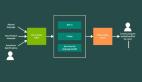
在提升大型语言模型(LLM)在数学推理方面的能力时,一个常用的方法是训练一个奖励模型(reward model)或验证器(verifier),也可以利用强化学习在测试阶段(test-time)对所有解决方案进行重排序。
通常情况下,验证器的预测是整个推理过程的结果,即结果奖励模型(ORM,outcome reward models),但这种奖励信号过于稀疏,模型难以从中学习,并且搜索过程的效率也不高;理论上,通过细粒度的监督数据可以缓解这一问题。
在推理方面,先前有研究已经训练了过程奖励模型(PRMs,process reward models),在搜索的每一步或在强化学习期间分配中间奖励,不过PRM数据都来源于人工标注,不具备可扩展性。
虽然也有研究者训练PRMs来预测自动生成的标注,类似于强化学习中的价值函数,但到目前为止,自动化的PRMs与ORMs相比,性能仅仅提高了1-2%,引发了业界对该技术的质疑。
PRM可以用来执行搜索,或者作为密集奖励(dense rewards)来提升基础策略,所以问题的核心变成了:到底该「如何设计流程奖励」?
最近,Google Research、Google DeepMind和卡内基梅隆大学的研究人员联合发布了一篇论文,主要思路是,每一步的过程奖励都应该对整个过程进行度量:在采取该步骤「之前」和「之后」,模型在生成正确回复概率(likelihood)的变化程度,对应于强化学习中步骤级别优势(step-level advantages)的概念;最重要的是,该过程应该根据与基本策略(basic policy)不同的证明政策(prover policy)来度量。

论文链接:https://arxiv.org/pdf/2410.08146
研究人员从理论上描述了一组好的证明器,并用实验证明了,优化来自证明器的过程奖励可以改善测试时搜索和在线强化学习期间的探索,并且可以通过经验观察到,弱证明器策略可以显着改善更强的基础策略。
通过训练过程优势验证器 (PAV,process advantage verifiers) 来预测证明器的过程,结果表明,与 ORM 相比,针对 PAV 的测试时搜索准确率提升了8%,计算效率提升了1.5到5倍;使用PAV的密集奖励进行在线RL,实现了在样本效率上5-6倍的提升,比ORM的准确率提升了6%
定义过程奖励
为了解决前面提到的奖励不确定性,研究人员训练了带有自动标注的过程奖励模型(PRMs),以便在测试时搜索和在线强化学习(RL)期间,通过优化训练后的PRMs提供的密集奖励来提高基础策略的计算和样本效率。
为此,文中主要解决了两个问题:
1. 每一步的过程奖励应该度量(measure)什么?
2. 应该使用什么样的自动数据收集策略来训练预测PRMs?
传统的方法主要通过度量数学正确性或步骤的相关性来实现的,但这种监督信号是否能够最大程度地改进基础策略尚不清楚,例如策略可能需要生成重复的,在测试时搜索和RL期间不正确的步骤来探索和发现最终答案。
研究人员的关键想法是,衡量逐步骤过程奖励(在采取步骤之前和之后到达正确最终答案的可能性的变化),对于测试时的beam search和在线强化学习都是有效的。
强化那些不管是在正确或错误轨迹中出现都取得进展的步骤,可以在最初步骤中多样化可能答案的探索(exploration),在解决问题方法不明确时可以起到很重要的作用。
从形式上来讲,这种奖励对应于强化学习中的逐步骤优势( per-step advantages),经验表明,使用优势以及ORM奖励比常见的使用未来成功概率(future probabilities of success)或𝑄值来搜索和强化学习都表现得更好,主要是因为,在有限的计算和采样约束下,𝑄值主要「利用」(exploit)状态,而优势也「探索」(explore)对最终答案最有贡献的步骤。

在回答第二个问题时,研究人员首先注意到,在大多数步骤中,基础策略下的优势接近于0,因此对搜索或RL没有信息量。
此外,无论基础策略的强度如何,使用其自身的逐步骤优势作为RL中的过程奖励,会导致与仅使用结果奖励进行RL相同的基础策略更新(因为标准策略梯度算法已经计算了优势)。
因此,研究人员提出使用在不同的证明策略下通过滚动估计的优势作为过程奖励。

然后应该如何选择证明策略?
一个很自然的想法/猜测是使用一个非常强大的证明策略,但研究人员发现,在过于强大的证明策略下,模型可以从任意步骤中走向成功,无法区分出好和坏的步骤;而对于非常弱的证明策略来说,也有类似的结果。
在理论上,研究人员在文中将上述直觉给形式化为,与基础策略互补的策略即为好的证明器,能够充分对比基础策略生成的步骤优势,同时仍然生成与基础策略优势相关的步骤级优势的策略。
例如,对于对应于基础策略的Best-of-𝐾策略,经验发现,对应于𝐾>1的证明策略更能够改进基础策略;与直觉相反,互补证明策略的集合也包含了比基础策略更差的策略。
为了预测这些证明策略的优势,研究人员训练了密集的验证器,即过程优势验证器(PAV,process advantage verifiers),加速了RL和搜索的样本和计算效率;文中为训练PAV规定了实际的工作流程,并在一系列2B、9B和27B Gemma2模型上展示了有效性。

通过从证明策略中采样「种子」解决方案轨迹,以估计种子轨迹的每个前缀的𝑄值,并从同一策略中进行部分滚动(partial rollouts)来收集PAV训练数据,工作流程规定了种子和部分滚动的有利比例。
实证结果显示,对于相同的测试时计算预算,针对训练有素的PAV的beam search在准确性上比针对ORM重新排序完整轨迹高出>8%,计算效率提高了1.5-5倍。

PAV的密集奖励通过积极修剪解决方案的组合空间,并专注于多样化的可能序列集,提高了搜索期间步骤级探索的效率。
此外,文中首次展示了使用PAV作为强化学习中的密集奖励,与仅使用结果奖励相比,数据效率提高了6倍;使用PAV训练的基础策略也实现了8倍更好的Pass @𝑁性能(在𝑁次尝试中采样正确解决方案的概率),从而为任何测试时重新排序器的性能提供了更高的上限。
最后,使用PAV进行强化学习,可以发现SFT策略在非常大的预算下也无法应对的难题解决方案。