YOLOv8,即广泛使用的目标检测算法You Only Look Once(YOLO)的第八次迭代,以其速度、准确性和效率而闻名。然而,理解其架构可能具有挑战性,尤其是对于初学者。
在本文中,我们将分解驱动YOLOv8的关键组件,从卷积神经网络和残差块等基本概念开始,逐步过渡到特征金字塔网络和CSPDarknet53等高级结构。最后,你将清楚地理解这些元素如何结合在一起,创造出当今最强大的目标检测模型之一。

1. 卷积架构
卷积神经网络(CNN)基于一系列处理层,最基础的是卷积层和池化层。卷积层使用卷积原理,这是一种图像处理技术,涉及两个矩阵之间的乘法操作。一个矩阵代表输入图像,另一个称为核(或卷积滤波器),生成一个新矩阵,即过滤后的图像。这个过程计算效率高,并有助于突出图像特征,如边缘。
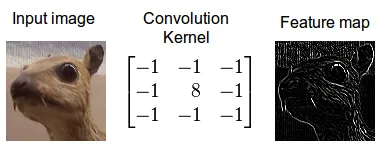
使用滤波器进行边缘检测的卷积过程
每次卷积后,通常应用池化层以通过在较小窗口内对信息进行分组来减小过滤图像的大小,允许在保留基本特征的同时进行压缩。一种常见的池化是最大池化,它取窗口中的最大值。
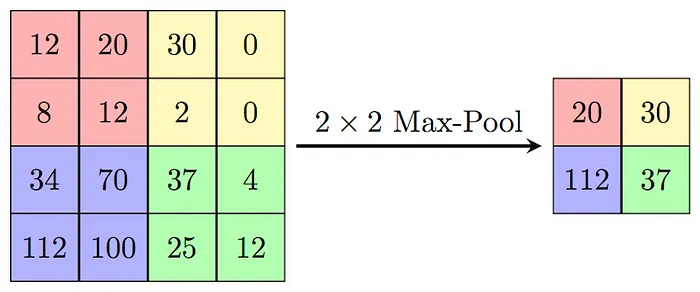
最大池化过程的示意图
在CNN架构中,这种卷积和池化的循环多次重复,允许从图像中逐步提取重要特征。输出数据随后被展平并通过全连接层的神经元。传统上,这一层的输出使用softmax函数处理以产生分类概率。
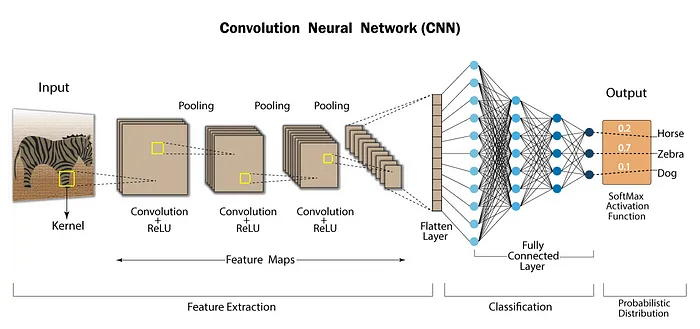
简化的CNN架构图
2. 特征金字塔网络(FPN)
特征金字塔网络(FPN)是一种旨在增强目标检测和图像分割性能的架构。它利用来自不同卷积层的输出来创建特征的金字塔表示,允许更好地检测不同尺度的物体。
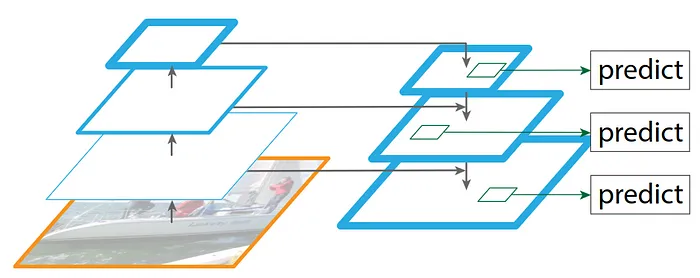
展示多尺度目标检测的特征金字塔网络(FPN)架构图
当我们通过卷积网络的层进行时,更深层的层倾向于捕捉细节,如小物体,而早期层关注更大物体的模式、形状和边缘。FPN的目标不仅是使用最终卷积层的输出,还使用几个中间层的输出来检测多个尺度的物体。这种多尺度检测能力是FPN有效性的关键。
3. 路径聚合网络(PANet)
路径聚合网络(PANet)是对特征金字塔网络(FPN)架构的改进。PANet加强了不同特征尺度之间的连接,并引入了额外的机制以更好地聚合信息。
为了更好地理解FPN和PANet之间的区别,想象一栋有好几层的建筑。每层楼代表图像中的不同细节层次:在底部,你看到细节(小物体),而在顶部,你得到一个更广阔的视角(更大的物体)。
