译者 | 布加迪
审校 | 重楼
几十年来,以Elasticsearch为代表的关键词匹配(又称为全文搜索)一直是企业搜索和推荐引擎等信息检索系统的默认选择。

随着基于人工智能的搜索技术不断进步,如今企业组织在向语义搜索转变,从而使系统能够理解用户查询背后的含义和意图。嵌入模型和矢量数据库已成为这一转变的核心。
语义搜索将数据表示为矢量嵌入,从而比关键字匹配更胜一筹,提供了对搜索意图更深入细致的理解,并彻底改变从检索增强生成(RAG)到多模态搜索的各种应用场景。
在实践中,有效的信息检索系统既需要语义理解,又需要精确的关键词匹配。比如说,用户希望搜索结果显示与其搜索查询相关的概念,又同时尊重查询中使用的字面文本,比如特殊术语和名称,并返回精确匹配的结果。
基于密集矢量的语义搜索有助于理解含义(比如知道“car”和“automobile”是同一个意思),而传统的全文搜索提供用户期望的精确结果(比如找到“Python 3.9”的精确匹配)。因此,许多组织正在采用混合搜索方法,结合两种方法的优势,以兼顾灵活的语义相关性和可预测的精确关键字匹配。
混合搜索面临的挑战
实现混合搜索的一种常见方法是使用专门构建的矢量数据库(比如开源Milvus)进行高效、可扩展的语义搜索,同时使用传统的搜索引擎(比如Elasticsearch或OpenSearch)进行全文搜索。
虽然这种方法可以获得良好的效果,但也带来了新的复杂性。管理两个不同的搜索系统意味着要处理不同的基础设施、配置和维护任务,这会造成更沉重的操作负担,并加大潜在集成问题的可能性。
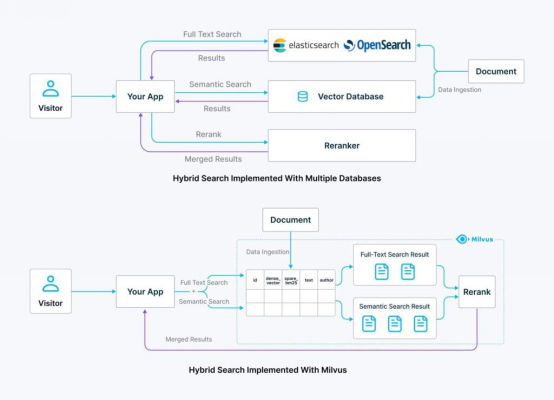
混合搜索的统一解决方案带来了许多好处:
- 减少基础设施维护:管理一个系统而不是两个系统大大降低了操作复杂性,还节省了时间和资源。这也意味着可以减少上下文切换和掌握两组不同API的麻烦。
- 统一的数据管理:统一的表结构允许你存储密集数据(基于矢量)和稀疏数据(基于关键字)以及共享的元数据标签。使用两个独立的系统需要将元数据标签存储两次,以便双方能够进行元数据过滤。
- 简化的查询:单单一个请求可以执行语义搜索任务和全文搜索任务,因而不需要对不同的系统进行两次API调用。
- 增强的安全性和访问控制:统一的方法可以实现更直接、更稳健的安全管理,因为所有访问控制都可以在矢量数据库中加以集中管理,从而增强了安全合规和一致性。
统一矢量方法如何简化混合搜索?
