













Netty通过巧妙的内存使用技巧尽可能节约内存空间,进而减少java中Full gc的STW的时间,由此间接的提升了程序的性能,本文也将直接从源码的角度分析一下Netty对于内存方面的使用技巧,希望对你有所启发。

详解Netty中的内存的优化思路
1.使用基本类型替代包装类
内存空间算是宝贵的系统资源,为了提升CPU加载数据效率以及节约内存空间,对于某些常见的基本数据类型,Netty都是能省则省,最直接的落地方案就是使用基本类型替代包装类。
这其中totalPendingSize这个变量,它用于记录那些待处理的数据,为了节约内存空间,记录大小的类型是long而非Long,通过这种方式避免了创建java对象(java对象包含对象头的信息,相比基本类型更占用内存空间):

对此我们也给出这个变量的定义:
@SuppressWarnings("UnusedDeclaration")
private volatile long totalPendingSize;又因为该字段需要保证线程安全,所以Netty设计者在此基础上又将其设置为AtomicLong原子类型,通过static关键字加以修饰,使所有实例共享一个变量,从而避免没必要的创建开销和并发安全:

对此我们也给出源码示例,即位于ChannelOutboundBuffer变量定义的位置:
//通过AtomicLongFieldUpdater修饰totalPendingSize
private static final AtomicLongFieldUpdater<ChannelOutboundBuffer> TOTAL_PENDING_SIZE_UPDATER =
AtomicLongFieldUpdater.newUpdater(ChannelOutboundBuffer.class, "totalPendingSize");2.动态内存调整
除上述内存使用技巧以外,netty在进行内存分配时也用到的动态调整的使用技巧,该设计理念比较简单,按照空间与分配思想:后续使用的内存大小大概率是等同于本次使用的空间大小,所以Netty在调用record进行内存分配时,如果发现缩小空间依然可以满足要求,则进行缩容,反之进行扩容,由此得到一个尽可能节约内存空间且能满足业务要求的数值:
private void record(int actualReadBytes) {
//若实际需要的空间 <= 预缩小达到的尺寸,则对nextReceiveBufferSize进行缩减
if (actualReadBytes <= SIZE_TABLE[max(0, index - INDEX_DECREMENT)]) {
if (decreaseNow) {
index = max(index - INDEX_DECREMENT, minIndex);
nextReceiveBufferSize = SIZE_TABLE[index];
decreaseNow = false;
} else {
decreaseNow = true;
}
} else if (actualReadBytes >= nextReceiveBufferSize) {//如果所需空间大于nextReceiveBufferSize,则进行扩容
index = min(index + INDEX_INCREMENT, maxIndex);
nextReceiveBufferSize = SIZE_TABLE[index];
decreaseNow = false;
}
}3.应用层面的zero-copy
内存拷贝也是存在一定的时间开销,例如我们现在有一个字符串的数据需要将byte1和byte2拼接起来才能得到,按照传统的实现思路,我们需要开发一个足够容纳byte1和byte2的内存空间,然后将byte1和byte2一并写入,这种做法有着如下耗时点:
- 开辟内存空间所占用的时间。
- 将byte1内存新开辟空间的耗时。
- 将byte2写入新开辟的内存空间耗时。

