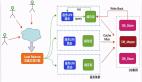
一、面试官:请说说看什么是缓存击穿,他会带来什么危害,以及该如何解决?
1.缓存击穿
(1) 定义:缓存击穿是指在高并发访问下,某个热点数据的缓存过期失效,而此时恰好有大量并发请求访问该数据,导致这些请求直接绕过缓存,访问后端数据库或存储系统,使数据库或存储系统负载急剧增加,甚至可能引发系统崩溃的现象。

(2) 危害:
- 数据库压力增大:大量请求直接访问数据库,可能导致数据库负载过高,响应时间延长,甚至引发数据库崩溃。
- 系统性能下降:由于数据库处理请求的速度远低于缓存,因此缓存击穿会导致系统整体性能下降。
(3) 解决方案:
① 互斥锁(Mutex)和分布式锁(在分布式系统中):
在缓存失效时,使用互斥锁机制确保只有一个请求能够访问数据库并更新缓存,其他请求则等待锁释放后从缓存中获取数据。
下面是一个使用 Redis 分布式锁和 Redis 事务来解决缓存击穿问题的具体代码示例(Python实现)。
import redis
import time
import uuid
# 连接到 Redis 服务器
redis_client = redis.StrictRedis(host='localhost', port=6379, db=0)
# 设置分布式锁的键和过期时间(秒)
LOCK_KEY = 'cache_击穿_lock'
LOCK_EXPIRE = 10 # 锁的有效期,可以根据需要调整
# 缓存的键和值(示例)
CACHE_KEY = 'some_hot_data'
def acquire_lock(redis_client, lock_key, lock_value, expire):
"""
尝试获取分布式锁
:param redis_client: Redis 客户端
:param lock_key: 锁的键
:param lock_value: 锁的值(通常是唯一标识符)
:param expire: 锁的过期时间(秒)
:return: 是否成功获取锁
"""
while True:
# 尝试设置锁,NX 表示只有键不存在时才设置,PX 表示过期时间(毫秒)
result = redis_client.set(lock_key, lock_value, nx=True, px=expire * 1000)
if result:
return True
# 休眠一小段时间后重试,避免忙等待
time.sleep(0.01)
def release_lock(redis_client, lock_key, lock_value):
"""
释放分布式锁
:param redis_client: Redis 客户端
:param lock_key: 锁的键
:param lock_value: 锁的值(必须是获取锁时使用的相同值)
:return: 是否成功释放锁
"""
# 使用 Lua 脚本确保原子性释放锁
lua_script = """
if redis.call("get", KEYS[1]) == ARGV[1] then
return redis.call("del", KEYS[1])
else
return 0
end
"""
redis_client.eval(lua_script, 1, lock_key, lock_value)
return True
def get_data_with_cache_and_lock(redis_client, cache_key):
"""
使用缓存、分布式锁和 Redis 事务获取数据
:param redis_client: Redis 客户端
:param cache_key: 缓存的键
:return: 数据值或 None(如果数据不存在)
"""
# 尝试从缓存中获取数据
cache_value = redis_client.get(cache_key)
if cache_value is not None:
return cache_value.decode('utf-8') # 假设数据是字符串类型
# 尝试获取分布式锁
lock_value = str(uuid.uuid4())
if acquire_lock(redis_client, LOCK_KEY, lock_value, LOCK_EXPIRE):
try:
# 使用 Redis 事务确保原子性
pipe = redis_client.pipeline(True)
try:
# 尝试再次从缓存中获取数据(防止其他客户端在获取锁后更新了缓存)
pipe.watch(cache_key)
cache_value = pipe.get(cache_key)
if cache_value is not None:
pipe.unwatch()
pipe.reset()
return cache_value.decode('utf-8')
# 从数据库中获取数据(模拟)
# 在实际应用中,这里应该是访问数据库的逻辑
data_from_db = "data_from_db" # 假设从数据库中获取的数据
# 更新缓存
pipe.multi()
pipe.set(cache_key, data_from_db)
pipe.execute()
# 返回从数据库中获取的数据
return data_from_db
except redis.WatchError:
# 如果在事务执行过程中,缓存被其他客户端更新,则重新尝试获取数据
pass
finally:
# 释放锁
release_lock(redis_client, LOCK_KEY, lock_value)
# 如果无法获取锁或缓存仍然为空,则返回 None(或根据业务逻辑返回默认值)
return None
# 示例调用
data = get_data_with_cache_and_lock(redis_client, CACHE_KEY)
print(f"获取的数据: {data}")② 热点数据永不过期:
对于重要的热点数据,可以设置其永不过期,以避免缓存过期引发的击穿问题。
但需要注意数据更新时的及时性和准确性,以及可能带来的内存占用问题。
③ 提前异步刷新缓存:
在缓存即将过期之前,通过定时任务或后台线程提前异步加载缓存数据,确保在缓存失效之前已经有新的数据加载到缓存中。
二、面试官:再说说看什么是缓存穿透,如何检测是否存在缓存穿透,以及该如何解决?
