在Java编程中,Map 和 Set 是两个非常重要的集合接口,它们在数据存储和操作方面发挥着重要作用。无论是日常开发还是技术面试,对这两个接口的理解和应用都是不可或缺的。

详解Map集合
Map接口定义概览
Map即映射集,是线上就是将对应的key映射到对应value上,由此构成一个数学上的映射的概念,该适合存储不可重复键值对类型的元素,key不可重复,value可重复,我们可以通过key找到对应的value:
An object that maps keys to values. A map cannot contain duplicate keys; each key can map to at most one value.
HashMap(重点)
JDK1.8的HashMap默认是由数组+链表/红黑树组成,通过key算得hash寻址从而定位到Map底层数组的索引位置。在进行put操作时,若冲突时使用拉链法解决冲突,如下面这段代码所示,当相同索引位置存储的是链表时,它会进行for循环定位到相同hash值的索引位置的尾节点进行追加。当链表长度大于8且数组长度大于64的情况下,链表会进行树化变成红黑树,减少元素搜索时间。
注意 : 若长度小于64链表长度大于8只会HashMap底层数组的扩容操作,对此我们给出Map进行put操作时将元素添加到链表结尾的代码段,可以看到当链表元素大于等于8时会尝试调用treeifyBin进行树化操作:
final V putVal(int hash, K key, V value, boolean onlyIfAbsent,
boolean evict) {
//......
for (int binCount = 0; ; ++binCount) {
//遍历找到空位尝试插入
if ((e = p.next) == null) {
p.next = newNode(hash, key, value, null);
//如果链表元素加上本次插入元素大于8( TREEIFY_THRESHOLD )时,则尝试进行树化操作
if (binCount >= TREEIFY_THRESHOLD - 1)
treeifyBin(tab, hash);
break;
}
//.......
}
//......
}对应我们步入treeifyBin即可直接印证我们的逻辑,当底层数组空间小于64时只会进行数组扩容,而非针对当前bucket的树化操作:
final void treeifyBin(Node<K,V>[] tab, int hash) {
int n, index; Node<K,V> e;
//若当前数组空间小于64则直接会进行数组空间扩容
if (tab == null || (n = tab.length) < MIN_TREEIFY_CAPACITY)
resize();
else if ((e = tab[index = (n - 1) & hash]) != null) {//反之进行树化操作
TreeNode<K,V> hd = null, tl = null;
do {
//......
} while ((e = e.next) != null);
if ((tab[index] = hd) != null)
hd.treeify(tab);
}
}详解Hashtable核心添加操作
Hashtable底层也是由数组+链表(主要用于解决冲突)组成的,操作时都会上锁,可以保证线程安全,底层数组是 Hashtable 的主体,在插入发生冲突时,会通过拉链法即将节点追加到同索引位置的节点后面:
public synchronized V put(K key, V value) {
//......
//插入元素寻址操作
Entry<?,?> tab[] = table;
int hash = key.hashCode();
int index = (hash & 0x7FFFFFFF) % tab.length;
//修改操作时,通过遍历对应index位置的链表完成覆盖操作
@SuppressWarnings("unchecked")
Entry<K,V> entry = (Entry<K,V>)tab[index];
for(; entry != null ; entry = entry.next) {
if ((entry.hash == hash) && entry.key.equals(key)) {
V old = entry.value;
entry.value = value;
return old;
}
}
//发生冲突时,会将节点追加到同索引位置的节点后面
addEntry(hash, key, value, index);
return null;详解Set集合
Set基本核心概念
Set集合不可包重复的元素,即如果两个元素在equals方法下判定为相等就只能存储其中一个,这意味着该集合也最多包含一个null的元素,它常用于一些需要进行去重的场景。
//HashSet底层复用了Map的put方法,value统一使用PRESENT对象
private static final Object PRESENT = new Object();
public boolean add(E e) {
// 返回null说明当前插入时并没有覆盖相同元素
return map.put(e, PRESENT)==null;
}Set有两种我们比较熟悉的实现:
- HashSet:HashSet要求数据唯一,但是存储是无序的(底层通过Hash算法实现寻址),所以基于面向对象思想复用原则,Java设计者就通过聚合关系封装HashMap,基于HashMap的key实现了HashSet:
//HashSet底层复用了Map的put方法,value统一使用PRESENT对象
private static final Object PRESENT = new Object();
public boolean add(E e) {
// 返回null说明当前插入时并没有覆盖相同元素
return map.put(e, PRESENT)==null;
}- LinkedHashSet:LinkedHashSet即通过聚合封装LinkedHashMap实现的。
- TreeSet:TreeSet底层也是TreeMap,一种基于红黑树实现的有序树O(logN)级别的黑平衡树:
A Red-Black tree based NavigableMap implementation. The map is sorted according to the natural ordering of its keys, or by a Comparator provided at map creation time, depending on which constructor is used.
对应的从源码中我们也可以看出TreeSet底层是对TreeMap的复用:
public TreeSet() {
this(new TreeMap<E,Object>());
}HashMap 和 Hashtable 的区别(重点)
针对该问题,笔者建议从以下5个角度进行探讨:
(1) 从线程安全角度:HashMap 操作是线程不安全、Hashtable 是线程安全,这一点我们已经在上文中源码进行了相应的介绍,这里就不多做赘述了。
(2) 从底层数据结构角度:HashMap 初始情况是数组+链表,特定情况下会变数组+红黑树,Hashtable 则是数组+链表。
(3) 从保存数值角度:HashMap 允许null键或null值,而Hashtable则不允许null的value,这一点我们可以直接查看的Hashtable的put方法:
public synchronized V put(K key, V value) {
// 如果value为空则抛出空指针异常
if (value == null) {
throw new NullPointerException();
}
//......
