今天,我们要聊聊一个酷炫的新工具——RAGViz,它就像是给RAG系统装了个X光机,让我们能透视那些神秘的内部工作机制。
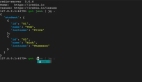
🐖 Query="为什么猪会飞?"的可视化:你会发现,那些生成的内容竟然没有基于任何上下文文档,这就是所谓的“内部幻觉”。
 图片
图片
🎨 RAGViz特性和用例
- 注意力可视化:RAGViz用高亮显示和颜色强度来告诉你,生成的标记序列对输入标记有多关注。就像是在说:“看这里,看这里,这些是我最关心的部分!”
- 文档级别的关注度:它不仅告诉你每个检索段落的关注度,还给你一个累积的文档级别注意力分数。就像是给你一个“关注度排行榜”,让你知道哪些段落是“人气王”。
- 拖动选择用户界面:这个功能就像是给你一个遥控器,让你可以轻松检查任何标记序列的累积关注度。想检查哪里就检查哪里,是不是很方便?
- 文档切换功能:这个功能让你可以像玩拼图一样,选择在构建答案上下文时省略特定的标记和文档,然后比较一下,看看添加或移除它们对LLM输出的影响。
- 自定义上下文文档数量:你可以指定从数据集中检索的相关文档片段的数量。就像是在餐厅点菜,想点多少吃多少。
- API密钥认证:RAGViz实现了HTTP请求上的中间件功能,确保你的请求经过适当的认证。就像是给你的网络请求穿上了一件“正装”。
🔍 在使用文档切换功能时,对选定的标记序列进行注意力可视化
这个功能就像是给你的文档来了个“X光透视”,让你清楚地看到哪些部分是LLM的“心头好”。
 图片
图片
🕵️♂️ 演示了RAGViz识别和调试外部幻觉的能力
RAGViz不仅能帮你看到内部幻觉,还能帮你识别和调试外部幻觉。就像是给你的AI系统装了个“幻觉探测器”。
 图片
图片
🏗️ RAGViz系统架构
RAGViz的系统架构就像是个精心设计的乐高城堡,包含四个主要组件:近似最近邻(ANN)索引、后端服务器、LLM推理服务器和前端用户界面。这些组件可以独立配置,就像是乐高积木,你可以根据自己的需要随意组合。
 图片
图片
🔎 ANN索引(Dense Retrieval)
在密集检索中,查询和文档被编码成高维特征向量,然后通过相似性搜索来确定查询向量的最近邻居。RAGViz使用分布式系统来存储和索引这些向量,就像是个超级大脑,帮你记住所有的东西。
🏭 上下文构建器(Context Builder)
后端服务器处理构建语言模型上下文的所有逻辑,就像是个幕后英雄,默默地支持着整个系统。
🚀 生成和注意力输出(Generation and Attention Output)
RAGViz需要一个GPU节点来运行LLM推理任务。系统使用vLLM库进行快速LLM推理,生成文本,但由于vLLM不支持注意力输出,系统随后使用HuggingFace模型库来获取注意力分数。
🖥️ 前端用户界面(Frontend User Interface)
前端用户界面基于Next.JS框架构建,并作为静态文件托管在Apache web服务器上。用户界面使用表单收集查询信息和其他参数,并在接收到后端的注意力分数后,将它们存储在React状态中以用于注意力可视化。
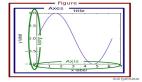
📈 展示了窗口大小为5、步长为2的滑动窗口片段提取方法的演示
滑动窗口方法选择具有最高内积相似度的片段。相反,简单首段方法总是选择显示为绿色的首个窗口。就像是在玩一个“找不同”的游戏,看哪个片段最匹配。
 图片
图片
🔗 资源链接
- RAGViz GitHub:https://github.com/cxcscmu/RAGViz
- RAGViz Demo Video:https://youtu.be/cTAbuTu6ur4
- RAGViz Paper:https://mp.weixin.qq.com/s/ZXvAWDhqKRPq1u9NTfYFnQ