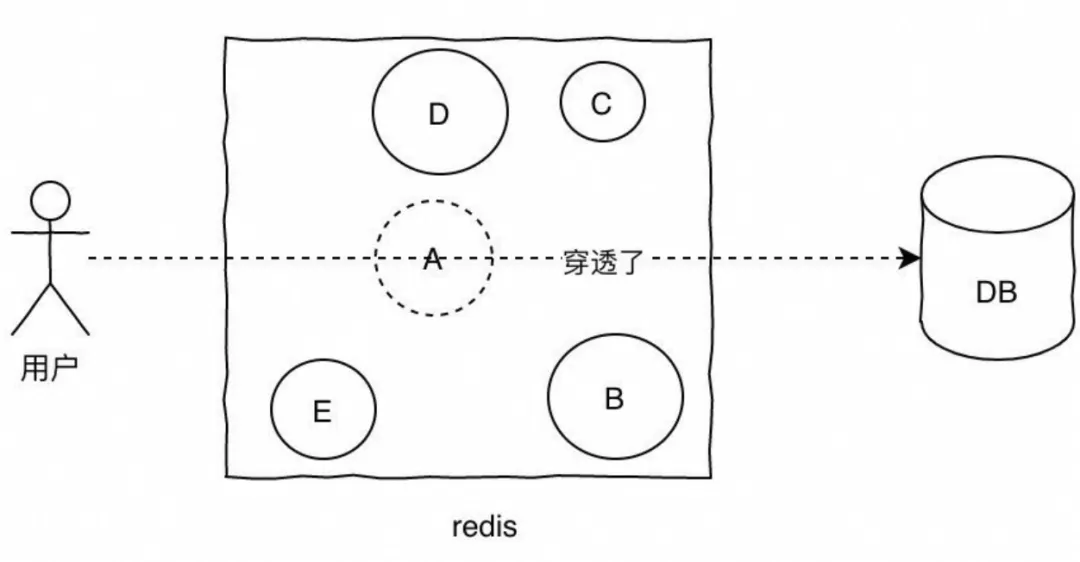
缓存穿透是指查询一个一定不存在的数据,由于缓存是不命中时需要从数据库查询,查不到数据则不写入缓存,这将导致这个不存在的数据每次请求都要到数据库去查询,造成缓存穿透。
如果数据库查询不到这条数据,则不会写入缓存,这将导致这个不存在的数据每次请求都会去查询数据库,对数据库造成很大的压力。
缓存穿透通常是由恶意用户或攻击者请求不存在于缓存和后端存储中的数据来发起的攻击。
一般来说,缓存穿透一开始会由开发者发现系统接口变慢或监控告警发觉,再检测系统日志证实。检查数据库访问日志和缓存访问日志,查看是否存在大量对不存在的键的查询。这些查询如果频繁发生,那么很可能是缓存穿透。
另外,监控缓存的命中率。如果命中率突然下降,且伴随着数据库访问量的增加,这可能是缓存穿透的征兆。
再者,可以分析系统接收到的请求参数,特别是那些明显不符合业务逻辑的非法参数。
以下是两种防止缓存穿透的策略:
1.布隆过滤器(Bloom Filter)
布隆过滤器是一种空间效率很高的数据结构,它利用多个哈希函数来将一个元素映射到一个位数组的多个位中。当查询一个元素时,它会检查对应的位是否都为1,如果是,则认为元素可能存在(注意是可能存在,因为存在哈希冲突的情况),否则认为元素一定不存在。
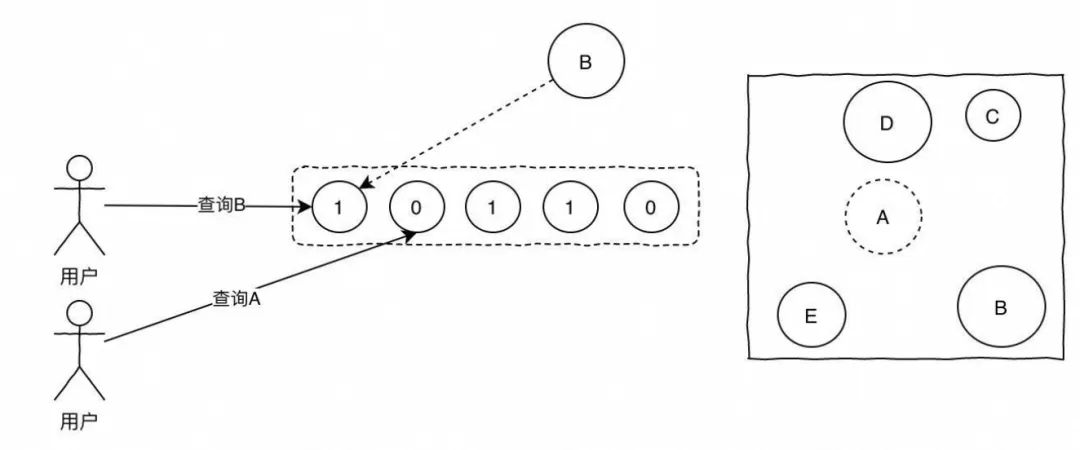
在缓存穿透的场景中,可以在查询缓存之前先使用布隆过滤器检查元素是否存在。如果布隆过滤器认为元素不存在,则直接返回一个错误信息或默认值,而不去查询数据库。这样可以有效减少对数据库的无效查询。
布隆过滤器的缺点:
- 误判率:布隆过滤器通过多个哈希函数将元素映射到位数组中,因此存在哈希冲突的可能性。这意味着,当查询一个元素时,布隆过滤器可能会误判该元素存在(即位数组中对应的位都为1),而实际上该元素在数据库中并不存在。虽然误判率可以通过增加哈希函数数量和位数组长度来降低,但这也会增加计算复杂度和空间开销。
- 删除困难:布隆过滤器不支持直接删除元素。如果要从布隆过滤器中删除一个元素,需要将其对应的所有位都重置为0。然而,这可能会影响其他元素的判断,因为多个元素可能共享同一个位。因此,在实际应用中,布隆过滤器通常用于只读场景或需要频繁查询但很少更新的场景。
2.空值缓存(并不推荐):
对于那些查询结果为空的数据,也将其缓存起来,但设置一个较短的过期时间。这样,当下次再次查询这个不存在的数据时,可以直接从缓存中获取空值,而不是去查询数据库。