- FPN就像一部从底层(小细节)开始向上到顶层(全局视图)的电梯。在每一层,它收集信息,允许模型在多个尺度上理解图像。
- PANet增加了另一部从顶层返回底层的电梯,在下降过程中合并每一层的信息。简而言之,PANet确保所有信息(来自顶部和底部)都被彻底聚合。
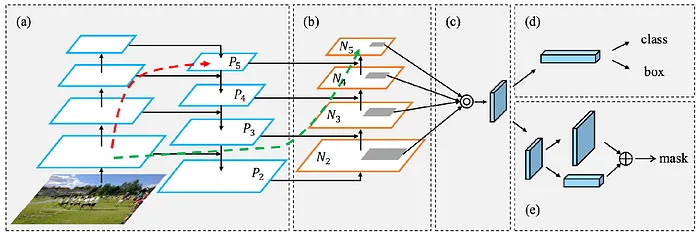
PANet结构
4. 残差块
残差块由ResNet(残差网络)架构引入。它们旨在解决训练非常深的网络时的挑战,例如梯度退化和信息丢失。
残差块通常由两个或三个卷积层组成,但其定义特征是包含一个直接连接(也称为跳过连接),该连接绕过这些层并将块的输入直接链接到其输出。这在下面的图中有说明。输入信息被加到卷积层的输出上,然后传递到下一个阶段。
简单来说,如果块的输入由x表示,F(x)表示卷积层的变换函数,那么块的输出是F(x)+x。

带有跳过连接的残差块
5. CSPNet(跨阶段部分网络)
CSPNet(跨阶段部分网络)是一种用于神经网络的技术,以提高计算机视觉模型的效率和性能。它通过在通过网络块处理之前将特征图分成两部分来工作。一部分像往常一样通过网络流动,而另一部分稍后添加。这种方法减少了网络的计算负载,使其更轻巧,而不会牺牲其处理能力。CSPNet有助于平衡准确性和速度之间的权衡,确保模型保持强大而高效。
6. Darknet53和CSPDarknet53
Darknet53(下图,部分a)是一种卷积神经网络(CNN),主要用作目标检测模型中的主干(主干的概念将在下一节中解释)。它最初是为YOLOv3开发的。Darknet53旨在快速准确,能够从图像中提取相关特征。
CSPDarknet53(下图,部分b)是为YOLOv4开发的Darknet53的增强版本。它结合了CSPNet概念以优化特征学习和减少计算冗余。
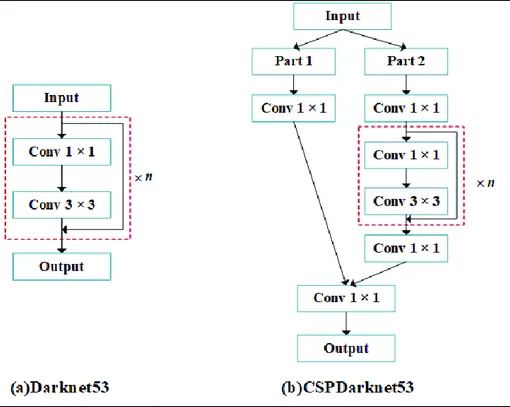
Darknet53(部分a)和CSPDarknet53(部分b)的架构
7. YOLOv8中的一切如何整合
一旦我们理解了这些方法,我们就能更好地理解YOLOv8中的每一层是如何工作的。
事实上,与前身相比,YOLOv8并没有引入重大的技术革新。然而,其架构已经被简化和简化成块。它由23个主要层组成,每个层都包含子层,子层又包含更多的子层。本质上,YOLOv8就像一个俄罗斯套娃层。
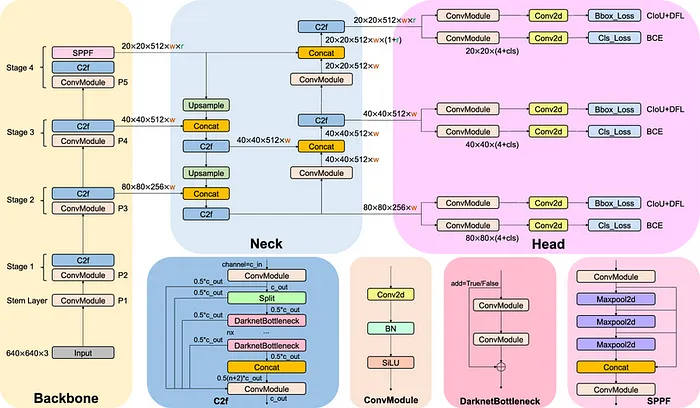
YOLOv8模型架构的详细图示。主干、颈部和头部是我们模型的三个部分,C2f、ConvModule、DarknetBottleneck和SPPF是模块