而Netty则不是这样做,它的设计思路是直接将两个数组,逻辑上组合,即通过一个数组指向这两个引用,从逻辑上视为一个整体,而不是物理操作上的组合:
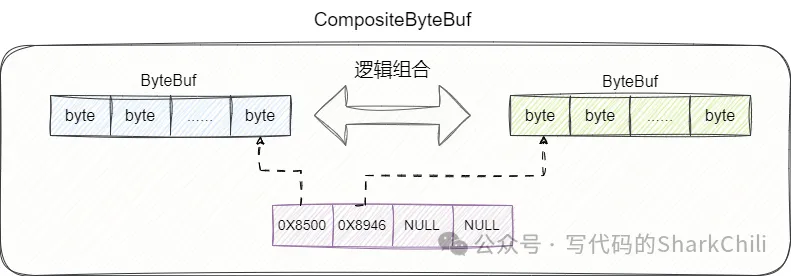
对此我们给出CompositeByteBuf的addComponent0方法,可以看到对于需要组合的数据buffer,它会通过addComp方法将这个ByteBuf 存到CompositeByteBuf底层的数组中,由此保证数据逻辑上的一致:
private int addComponent0(boolean increaseWriterIndex, int cIndex, ByteBuf buffer) {
assert buffer != null;
boolean wasAdded = false;
try {
checkComponentIndex(cIndex);
//将其包装为Component
Component c = newComponent(ensureAccessible(buffer), 0);
int readableBytes = c.length();
//......
//添加到CompositeByteBuf底层的components数组中,通过逻辑完成组合
addComp(cIndex, c);
//......
return cIndex;
} finally {
//......
}
}
//添加到components数组中保证逻辑上的一致
private void addComp(int i, Component c) {
//......
components[i] = c;
}4.使用堆外内存
将数据存放在JVM非堆内存空间,通过减少没必要的GC确保操作和执行性能的高效,这也是Netty中对于内存方面的优化,这其中最经典的就是PooledHeapByteBuf,它直接操作的就是堆外内存的数据:
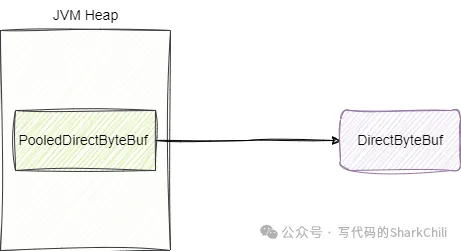
对此我们也给处PooledDirectByteBuf 获取直接内存的源码实现:
//从内存池中获取直接内存空间返回给用户使用
static PooledDirectByteBuf newInstance(int maxCapacity) {
PooledDirectByteBuf buf = RECYCLER.get();
buf.reuse(maxCapacity);
return buf;
}需要补充的是,这种做法也存在的一定的风险:
- 创建速度慢。
- 存放在非堆内存空间,使用不当可能造成内存泄漏。
5.内存池化复用
上文的堆内存就是PooledHeapByteBuf即池化过的内存,通过池化:
- 保证对象复用,减小没必要的创建开销。
- 提升程序并发执行性能。
对此我们给出相应的源码实现:
//初始化直接内存池化工厂RECYCLER
private static final ObjectPool<PooledDirectByteBuf> RECYCLER = ObjectPool.newPool(
new ObjectCreator<PooledDirectByteBuf>() {
@Override
public PooledDirectByteBuf newObject(Handle<PooledDirectByteBuf> handle) {
return new PooledDirectByteBuf(handle, 0);
}
});
//从内存池中获取直接内存空间返回给用户使用
static PooledDirectByteBuf newInstance(int maxCapacity) {
//从内存池中获取直接内存空间
PooledDirectByteBuf buf = RECYCLER.get();
buf.reuse(maxCapacity);
return buf;
}6.对jdk零拷贝的封装
我们在上述所讲的零复制更多强调的是应用层面上的零复制,也就是通过减少应用层面上数据的拷贝提升程序的执行效率。实际上Netty也有基于操作系统层面的零拷贝实现,这其中最典型的实现就是DefaultFileRegion的transferTo函数,它底层调用JDK自带的NIO零拷贝方法transferTo实现当前文件数据通过sendfile调用传输到socket通道中,由此避免数据传输时多次切态、内核缓冲区和用户缓冲区来回拷贝的开销:
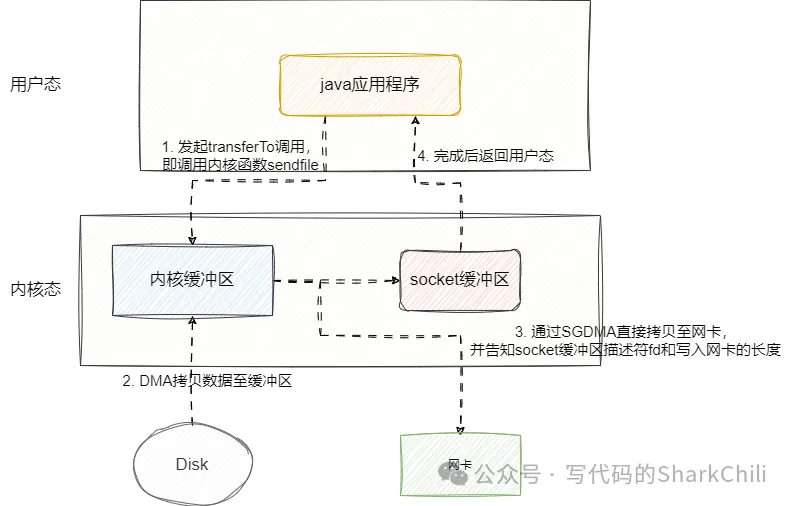
对此我们也给出DefaultFileRegion类中transferTo的源码,可以看到其底层就是将JDK默认的NIO零拷贝方法进行封装,将DefaultFileRegion封装的FileChannel 的文件数据拷贝到target的文件通道中,其底层就用到内核函数sendfile:
private FileChannel file;
@Override
public long transferTo(WritableByteChannel target, long position) throws IOException {
//......
long written = file.transferTo(this.position + position, count, target);
if (written > 0) {
transferred += written;
} else if (written == 0) {
//......
}
return written;
}



















