在一个公司中,消息通知系统是不可或缺的一部分,每个团队都可能开发了一套独自的消息通知组件,随着公司业务团队的日益增长,维护繁琐、排查问题复杂、开发成本等问题就会凸显出来。(例如我们的企微群通知,由于消息内容不同模板不同,一个项目内使用的组件就有3种,还不包含其他通知部分。)
基于这样的背景,我们就迫切需要开发一套通用的消息通知系统。那么如何高效地处理大量的消息请求以及服务稳定性的保障,成为了开发者需要面对的重要挑战。本文将探讨如何构建高性能的消息通知系统。
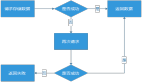
1 服务划分
 图片
图片
- 配置层: 主要是后台管理系统,做一些发送的配置,包括请求方式、请求地址、预期响应结果、通道绑定、通道选择、重试策略以及结果查询等功能。
- 接口层:对外提供服务的方式,支持RPC与MQ的方式,后续如需Http或其他方式可以扩展添加。
- 基础服务层:业务核心层,包括消息的首次发送与重试发送,消息通道的路由选择以及服务的调用包装。其中可以看到正常与异常的服务发送执行器,通过这样的设计可以对异常服务的发送与正常服务发送进行隔离,避免异常服务的发送对正常服务造成影响。比如请求某一消息通道的接口耗时长了,导致请求该通道的资源占用时间较长,从而影响的正常服务的请求调用。执行器的选择是根据路由器进行路由的,其中路由策略包括配置的路由策略以及动态服务异常自发现路由策略。所谓正常服务与异常服务指的是调用的下游服务方是否正常,比如我们发送支付成功的消息或调用第三方短信服务,如果在一段时间响应都比较慢或直接失败等我们就可以判定为异常服务。
- 通用组件层:主要是对一些通用组件的封装。
- 存储层:包括缓存层与持久化层,缓存层主要是缓存配置的发送策略、重试策略以及其他一些需要进行缓存的内容,持久化层主要是ES与MySQL,MySQL存储消息的发送记录以及配置,ES主要存储消息的发送记录供用户查询。
2 系统设计
2.1 首次消息发送
 图片
图片
在接受消息发送请求的时候,一般会通过 RPC 服务请求和 MQ 消息消费进行处理,这两种方式各有优缺点,RPC 这种方式,我们无需考虑消息的丢失问题,MQ 可以实现异步解耦、削峰填谷。
2.1.1 幂等性的处理
为了防止接收到同样的消息内容进行发送处理,我们通常会做一些幂等性的设计。幂等性的判断有很多手段,比如先加锁再查询或利用数据库的唯一主键等来实现,但其实在我们消息量很大的时候,查数据库就有点慢了。因为发送消息的这种场景,重复消息一般在短时间内发生的,一般不会有跨很多天来一笔已经发送过的消息,所以可以设计利用 Redis 来实现,先判断是否有相同的Redis Key,再判断消息内容是否相同,有可能相同的Redis Key,发送不同的消息内容,这种是允许的,具体看对应的业务需求。
2.1.2 问题服务动态发现器
上文提到路由器中的路由策略包括配置的路由策略和动态服务异常自发现路由策略,其中动态服务异常自发现路由策略核心在于服务异常自发现,核心是依据问题服务动态发现器实现的,当我们发现某一个消息通道服务异常时可以自动路由采用异常通知执行器执行。
我们主要是借助sentinel的API在各自节点JVM内实现的,针对设置的时间窗口内请求的总次数和失败的总次数进行统计,达到设定值,就认为请求的服务有问题了,认定其为异常服务。核心主要是以下两个方法,其中loadExecuteHandlerRules方法主要是对流控规则的设定,我们可以通过Apollo或Nacos进行动态的修改,judge方法是对请求和失败的拦截,判断允许正常访问,一旦拦截后就认为是异常服务,在内存中进行标记记录,后续请求通过异常执行器执行处理。
当我们看到这儿会不会有疑问,问题服务在啥时候会恢复正常呢,难道服务出现一次问题,就一直被认定为问题服务了?当时不是的,我们也设计了类似熔断器那样的自动恢复功能,在判断为问题服务后会经过一段时间的静默期,静默期内所有对该服务的请求都走异常通知器的执行流程,当静默期过后,此时到达了半熔断期,就是如果访问正常的次数达到一定值后,就会恢复为正常。
2.1.3 sentinel 滑动窗口的实现原理(环形数组)
 图片
图片
根据传入的时间窗口大小和数量,计算数组的数量,数组的下标就是windowsId,windowsStart是每个数组的起始时间值。
例如:统计 1s 的请求量,设置两个窗口,那么每个窗口对应的id 就是0、1,相应的时间范围就是 0m-500ms,500ms-1000ms。如果当前时间是 700ms,那么对应的窗口 id=(700/500)%2=0, 对应的 windowStart=700-(700%500)=200,对应的起始就是 id 为 0 的窗口;如果当前时间是 1200ms,对应的窗口 id=(1200/500)%2=0;对应的 windowStart=1200-(1200%500)=1000 大于 id=0 的起始时间,重置 id 为 0 的窗口起始值,id=0 的位置不变。
2.1.4 线程池的动态调整
消息处理完成后,利用线程池进行异步发送,线程池分为正常服务的线程池和异常服务的线程池,至于为啥设计不同的线程池,我们在下面稳定性设计方面阐述。线程池核心参数的设定一般会根据任务类型和 CPU 核数进行一个初始化的设定,后续我们一般会压测来动态的调整来满足我们的目标。那么我们怎样可以设计一个可以动态调整的线程池呢?
