译者 | 李睿
审校 | 重楼
如今,人工智能服务的迅速崛起创造了对计算资源的巨大需求,而如何有效管理这些资源成为一项关键挑战。虽然使用Kubernetes运行人工智能工作负载已经取得了长足的进步,但基于动态需求优化调度仍然是一个亟待改进的领域。在全球范围内,许多组织面临与GPU集群的成本和可用性相关的限制,并且通常依赖于这些计算集群来进行推理工作负载和持续的模型训练和微调。

Kubernetes中的人工智能模型训练和模型推理
与推理相比,训练通常需要更多的计算能力。另一方面,使用推理的频率远高于训练,这是因为它被用于在许多应用程序中反复进行预测。本文将探索如何利用Kubernetes的先进功能,通过根据需要动态高效地对工作负载进行优先级排序来优化资源分配。
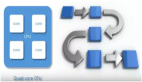
图1展示了训练与推理的过程。对于人工智能模型的训练,工作负载运行的频率可能较低,但需要更多的计算资源,因为实际上是在“教”它如何响应新数据。一旦经过训练,就会部署人工智能模型,并经常在GPU计算实例上运行,以提供低延迟的最佳结果。因此,推理将更频繁地运行,但强度不会那么大。与此同时,开发人员可能需要重新训练模型以容纳新数据,甚至尝试使用其他需要在部署前进行训练的模型。
 图1 人工智能模型训练vs. 人工智能模型推理
图1 人工智能模型训练vs. 人工智能模型推理
人工智能工作负载与高性能计算(HPC)工作负载类似,尤其是在训练方面。Kubernetes并不是为HPC设计的,但是由于Kubernetes是开源的,并且很大程度上是由社区推动的,因此在这个领域出现了快速的创新。而对优化的需求推动了KubeFlow和Kueue等工具的开发。
Kubernetes的人工智能工作负载
KubeFlow使用管道将数据科学中的步骤简化为逻辑操作块,并提供了许多可以插入这些步骤的库,从而帮助开发人员快速上手并顺利运行。
Kueue提供了多种资源“风格”,使其能够根据当时可用的硬件配置定制工作负载,并相应地调度相应的工作负载(当然,其功能远不止于此)。社区在这些工具及其他工具方面出色地解决了扩展、效率、分发和调度等问题。
以下是一个示例,展示了如何使用Kubernetes在支持远程直接内存访问RDMA (RoCEv2)的GPU集群上调度和优先考虑训练和推理任务。创建一些示例代码来演示这个概念。注:在代码中,使用了虚构的网站gpuconfig.com表示GPU制造商。此外,<gpu name>是希望指定的特定GPU的占位符。
这个Kubernetes配置演示了如何使用RDMA主干网对GPU节点上的作业进行优先级排序。以下分解其中的关键组件:
1. PriorityClasses:为GPU的任务定义了两个优先级类:
- high-priority-<gpu name>:用于需要立即执行的关键任务。
- medium-priority-<gpu name>:用于重要但必要时可以等待的任务。
2. Pod规范:创建了两个示例Pod来展示如何使用这些优先级类:
- high-priority-gpu-job:使用high-priority-<gpu name>类。
- medium-priority-gpu-job:使用medium-priority-<gpu name>类。
3.节点选择:两个pod都使用nodeSelector来确保它们被调度到具有RDMA的特定GPU节点上。
4.资源请求:每个pod请求一个GPU:
Kubernetes使用优先级类别来决定Pod的调度顺序,以及在系统资源紧张时决定哪些Pod应被优先移除。以下是一个使用高优先级类别创建CronJob的示例:
Kubernetes中的GPU资源管理
以下是Kubernetes中GPU资源管理的一些示例。
在过去,了解硬件的当前状态以确定工作负载的优先级可能是一项挑战,但得益于开源工具,现在已经有了解决方案。为了监控GPU利用率,采用了诸如Prometheus和Grafana等工具。以下是一个用于抓取GPU指标的Prometheus配置示例:
以下是一个简单的Python脚本,使用它来根据利用率指标优化GPU分配:
该脚本用于检查Pod的GPU利用率,并在利用率较低时减少资源分配。该脚本作为优化资源使用的一项功能运行。
利用Kubernetes管理GPU和CPU资源
因此,利用Kubernetes和OCI Kubernetes引擎(OKE)在人工智能模型的训练和推理工作负载中动态管理GPU和CPU资源。具体来说,专注于利用RDMA(RoCEv2)功能调整GPU分配的大小。开发人员开发了Kubernetes配置、Helm图,包括自定义优先级类、节点选择器和资源配额,以确保高优先级和中优先级人工智能任务的最佳调度和资源优先级。
通过利用Kubernetes的灵活性和OKE在Oracle Cloud Infrastructure(OCI)上的管理能力,平衡了训练的繁重计算需求和推理的较轻计算需求。这确保了资源的动态分配,减少了资源浪费,同时保持了关键任务的高性能。此外,还集成了Prometheus等监控工具以跟踪GPU利用率,并使用Python脚本自动调整分配。这种自动化有助于优化性能,同时管理成本和可用性。
结语
在这里概述的解决方案普遍适用于使用Kubernetes进行AI/ML工作负载的云平台和内部部署平台。而无论是硬件还是任何其他计算平台,使用Kubernetes进行动态调度和资源管理的关键原则都是相同的。Kubernetes允许组织有效地对工作负载进行优先级排序,优化他们对任何可用硬件资源的使用。通过采用相同的方法,组织可以微调其基础设施,减少瓶颈,降低资源闲置率,从而实现更高效、更具成本效益的运营。
原文标题:Right-Sizing GPU and CPU Resources For Training and Inferencing Using Kubernetes,作者:Sanjay Basu,Victor Agreda