooks/examples/dog.jpeg
wget -P . -q https://media.roboflow.com/supervision/cookbooks/yellow-filling.mp4在这个例子中,一个简单的脚本展示了模型如何从类别列表中检测和注释对象。
import os
import cv2
import supervision as sv
from tqdm import tqdm
from inference.models import YOLOWorld
# model
model = YOLOWorld(model_id="yolo_world/l")
# define classes
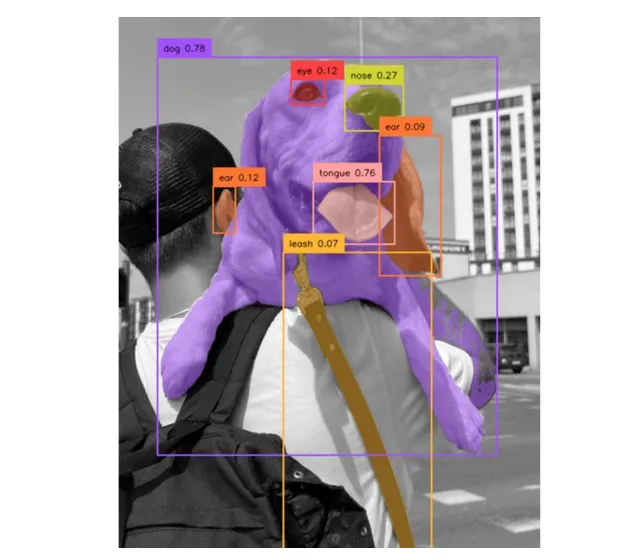
classes = ["person", "backpack", "dog", "eye", "nose", "ear", "tongue"]
model.set_classes(classes)
# read image and run model
image = cv2.imread(SOURCE_IMAGE_PATH)
results = model.infer(image)
detections = sv.Detections.from_inference(results)
# draw bbox and show results
BOUNDING_BOX_ANNOTATOR = sv.BoundingBoxAnnotator(thickness=2)
LABEL_ANNOTATOR = sv.LabelAnnotator(text_thickness=2, text_scale=1, text_color=sv.Color.BLACK)
annotated_image = image.copy()
annotated_image = BOUNDING_BOX_ANNOTATOR.annotate(annotated_image, detections)
annotated_image = LABEL_ANNOTATOR.annotate(annotated_image, detections)
sv.plot_image(annotated_image, (10, 10))调整置信度水平:
# ...
# same as above
# ...
image = cv2.imread(SOURCE_IMAGE_PATH)
results = model.infer(image, confidence=0.003)
detections = sv.Detections.from_inference(results)
labels = [
f"{classes[class_id]} {confidence:0.3f}"
for class_id, confidence
in zip(detections.class_id, detections.confidence)
]
annotated_image = image.copy()
annotated_image = BOUNDING_BOX_ANNOTATOR.annotate(annotated_image, detections)
annotated_image = LABEL_ANNOTATOR.annotate(annotated_image, detections, labels=labels)
sv.plot_image(annotated_image, (10, 10))使用非最大抑制(NMS)消除双重检测:
# ...
# same as above
# ...
image = cv2.imread(SOURCE_IMAGE_PATH)
results = model.infer(image, confidence=0.003)
detections = sv.Detections.from_inference(results).with_nms(threshold=0.1)
labels = [
f"{classes[class_id]} {confidence:0.3f}"
for class_id, confidence
in zip(detections.class_id, detections.confidence)
]
annotated_image = image.copy()
annotated_image = BOUNDING_BOX_ANNOTATOR.annotate(annotated_image, detections)
annotated_image = LABEL_ANNOTATOR.annotate(annotated_image, detections, labels=labels)
sv.plot_image(annotated_image, (10, 10))这是从三个不同的脚本获得的结果:

(左)默认设置(中)使用较低的置信度水平(右)使用较低的置信度水平和非最大抑制
四、视频处理
# ...
# same part as above + video loading
# ...
generator = sv.get_video_frames_generator(SOURCE_VIDEO_PATH)
frame = next(generator)
sv.plot_image(frame, (10, 10))
# update the classes to be used to detect the objects
classes = ["yellow filling"]
model.set_classes(classes)
results = model.infer(frame, confidence=0.002)
detections = sv.Detections.from_inference(results).with_nms(threshold=0.1)
annotated_image = frame.copy()
annotated_image = BOUNDING_BOX_ANNOTATOR.annotate(annotated_image, detections)
annotated_image = LABEL_ANNOTATOR.annotate(annotated_image, detections)
sv.plot_image(annotated_image, (10, 10))
video_info = sv.VideoInfo.from_video_path(SOURCE_VIDEO_PATH)
print(video_info)
width, height = video_info.resolution_wh
frame_area = width * height
print(frame_area)
results = model.infer(frame, confidence=0.002)
detections = sv.Detections.from_inference(results).with_nms(threshold=0.1)
print(detections.area)
detections = detections[(detections.area / frame_area) < 0.10]
annotated_image = frame.copy()
annotated_image = BOUNDING_BOX_ANNOTATOR.annotate(annotated_image, detections)
annotated_image = LABEL_ANNOTATOR.annotate(annotated_image, detections)
sv.plot_image(annotated_image, (10, 10))
TARGET_VIDEO_PATH = f"{HOME}/yellow-filling-output.mp4"
frame_generator = sv.get_video_frames_generator(SOURCE_VIDEO_PATH)
video_info = sv.VideoInfo.from_video_path(SOURCE_VIDEO_PATH)
width, height = video_info.resolution_wh
frame_area = width * height
frame_area
with sv.VideoSink(target_path=TARGET_VIDEO_PATH, video_info=video_info) as sink:
for frame in tqdm(frame_generator, total=video_info.total_frames):
results = model.infer(frame, confidence=0.002)
detections = sv.Detections.from_inference(results).with_nms(threshold=0.1)
detections = detections[(detections.area / frame_area) < 0.10]
annotated_frame = frame.copy()
annotated_frame = BOUNDING_BOX_ANNOTATOR.annotate(annotated_frame, detections)
annotated_frame = LABEL_ANNOTATOR.annotate(annotated_frame, detections)
sink.write_frame(annotated_frame)视频处理的结果:
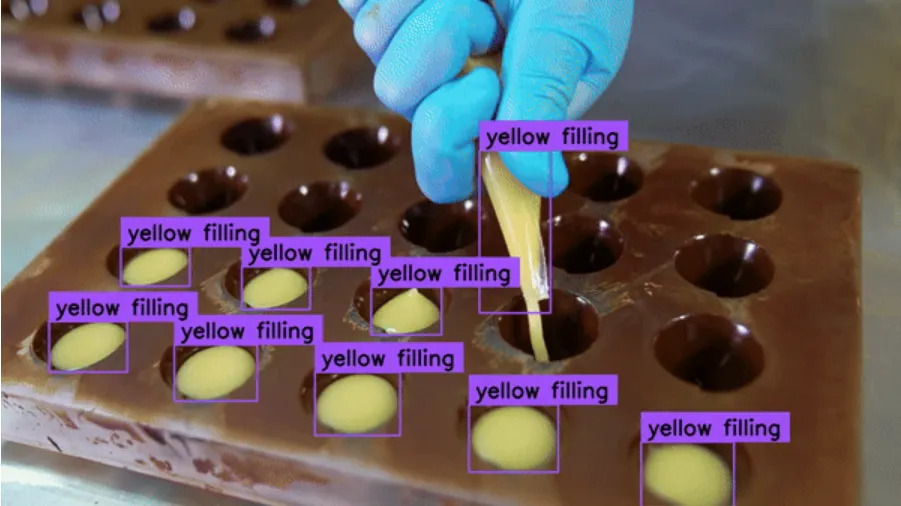
在Google Colab上,由Google Colab提供的GPU处理单个帧的时间约为65.25毫秒~15Hz
五、挑战和限制
尽管取得了进步,YOLO World仍然面临挑战。该模型虽然比前辈快,但与最先进的实时检测器相比,仍然存在延迟问题,例如与简单的YOLOv8相比。
因此,要实现YOLO World的实时处理,这将需要大量的计算资源,使其不太适合硬件能力有限的设置。虽然YOLO World擅长在其学习上下文中识别对象,但它可能会对对象进行错误分类或遗漏对象,特别是那些在COCO数据集之外的对象。
在精度至关重要且环境不受控制或高度可变的场景中,训练有自定义数据集的传统模型可能仍然是首选。
未来的可能性和创新
YOLO World的潜力超出了目标检测。将其与FastSAM或EfficientSAM等快速分割模型结合起来,可以创建一个比当前组合(如Grounding DINO和SAM)更高效的零样本分割流程。
这一创新为视频处理、自动背景移除和动态对象操作打开了大门。想象一个工厂车间,YOLO World不断监控和编目实时物品,或者一个视频编辑套件,其中不需要的背景元素被自动移除,这都要归功于这项技术。
YOLO-World + EfficientSAM — 零样本分割
六、有效YOLO-World提示的规则
以下是一套实用的规则和决策树,可帮助您在使用YOLO-World时找到最佳提示。
- 调整置信度水平:(规则)不要像其他模型那样依赖高置信度值(>80%)。尝试非常低的置信度水平(低至0.1%)。(示例)如果预测“吹风机”和“润肤霜”等对象,变化置信度阈值,并使用低至0.1%至15%。
- 添加空类别:(规则)包括空类别(非主要兴趣的次要对象)以提高检测准确性。(示例):要检测车牌并避免对汽车产生误报,即使不感兴趣检测汽车,也包括“汽车”作为类别。
- 使用两阶段工作流程:(规则)链式模型,第一阶段检测较大的对象,第二阶段专注于这些较大对象内的较小对象。(示例)首先,检测人脸,然后裁剪人脸并检测眼睛。
- 利用颜色:(规则)当描述性提示失败时,使用颜色提示。(示例)根据颜色差异检测“红色草莓”与“绿色草莓”。
- 在提示中描述大小:(规则)在提示中使用大小描述符以提高检测准确性。(示例)而不是“金属文件”,使用“小金属文件”来检测微小缺陷。
- 后处理改进:(规则)实施后处理步骤,以过滤掉大组预测或高置信度错误。(示例)通过为每个类别设置特定于类别的最大面积阈值来过滤预测。
七、结论
YOLO World代表了目标检测和人工智能领域的一个重要进步。它学习和适应的能力无需广泛的重新训练,使其成为从数据注释、家庭自动化到工业监控等各种应用的强大工具。虽然它有局限性,但其创新方法和未来发展的潜力使其成为值得探索的技术。YOLO-World可以用于边缘的零样本目标检测,也可以用于自动标记用于训练微调模型的图像。



