一般我们可以通过 Apollo 或 Nacos 等统一配置来动态修改线程池的参数,但是线程池的阻塞队列长度是不允许修改的,当然我们可以自己自定义一个队列来实现这样的功能。接下来我们讲述的这种设计,是不用通过自定义阻塞队列的方式去实现的。
我们直接定义了一个无界的线程池,核心线程数和最大线程数相等,而且用的是默认的丢弃策略,那么就有疑问了,这样的线程池我们在使用的时候,会有内存溢出和消息的丢失风险,别着急,我们继续往下看。
在每次添加任务的时候会判断线程池队列中的任务是否达到设定的最大值,如果达到就不会继续添加了,当前线程池处于繁忙状态了,后续可以利用 MQ 落库,之后通过重试任务进行发送了,也保证了永远不会触发线程池的拒绝策略。
2.2 重试消息发送
 图片
图片
部分消息因为系统达到瓶颈处理不过来或某些消息发送失败需要重试,这些消息都可以通过任务重试来进行处理,当然利用这种方式也可以实现延迟消息的发送。
实现这种重试的消息机制可以利用分布式定时任务调度框架,一般为了提高重试效率,会采用分片广播这种方式,自己做好消息重复发送的控制,我们也可以利用调度线程池来实现。
每次进行任务捞取进行调度时,会首先判断下当前 handler 是否繁忙,其实就是重试不同类型任务的线程池资源是否充足,如果不充足的话,即使捞取出来,也一直是排队等待。
为了防止不同的节点处理相同的任务进行了加锁控制,每次捞取的任务量是根据不同任务 handler 设置的量来确定的,捞取完成后发送至 MQ,然后采用线程池进行发送处理。
2.2.1 ES与MySQL数据同步
由于发送消息的数据量,后台在进行数据查询时主要是通过ES进行查询处理的,这就涉及到数据库数据与ES数据一致性的问题。当然也可以采用分库分表或宽表等技术进行处理,分库分表对一些非分片键的查询可能不太友好。
 图片
图片
ES 更新完成后修改数据库状态为更新完成状态,若此时通知记录表还有更新,就会将同步状态初始化,若修改数据库为init先于同步完成后的更新就会出现数据不一致的问题,所以每次同步时携带上数据库中的update_time,大于等于db中的update_time才会更新完成(其实update_time就是一个版本号)。
 图片
图片
ES按月滚动建立索引,每月新建立的索引,标签都是hot,新增的数据都会放入hot节点上进行存储,到了第二月,通过定时任务将上月索引的tag修改为cold,ES集群就会自动将数据迁移到标签为cold节点上(cold节点的性能一般配置都比较低,对性能要求并不高)。
3 稳定性的保障
上述一系列的设计是围绕高性能进行考虑的,当然在稳定性方面我们也不能忽略,下述几方面也是我们在稳定性方面的考虑。
3.1 流量突增
面对流量突增时做了两层降级。当流量缓慢增大时,线程池繁忙后,利用MQ做了一次流量削峰、异步落库,后续定时任务处理发送,发送的延时时间是0s;当流量陡增,用sentinel进行判断,不经任何判断直接MQ削峰落库,后续消费是延迟消费的,待资源空闲才进行捞取处理。
3.2 问题服务的资源隔离
首先我们想想为啥要做问题服务的隔离呢,不做会有什么后果呢?设想一下如果不隔离,问题服务与正常服务采用同一线程池资源进行处理,当问题服务请求请求耗时时间较长,线程释放慢,会导致大量正常服务的消息不能及时进行处理,这样就会导致问题服务影响到正常服务的消息处理,所以才需要做问题服务与正常服务的资源舱壁隔离。
3.3 第三方服务的保护
正常的第三方服务一般都会做限流降级设置,防止服务被击垮。如果一些开发水平欠缺的服务没有做,就需要我们进行考虑了,一方面不能因为我们的请求量较大,影响到别人服务,另一方面,我们的服务不能因为第三方服务而引发问题,所以通常我们需要考虑进行熔断处置。
3.4 中间件的容错
在我们使用各种中间件时,也应该考虑的中间件的问题。比如公司MQ需要进行扩容升级,会使MQ宕机数秒,针对这种问题的容错,在进行开发时也应尽可能的考虑设计到。
3.5 完善的监控体系
我们也应该建立完善的监控系统,来保障服务的稳定运行,能在问题扩散之前及时发现处理,能在问题发生后进行快速的处理,能在后期优化处理时提供辅助依据。
3.6 服务的双活部署、弹性扩缩容
在运维层面,也应该考虑服务不同机房的部署,以保证服务的可用性,为了应对流量的变化同时也基于成本的考虑,也可以基于服务的综合指标进行弹性扩缩容。
4 总结
关于作者赵培龙 采货侠JAVA开发工程师