作为运维对象的数据库是数据化存在的,这些数据包括配置数据、运行数据、变更数据以及分析诊断数据等等,贯穿了运维对象的全生命周期,是数据库数字化运维与优化的基础和核心。对于数据库运维部门而言主要关注点是运行数据,通过指标的形式进行获取,在此基础上可以产生诊断、告警之类的数据,如果配合AI技术,甚至可以进行一些预测。
数据库指标集的构建是数据库运维自动化和智能化的基础,因此必须加以重视。在做数据库指标设计的时候,往往会受限于早些年的网管系统建设思路,过度借鉴SNMP的MIB库。这些基于传统思路设计的指标集在静态配置信息上十分值得借鉴,但是动态指标往往过于简单,无法适应当前数据库运维的需要。在做数据库指标集设计的时候,要从运维工作的要点出发同时结合当前数字化运维的需求,从对数据库系统进行全面的数字化描述的角度入手,才能让数据库的指标集在实际运维工作中实用、好用。
在实际运维工作中,指标并非空中楼阁,也并非学术范畴,如果一个指标在监控、运维、优化、评估、审计等工作中没有使用场景,那么这个指标可能是没有任何采集价值的。而分析某个重要问题所需要的指标不存在 或者无法直接采集到,那么我们就需要想尽一切办法将其指标化。
数据库内部会存在多个组件,因此运行时需要采集的指标数量还是非常多的,少的几十个,多的能上千,为了便于管理,需要对这些指标进行分类。比如对于某个国产数据库,一般在运维时会关注数据库以下方面的运行情况:
- 配置:影响对象运行的主要参数、资源设置,有些配置是动态的,不能只做一次性采集
- 资源:运维对象涉及的各种内外资源的使用情况
- 负载:运维对象及其所有组件的活动量统计
- 性能:主要是指运维对象执行各项任务的响应时间
- 效率:主要是指运维对象在进行内部处理时最优路径的选择比率
- 并发:内部资源或数据结构的争用情况
- 集群:集群中的成员对象之间发生的活动统计
- 总体:包括总体运行状态、复制状态、备份情况、日志错误统计、安全类统计之类的指标
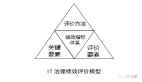
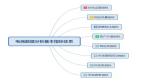
 图片
图片
对数据库的指标进行梳理,可以将数据库的指标按照管理类、配置类和技术类三大类进行归类。管理类指标主要体现数据库与上下游之间的关联关系,数据库不能脱离存储、服务器等独立存在,因此必须关心其关联对象的指标,另外在运维方面有什么关注点,也应该进行指标化。比如容量、负载、资源等,要根据管理特性设计相关的指标进行管理。数据库的配置文件、配置信息等也需要指标化管理,指标化管理有助于对数据库对象进行全面的数字化描述和展示,同时一些负载和并发相关的指标的基线与波动特性也与配置有关。技术类的指标包含来自于数据库本身的指标和通过对日志分析产生的指标,日志事件指标化是对日志进行强管理的有效措施。
在指标设计的时候还要关注的就是指标的可观测性和可评估性。指标所表达的含义一定是DBA可观测的,或者是自动化算法可评估的。比如数据库启动以来的总执行数,这个指标的可观测性和可评估性都不佳,因此我们需要通过这个指标和时间戳计算出某个时间段内平均每秒的执行数,这个指标的可观测性就优于总执行数。最近一分钟内CURSOR缓冲的平均命中数和平均丢失数指标的可观测性是不错的,但是不同负载的系统这些指标的差异很大,因此其可评估性不佳。如果计算出最近一分钟内CURSOR缓冲的命中率,就可以很方便地用于评估CURSOR缓冲的效率了。