有看了短视频的同学吐槽:“讲了这么多scalability理论,也不知道究竟有什么用”。今天就和大家聊聊scalability理论,在数据库架构设计上的实践。
我还是那句话:思路比结论重要。

最早的数据库都是单机的,其最大的痛点是啥?
无法线性扩展。
磁盘能力无法线性扩展,内存能力无法线性扩展,计算能力无法线性扩展。
架构师们称之为“Shared Everything”架构。
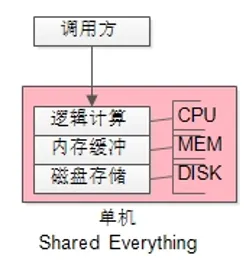
如上图所示,DISK/MEM/CPU 都耦合在一个DBMS进程内,必须部署在一台服务器上,完全处于竞争态,无法线性扩展,并行处理较差。
数据库单机部署,就是典型的“Shared Everything”架构。
如何来提升系统的并行能力呢?
最容易想到的,就是把无状态的逻辑计算部分,从DBMS进程内拆分出来,做成可扩展的微服务集群,实现“计算与存储分离”。
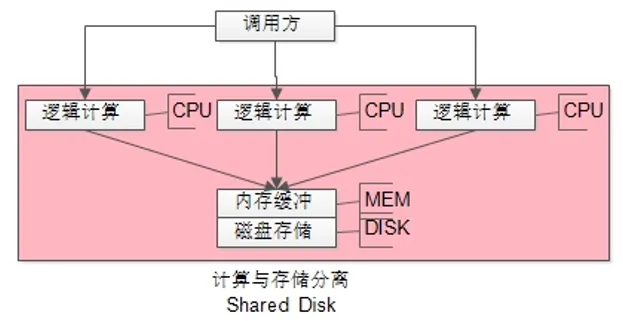
如上图所示:
- CPU逻辑计算拆分出了独立的进程,可以集群部署,能够线程扩展;
- DISK/MEM 仍耦合在一个进程内,仍处于竞争态,无法线性扩展;
Oracle Rac,就是典型的“Shared Disk”架构,核心思路是“计算与存储分离”。
存储部分磁盘IO仍有集中的资源竞争,还有没有进一步的优化空间呢?
最容易想到的,就是把数据打散,分布到不同的数据库实例上,每部分数据享有单独的资源。

如上图所示:
- 把整体数据存储分为了N份,每份之间没有交集;
- 每份数据的 DISK/MEM/CPU 都在一个DBMS进程内,部署在一台服务器上;
- 每份数据的资源之间的没有竞争;
没错,这就是“水平切分”,它是典型的”Shared Nothing”架构。
稍作总结,数据库扩展性scalability架构:
- Shared Everything:数据库单机系统,资源竞争;
- Shared Disk:Oracle Rac,计算与存储分离;
- Shared Nothing:水平切分,复制集群,资源完全隔离;
补充一句,这三类架构并没有解决Availability与Consistency相关的问题,这两类问题是通过其它架构方案解决的,后面再讲。