控制缓存的缺点:
- 额外的内存消耗:当数据库中不存在某个数据时,系统仍然需要将其作为一个空值(或特殊标记)缓存起来。这会导致缓存中存储大量的空值或特殊标记,从而占用额外的内存空间。如果这类空值数据过多,会显著影响缓存的存储效率和性能。
- 数据不一致性:空值缓存的过期时间需要合理设置。如果过期时间设置得过长,当数据库中实际数据发生变化(例如,原本不存在的数据被插入)时,缓存中的空值数据仍然有效,这会导致数据不一致的问题。相反,如果过期时间设置得过短,可能会频繁触发缓存失效和数据库查询,增加系统负担。
- 难以维护:空值缓存需要额外的逻辑来处理过期时间和数据更新等问题。这增加了系统的复杂性和维护成本。同时,由于空值数据在缓存中的存在,也可能导致缓存污染和命中率下降等问题。
三、面试官:什么是缓存雪崩,缓存雪崩产生的常见原因有哪些?
缓存雪崩是指在分布式系统中,缓存中的大量数据同时失效或过期,导致大量请求直接访问数据库或后端服务,造成系统性能急剧下降甚至瘫痪的现象。
这种现象通常会对系统造成灾难性的影响,因为它会导致后端数据库或服务承受巨大的压力,可能引发服务不可用或数据丢失等问题。
雪崩和击穿、热key的问题不太⼀样的是,他是指⼤规模的缓存都过期失效了。
缓存雪崩产生的常见原因主要包括以下几点:
- 缓存中大量key同时过期:如果系统中存在大量缓存数据的过期时间被设置为相同或相近,那么当这些缓存数据同时过期时,系统将无法从缓存中获取数据,转而直接访问数据库。这将导致数据库承受巨大的访问压力,可能引发性能下降或崩溃。
- 缓存服务器故障:缓存服务器作为系统中的关键组件,如果发生故障或宕机,将导致缓存数据无法被访问。此时,系统同样会转向直接访问数据库,从而引发缓存雪崩。
- 系统压力增大:在高并发或大规模用户访问的情况下,系统压力会急剧增大。如果此时缓存无法有效承载这些请求,或者缓存的命中率显著下降,那么大量请求将直接落到数据库上,从而引发缓存雪崩。
为了预防缓存雪崩的发生,可以采取以下措施:
- 避免大量key同时过期:可以通过微调key的过期时间,使其有一定的相差间隔,从而避免大量key同时过期的场景。
- 使用缓存降级策略:在缓存失效或访问压力过大的情况下,可以启动降级策略,如返回默认值或错误信息,以减少对后端系统的压力。
- 缓存预热:在系统启动时,提前将部分或全部热点数据加载到缓存中。
- 后备缓存:使用二级缓存(如本地缓存)作为后备,当主缓存失效时,可以从后备缓存中获取数据。