提到历史项目,大家对它的第一印象可能会是数据量大、技术老旧、文档缺失、开发人员断层、"屎山"等。刚好这几天就接到了一个优化老项目的需求,客户反馈页面数据加载缓慢甚至加载不出来,希望能够做一些优化。
刚接到这个任务后真的是一脸懵逼,因为既没有文档,也没有相关的开发人员,甚至连需求都不了解。唯一的解决办法就是向上面多要时间,有了足够的时间就可以通过代码梳理出业务逻辑。
背景
客户在我司采购了WAF防火墙产品,用于拦截和阻断非法请求和一些具有攻击行为的请求。随着系统的不断运作,数据量也随之增长,这就导致客户系统部分报表页面加载时间过长,用户体验极差。
技术栈
SSM + Gateway + Redis + Kafka + MySQL
其中Gateway负责安全防护和限流,当请求经过Gateway时,Gateway会将该请求的原参数,以及安全状态,是否存在攻击,请求ip等信息通过Kafka发送到后台系统并当作日志记录到数据库中。
优化思路
当我看到报表接口的第一眼,就被惊呆了。先不说业务逻辑,单单一个函数中的代码行数将近1000行,在这1000行的代码中依稀残留着几行简洁而又模糊的注释,并且函数内对象的命名也是惨不忍睹,比如format1,data1,data2,collect1, collect2......。即使冒着涉密的风险,我也要复制出来,与大家一起分享。
 图片
图片
吐槽完了,下面开始正式步入正题。经过不知道多久的时间,该方法的逻辑也慢慢变得清晰起来,其主要实现的是:将Kafka接受并存储在数据库中的日志数据,进行分类统计,具体包括事件状态统计(正常访问量,异常访问量,总访问量),近12/24小时内各时间段的事件统计,攻击IP地址TOP5,接口访问TOP5,安全类型分布等报表。
原有逻辑是直接查询数据库,通过sql来实现统计,这种方式如果在数据量小的情况下并不会出现什么问题并且实现方式也相对简单。但是,当数据量上去之后,sql的查询效率就会随之下降,即使通过优化索引的方式也无济于事。
那么在不能引入其他组件或框架情况下,该如何优化查询呢?
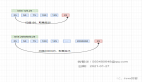
经过短暂的思考后,决定以归档的方式进行数据处理,即在存储日志前,先对日志数据进行分门别类的处理,比如需要统计每个时段的事件访问量,那么就以小时和事件状态为标识进行存储,假设在12:30分有一条异常的访问,那么在消费端接收到消息后,先查询数据库中是否存在12点且访问异常的数据,如果存在,那么次数加一,否则将该数据插入到数据库中,这样在一小时内统一时间状态只会存在一条数据。
 图片
图片
上面的方式是可以减少一定的数据量并且可以提高查询效率,但是如果请求量很大,消息在不断的消费那么就意味着需要不断的查询数据库,更新数据库,这样就会造成一定的性能消耗,而且还会出现并发问题,造成数据重复。
本打算先用这种方式来解决的,有并发就加锁。但是在划了一小时水之后突然想到,当前小时的数据是不是可以存到redis中?
经过片刻的构想,发现确实可以,毕竟变得只是一个数量,可以用redis自增去做。存到缓存后,定时在同步到数据库中不就搞定了吗,这样既可以大大减少数据库操作,还能提高查询效率。
 图片
图片
上面的搞完后,我突然又发现,如果要统计24小时内的数据,那前23小时的数据肯定都已经固定了,不会在发生变化了。那完全可以将前23小时的数据统计完后存入redis,查询的时候只需要在数据库中查询当前所属小时的数据即可。更新缓存的时间可以设定为1小时1更新,这样就可以保证到一个新时段时,可以保证缓存中的数据为近23小时内的数据。
 图片
图片
现在经过优化以后,几乎所有的数据都通过定时任务的方式来统计和存储了,不在需要通过sql的方式实时统计了。最后还是会有个地方存在优化的空间,由于原业务接口是将所有统计报表的数据放在一个接口里面返回的,那么在不改变原参数和不拆分接口的情况下,可以使用Future做异步处理,毕竟每个报表的数据查询统计操作都是独立的,可以按照预估的查询效率做个排序。那么,最终的一个方法就是将上述几个报表数据进行组装,并统一返回给前端。
小结
由于是公司项目的代码,所以在这里只能粘贴一小部分。但代码不是关键,关键在于如何在不借助其他数据处理的中间件的情况下,如何优化大量数据查询速度。数据分类归档确实是一种可行的解决方式,如果你的项目中有一些需要以月,以天,以人或者其他标准来进行统计的话,不妨可以尝试一下。
如果有更好的方法方式,可以忽略。下面的两张图是测试人员提供的优化前后对比,发现150万的日志量,查询时间在1秒内,比老版本提高很多倍。
优化前
 图片
图片
优化后
 图片
图片