}(4) 从初始容量角度考虑:HashMap默认16,对此我们可以通过直接查看源码的定义印证这一点:
static final int DEFAULT_INITIAL_CAPACITY = 1 << 4; // aka 16同时HashMap进行扩容时都是基于当前容量*2,这一点我们可以直接通过resize印证:
final Node<K,V>[] resize() {
//......
if (oldCap > 0) {
if (oldCap >= MAXIMUM_CAPACITY) {
threshold = Integer.MAX_VALUE;
return oldTab;
}
//基于原有数组容量*2得到新的数组空间完成map底层数组扩容
else if ((newCap = oldCap << 1) < MAXIMUM_CAPACITY &&
oldCap >= DEFAULT_INITIAL_CAPACITY)
newThr = oldThr << 1; // double threshold
}
Node<K,V>[] newTab = (Node<K,V>[])new Node[newCap];
//......
}Hashtable 默认的初始大小为 11,之后每次扩充,容量变为原来的 2n+1:
//初始化容量为11
public Hashtable() {
this(11, 0.75f);
}
//扩容方法
protected void rehash() {
int oldCapacity = table.length;
Entry<?,?>[] oldMap = table;
//扩容的容量基于原有空间的2倍+1
int newCapacity = (oldCapacity << 1) + 1;
//......
}(5) 从性能角度考虑:Hashtable 针对冲突总是通过拉链法解决问题,长此以往可能会导致节点查询复杂度退化为O(n)相较于HashMap在达到空间阈值时通过红黑树进行bucket优化来说性能表现会逊色很多。
HashMap 和 HashSet有什么区别
HashSet 聚合了HashMap ,通俗来说就是将HashMap 的key作为自己的值存储来使用:
//HashSet底层本质是通过内部聚合的map完成元素插入操作
public boolean add(E e) {
return map.put(e, PRESENT)==null;
}HashMap 和 TreeMap 有什么区别
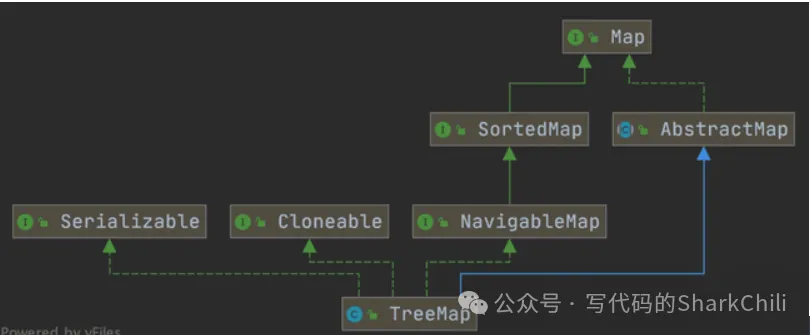
类图如下,TreeMap 底层是有序树,所以对于需要查找最大值或者最小值等场景,TreeMap 相比HashMap更有优势。因为他继承了NavigableMap接口和SortedMap 接口。
如下源码所示,我们需要拿最大值或者最小值可以用这种方式或者最大值或者最小值:
Object o = new Object();
//创建并添加元素
TreeMap<Integer, Object> treeMap = new TreeMap<>();
treeMap.put(3213, o);
treeMap.put(434, o);
treeMap.put(432, o);
treeMap.put(2, o);
treeMap.put(432, o);
treeMap.put(31, o);
//顺序打印
System.out.println(treeMap);
//拿到第一个key
System.out.println(treeMap.firstKey());
//拿到最后一个key
System.out.println(treeMap.lastEntry());输出结果:
{2=231, 31=231, 432=231, 434=231, 3213=231}
2
3213=231HashSet实现去重插入的底层工作机制了解嘛?
当你把对象加入HashSet时其底层执行步骤为:
- HashSet 会先计算对象的hashcode值定位到bucket。
- 若bucket存在元素,则与其hashcode 值作比较,如果没有相符的 hashcode,HashSet 会认为对象没有重复出现,直接允许插入了。
- 但是如果发现有相同 hashcode 值的对象,这时会调用equals()方法来检查 hashcode 相等的对象是否真的相同。
- 如果两者相同,HashSet就会将其直接覆盖返回插入前的值。
对此我们给出HashSet底层的去重的实现,本质上就算map的putVal方法:
final V putVal(int hash, K key, V value, boolean onlyIfAbsent,
boolean evict) {
//......
//bucet不存在元素则直接插入
if ((p = tab[i = (n - 1) & hash]) == null)
tab[i] = newNode(hash, key, value, null);
else {
Node<K,V> e; K k;
//若存在元素,且hash、key、equals相等则覆盖元素并返回旧元素
if (p.hash == hash &&
((k = p.key) == key || (key != null && key.equals(k))))
e = p;
else if (p instanceof TreeNode)
e = ((TreeNode<K,V>)p).putTreeVal(this, tab, hash, key, value);
else {
for (int binCount = 0; ; ++binCount) {
//......
//若存在元素,且hash、key、equals相等则覆盖元素并返回旧元素
if (e.hash == hash &&
((k = e.key) == key || (key != null && key.equals(k))))
break;
p = e;
}
}
//返回旧有元素的值
if (e != null) { // existing mapping for key
V oldValue = e.value;
//......
return oldValue;
}
}
//......
return null;
}HashSet、LinkedHashSet 和 TreeSet 使用场景
- HashSet:可在不要求元素有序但唯一的场景。
- LinkedHashSet:可用于要求元素唯一、插入或者访问有序性的场景,或者FIFO的场景。
- TreeSet:要求支持有序性且按照自定义要求进行排序的元素不可重复的场景。