在语义搜索中,机器学习模型基于文本的含义,将文本作为点(即密集矢量)“嵌入”到高维空间中。语义相似的文本在这个空间中彼此挨得更近。比如说,“apple”(苹果)和“fruit”(水果)在这个空间中可能比“apple”(苹果)和“car”(汽车)挨得更近。这便于我们只需使用近似最近邻(ANN)算法计算每个点之间的距离,就可以快速找到语义相关的文本。
通过将文档和查询编码为稀疏矢量,该方法还可以应用于全文搜索。在稀疏矢量中,每个维度表示一个术语,其值表示每个术语在文档中的重要程度。
文档中没有出现的术语的值为零。由于任何给定的文档通常只使用词汇表中所有可能术语的一小部分,因此大多数术语不会出现在文档中。这意味着得到的矢量是稀疏矢量——它们的值大部分是0。比如说,在通常用于评估信息检索任务的MS-MARCO数据集中,虽然有大约900万个文档和100万个独特的术语,但搜索系统通常将这个庞大集合分成比较小的部分,以便于管理。
即使在片段级别,词汇表中有数十万个术语,每个文档通常包含少于100个术语,这意味着每个矢量的值超过99%为0。这种极端稀疏性对我们有效地存储和处理这些矢量的方式有着重要的意义。
可以利用这种稀疏模式来优化搜索性能,同时保持准确性。最初为密集矢量设计的矢量数据库可加以改动,以便有效地处理这些稀疏矢量。比如说,开源矢量数据库Milvus刚刚发布了原生全文搜索支持,使用Sparse-BM25,这是Elasticsearch及其他全文搜索系统使用的BM25算法的稀疏矢量实现。Sparse-BM25借助以下机制,充分发挥了基于近似的全文搜索优化:
- 基于数据修剪的高效检索算法:通过运用基于启发式方法的修剪,丢弃片段索引中稀疏矢量值最低的文档,并忽略搜索查询中的低值稀疏矢量,矢量数据库就可以显著减少索引大小,优化性能,同时确保质量损耗最小。
- 充分利用进一步的性能优化:将术语频率表示为稀疏矢量而不是反向索引,可以实现额外的基于矢量的优化。这些包括:
- 图索引用于比蛮力扫描更有效的搜索。
- 产品量化(PQ)/标量量化(SQ)进一步减少内存占用。
除了这些优化外,Sparse-BM5实现还继承了高性能矢量数据库Milvus的几个系统级优势:
- 高效的低级实现和内存管理:Milvus的核心矢量索引引擎是用C++实现的,提供了比Elasticsearch等基于Java的系统更高效的内存管理。与基于JVM的方法相比,仅这一点就可以节省数GB,从而减少内存占用。
- 支持MMap:与Elasticsearch在内存和磁盘中使用页面缓存用于存储索引相似,Milvus支持内存映射(MMap),以便在索引超过可用内存时扩展内存容量。
为什么传统的搜索堆栈面对矢量搜索表现不佳?
Elasticsearch是为传统的反向索引构建的,这使得它从根本上难以为密集矢量搜索进行优化。其影响显而易见:即使只有100万个矢量,Elasticsearch也需要3770毫秒(ms)来返回搜索结果,而Milvus仅需6毫秒,足足相差600倍。这种性能差距随着规模的扩大而拉大,Elasticsearch的Java/JVM实现很难与基于C++ /Go的矢量数据库的可扩展性相匹配。此外,Elasticsearch缺乏关键的矢量搜索功能,比如基于磁盘的索引(DiskAnn和MMap)、经过优化的元数据过滤以及范围搜索。
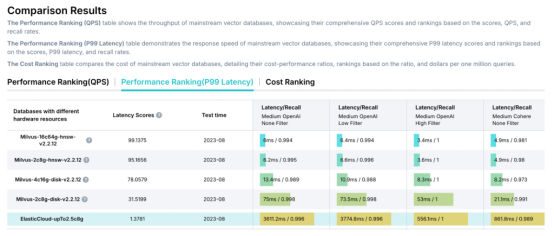 VectorDBBench基准测试结果
VectorDBBench基准测试结果
结语
以Milvus为代表的矢量数据库有望超越Elasticsearch,成为混合搜索的统一解决方案。通过将密集矢量搜索与经过优化的稀疏矢量技术相结合,矢量数据库提供了卓越的性能、可扩展性和效率。
这种统一的方法简化了基础设施,减少了内存占用,并增强了搜索功能,使其可以满足未来的高级搜索需求。因此,矢量数据库提供了一种全面的解决方案,可以无缝地结合语义搜索和全文搜索,性能比Elasticsearch等传统的搜索系统更胜一筹。
原文标题:Elasticsearch Was Great, But Vector Databases Are the Future,作者:Jiang Chen