在线上的YOLOv8图表有时乍一看可能过于复杂。为了更好地观察这些层,模型层字典的分解可以揭示其完整的架构,并澄清它们是如何堆叠的。YOLOv8由七个“ConvModule”层、八个“C2f”层、一个“SPPF”层、两个“Unsample”层、四个“Concat”层和一个最终检测层组成。
import torch
model_path = "my_model.pt"
model_dict = torch.load(model_path, map_location=torch.device('cpu'))
model = model_dict['model']
print(model)通过可视化每层的组件,我们可以看到它们如何适应更广泛的架构。YOLOv8可以分为三个关键部分:
- 主干:这部分负责从输入图像中提取特征。它使用CSPDarknet53的修改版本,旨在在早期层捕获简单的模式,如边缘和纹理。当我们深入网络时,它捕获图像的更详细特征。
- 颈部:这部分负责融合主干提取的特征。它使用PANet(路径聚合网络)结合不同尺度的特征。卷积层P3、P4和P5被传输到金字塔的各个部分(层11、14和20),以确保模型可以检测各种大小的物体。
- 头部:这由三个检测头组成,它们连接到PANet的三个输出。这些检测头生成边界框,分配置信度分数,并根据其类别对框进行分类。它们还消除了对同一物体的冗余检测,这些检测可能出现在不同的尺度上。
Backbone:
ConvModule (Layer 0) - P1
ConvModule (Layer 1) - P2
ConvModule (Layer 2)
C2f (Layer 3)
ConvModule (Layer 4) - P3
C2f (Layer 5)
ConvModule (Layer 6) - P4
C2f (Layer 7)
SPPF (Layer 9)
Neck:
Upsample (Layer 10)
Concat (Layer 11)
C2f (Layer 12)
Upsample (Layer 13)
Concat (Layer 14)
C2f (Layer 15)
ConvModule (Layer 16)
Concat (Layer 17)
C2f (Layer 18)
Head:
ConvModule (Layer 19)
Concat (Layer 20)
C2f (Layer 21)
Detection Layer (Layer 22) 尽管Ultralytics(YOLOv8的开发者)在其官方模型表示中没有明确标记这三个部分,但这种划分被社区普遍接受,因为它反映了以前YOLO版本的结构,并有助于简化模型的理解。