近期引发了一场线上事故,尽然是因为一个小小的雪花算法。说来也是历史的原因,这里记录下,一方面做些工作中的反思,同时大家应注意自己项目中是否也存在类似的问题。
事故现场
事故发生在:2024-11-20:09:40,运维小伙伴通过系统告警发现异常,陆续有各大业务群客户反映系统异常。
 图片
图片
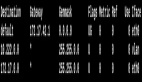
紧急线上日志跟踪,发现错误:
 图片
图片
异常关键字描述:
com.xxx.uid.exception.UidGenerateException: com.xxx.uid.exception.UidGenerateException: Timestamp bits is exhausted. Refusing UID generate. Now: 1732112168问题排查
接到问题后,开发人员迅速到达救火现场。经排查,原本项目中的唯一序列 基于雪花算法,依赖百度UidGenerator生成的自定义19位序列号。
跟踪日志,异常发生处代码如下:
/**
* Get current second
*/
private long getCurrentSecond() {
long currentSecond = TimeUnit.MILLISECONDS.toSeconds(System.currentTimeMillis());
if (currentSecond - epochSeconds > bitsAllocator.getMaxDeltaSeconds()) {
throw new UidGenerateException("Timestamp bits is exhausted. Refusing UID generate. Now: " + currentSecond);
}
return currentSecond;
}显然,异常显示含义:UID的时间戳位超过最大限制。
追溯代码,找到问题出处:
 图片
图片
因为时间戳位设置过短导致的。
根因分析
UidGenerator原理
参考官网介绍:https://github.com/baidu/uid-generator/blob/master/README.zh_cn.md
基于雪花算法实现,初始设置
 图片
图片
- sign(1bit) 固定1bit符号标识,即生成的UID为正数。
- delta seconds (28 bits) 当前时间,相对于时间基点"2016-05-20"的增量值,单位:秒,最多可支持约8.7年
- worker id (22 bits) 机器id,最多可支持约420w次机器启动。内置实现为在启动时由数据库分配,默认分配策略为用后即弃,后续可提供复用策略。
- sequence (13 bits) 每秒下的并发序列,13 bits可支持每秒8192个并发。
按照项目中代码,时间戳(delta seconds)部分使用了28位存储自2016年5月20日以来的秒数。我们可以计算最大支持的时间:
 图片
图片
所以,按照提供的时间基点和算法设计,雪花算法能够支持到2024年11月20日左右。这个日期是理论上的最大值,也是和事故发生的时间恰好对上。
如果需要延长使用时间,可以考虑增加时间戳的位数,例如增加到31位,这样可以支持更长的时间范围。
合理性分析
新的位分配方案合理性分析:
- 时间戳(timeBits = 31):
优点: 理论上可以支持到 (2^{31} - 1 = 2,147,483,647) 秒,大约为68.5年。这使得系统能够覆盖更长的时间跨度,从2016年5月20日开始,可以支持到大约2084年,方案可行。
- 工作节点ID(workerBits = 15):
优点: 15位可以支持 (2^{15} = 32,768) 个不同的工作节点,这对于大多数分布式系统来说是足够的,方案可行。
缺点: 如果系统预期会有超过32,768个节点,或者节点的生命周期非常短,可能需要考虑更多的位数。
序列号(seqBits = 17):
优点: 17位可以支持每秒大约 (2^{17} - 1 = 131,071) 个并发ID生成。这对于高并发系统来说是合理的,尤其是在需要在同一秒内生成大量ID的场景中。
注意事项:
需要确保系统在处理时间戳、工作节点ID和序列号时能够正确地进行位运算。
- 扩展性:
合理性: 这种分配方案为未来可能的扩展提供了一定的灵活性,尤其是在时间戳和序列号方面。
注意事项: 如果系统预期会有非常长的运行时间或者非常高的并发需求,可能需要考虑进一步增加时间戳或序列号的位数。
- 是否ID冲突:
时间戳: 31位时间戳提供了足够的时间分辨率,以确保在大多数情况下,即使是在同一工作节点上,连续生成的ID也会因为时间戳的增加而不同。
工作节点ID: 15位工作节点ID允许系统区分不同的工作节点,这有助于在分布式环境中避免ID冲突。
序列号: 17位序列号在同一秒内提供了高达131,071个不同的序列号,这在高并发环境下可以减少同一节点同一时间生成相同ID的可能性。
时钟同步: 所有节点需要保持时间同步,本次不涉及。
总之,按系统业务量和并发量,新的位分配方案是合理的。
实施措施
- 调整时间位数,重新发布程序
/** Bits allocate */
protected int timeBits = 31; //28->31
protected int workerBits = 15;//22->15
protected int seqBits = 17;//13->17即重新定义了位数,对应的新的位数如下:
 图片
图片
- 分批进行,核心公共程序优先发布
- 整理服务发布列表,标记受影响的服务,是否已发布
- 验证版本,保证生产版本准确性
- 验证基本流程,观察异常情况,问题是否得到有效解决
- 故障汇报
复盘总结
- 当线上事故来临,没有一片雪花算法是无辜的?!!!
- 开发人员应掌握框架核心原理,能快速定位问题。
- 应急措施前进行合理性分析,避免引入新问题或者遗留问题
- 排雷全局引用问题,包括:程序、数据库、业务方面等
- 历史问题如何发现?
- 血的教训,大家项目中类似问题及时排查
- 欢迎各位留言提供精妙的解决方案!!!
参考资料
- 官网UidGenerator原理:https://github.com/baidu/uid-generator/blob/master/README.zh_cn.md
- 百度UidGenerator源码分析:https://juejin.cn/post/7026991586680668168
- 8种分布式ID生成方案汇总:https://mp.weixin.qq.com/s/3nG4-bIPBdiJk0ShE98APQ