














译者 | 李睿
审校 | 重楼
Transformer如今已经成为大型语言模型(LLM)和其他序列处理应用程序的主要架构。然而,它们固有的二次方计算复杂性成为了将Transformer扩展至超长序列时的巨大障碍,显著增加了成本。这引发了人们对具有线性复杂性和恒定内存需求的架构的兴趣。
Mila公司和Borealis AI的研究人员重新审视了递归神经网络(RNN)作为Transformer架构的潜在替代方案。他们在发布的一篇论文中,介绍了长短期记忆网络(LSTM)和门控循环单元(GRU)这两种流行的RNN变体的最小化版本——minLSTM和minGRU,这两个模型在训练期间可以完全并行,并且使用的参数显著减少,使它们成为Transformer的快速和有效的替代方案。
Transformer的局限性和RNN的复兴
每当Transformer模型接收的输入序列长度翻倍时,就需要四倍的内存和计算量。这种二次方计算复杂性使得Transformer在处理长序列来说成本高昂,在资源受限的环境中尤为棘手。
另一方面,RNN按顺序处理输入数据,并且相对于序列长度具有线性计算复杂度。它们在推理过程中还需要恒定的内存,这使得它们适合于非常长的序列。然而,传统的RNN存在梯度消失和梯度爆炸的问题。当用于更新神经网络权值的梯度过小或过大,阻碍有效学习时,就会出现梯度消失和梯度爆炸。从而严重影响学习效果。这一局限性制约了RNN学习长期依赖关系的能力。为了解决这一问题,LSTM和GRU引入了创新的门控机制,以精确调控信息在网络中的传递。
尽管传统的LSTM和GRU具有优势,但它们有一个关键的限制:只能按顺序计算。这意味着它们必须在训练期间使用时间反向传播(BPTT),这是一个缓慢的过程,极大地限制了它们扩展到长场景的能力。
Transformer的局限性重新引起了人们对循环模型的兴趣。在过去的一年,引入了新的循环架构,例如S4和Mamba,这些架构有望在实现可比性能的同时解决Transformers的可扩展性问题。这些模型使用“并行前缀扫描”等算法,通过并行化输入序列上的计算来加快训练速度。
重新审视LSTM和GRU
受到最近提出的序列模型之间算法相似性的启发,研究人员重新审视了LSTM和GRU。他们发现,通过从门控机制中消除对先前隐藏状态的依赖,这些模型可以使用并行扫描算法进行高效训练。
传统的LSTM和GRU有多个门来控制网络中的信息流。这些门依赖于之前的隐藏状态来确定保留或丢弃多少当前输入和之前的内存。这创建了一个顺序依赖关系,要求模型一次处理一个令牌。
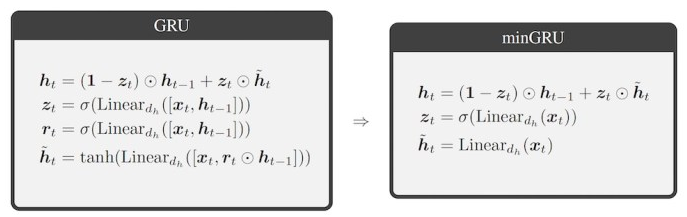
图1 minGRU通过删除组件和计算简化了GRU
研究人员发现,他们可以消除对先前隐藏状态的依赖,同时保持计算中的时间一致性。这使得能够通过并行扫描算法训练模型。他们通过删除一些不必要的计算进一步简化了架构,生成了最小化的LSTM(minLSTM)和最小化的GRU(minGRU),这两种模型不仅使用的参数大幅减少,而且训练速度也得到了显著提升。
minGRU和minLSTM通过实现并行计算解决了传统RNN的训练瓶颈。在T4 GPU上,与传统的序列长度为512个令牌相比,这一变化使得minGRU的速度提高了175倍,minLSTM的速度提高了235倍。随着序列的延长,这种改善变得更加显著。对于长度为4096的序列,minGRU和minLSTM的速度比传统版本快1300倍以上。

图2 minLSTM通过删除不必要的组件和计算来简化LSTM
研究人员写道:“因此,在minGRU需要一天的时间来完成固定次数的训练的情况下,传统的GRU可能需要3年以上的时间。”
与传统GRU相比,minGRU将所需参数的数量减少了87%,与传统LSTM相比,minLSTM将所需参数的数量减少了85%。
最小化RNN与SOTA循环模型
研究人员将minLSTM和minGRU的性能与最先进的循环序列模型Mamba进行了比较。他们测量了训练时间、内存使用情况和多项任务的表现,包括选择性复制、强化学习(RL)和语言建模。
在运行时间方面,minLSTM和minGRU取得了与Mamba相似的结果。虽然它们比传统的RNN使用更多的内存,但它们的内存效率仍然比Mamba高。
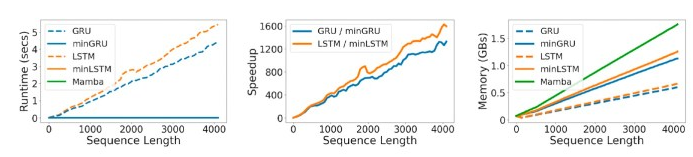
图3 训练最小化 RNN 模型(橙色和蓝色实线)比传统 RNN(虚线)更快,并且比 Mamba使用更少的内存
在选择性复制(需要内容感知推理和记忆的任务)方面,minLSTM和minGRU的表现与Mamba相当。
在D4RL基准的RL实验中,minLSTM和minGRU的性能优于除Decision Mamba之外的所有基线,其中差异很小。
在语言建模任务中,minLSTM和minGRU在训练过程中达到峰值性能的速度略慢于Mamba,但最终收敛的损失更低。值得注意的是,它们比Transformer的效率高得多,Transformer需要2.5倍的时间才能达到最佳性能。
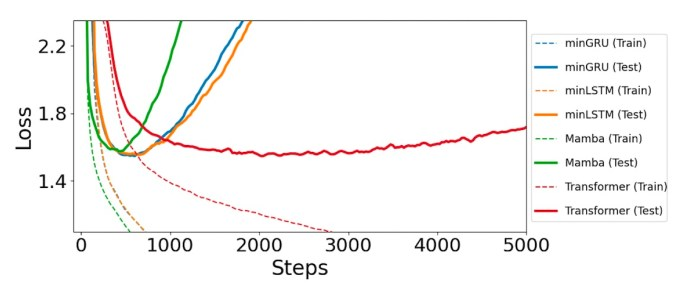
图4 在语言建模任务中,最小化的RNN(橙色和蓝色实线)的损失低于Mamba,收敛速度至少是Transformers的2.5倍
与其他研究Transformer替代方案的类似工作一样,最小化RNN研究的局限性之一是实验的规模。这些架构是否能够在非常大的模型和场景窗口下提供类似的结果还有待观察。
尽管如此,这项研究的结果意义重大,因为研究表明,随着新信息的出现,重新审视原有的想法是值得的。
研究人员在文章中写道:“鉴于这些简化的RNN在实际应用中所展现出的卓越性能,并且它们与众多最新提出的循环序列方法存在着本质上的相似之处,我们不禁反思并提出疑问,‘我们是否仅仅依靠RNN就足以满足需求?’。”
原文标题:Minimized RNNs offer a fast and efficient alternative to Transformers,作者:Ben Dickson



















