今天,我们来聊聊 AI 大模型,有一个非常重要概念 "Embedding"。你可能听说过它,也可能对它一知半解。如果你没有深入了解过 Embedding,那你就无法真正掌握 RAG 技术,更不能掌握 AI 大模型精髓所在。

1.什么是大语言模型(LLM)?
LLM 是一种大型语言模型,是一种用于理解、生成和响应类人文本的神经网络,这些模型是在大量文本数据上训练的深度神经网络。
大型语言模型中的“大”指的是模型在参数方面的大小和它所训练的庞大数据集。这样的模型通常有数百亿甚至数千亿个参数,这些参数是网络中可调整的权重,在训练过程中进行优化,以预测序列中的下一个单词。
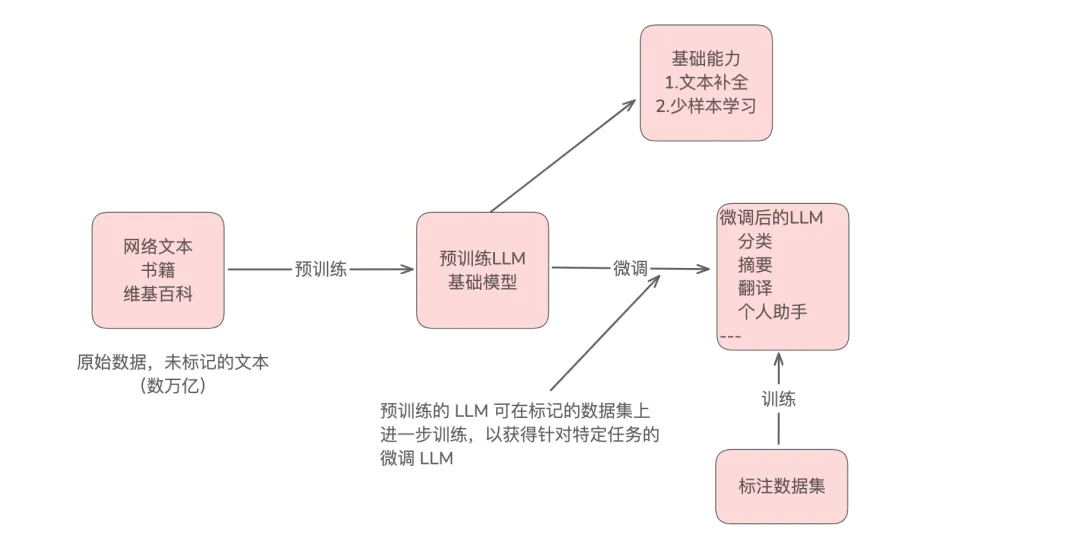
模型微调,是指在预训练模型的基础上,使用特定任务的标注数据进行进一步训练,使模型能够完成特定的任务。
其特点,建立在预训练基础上,利用预训练模型已经学到的语言知识,不需要从零开始训练。这样有助于降低训练的成本,以及缩短训练时间,能更好快速适应新任务。
2.Embedding 的理解
深度学习模型不能处理原始形式的视频、音频和文本等数据格式。那怎么办?因此,我们引入了 “embedding“ ,翻译为“嵌入“ 。
专业术语来讲,Embedding 是一种将离散数据(如文字、图像、音频等)转换为连续的密集向量表示的技术,这些向量能够反映原始数据之间的关系。
现在,很多企业搭建本地知识库,常提到的 RAG 技术,实际上用 Embedding 模型作为基础工具,来将查询的词转换为向量。
Embedding 是 RAG 的基础工具,而 RAG 是 Embedding 的一种应用场景,这样就得到一个公式:RAG = Embedding + 检索 + LLM生成。
如果,你还想更深层次去理解 Embedding 底层细节原理,建议你去学习或了解相关数学概念,如向量空间、线性代数、矩阵、特征值和特征向量和内积和外积等。
今天,这篇文章主要是讲大致流程概念,知道这么回事,并没有过多的深入讲解。
3.RAG 又是什么?
RAG 是检索增强生成(Retrieval-Augmented Generation)的缩写,它通过结合检索系统和生成模型来提高语言生成的准确性和相关性。
RAG 优势就是能够在生成响应时引入外部知识,使得生成的内容更加准确,也无需训练。很好解决 LLM 面临数据实时性问题,因为 LLM 训练是有时截止日期的。
目前,很多企业搭建自己知识库时,都是采用 RAG 技术进行信息检索。然而为了达到更好效果,企业一般也会进行内部模型微调 Embedding Model,来增加检索增强生成的能力。