HashMap容量初始化
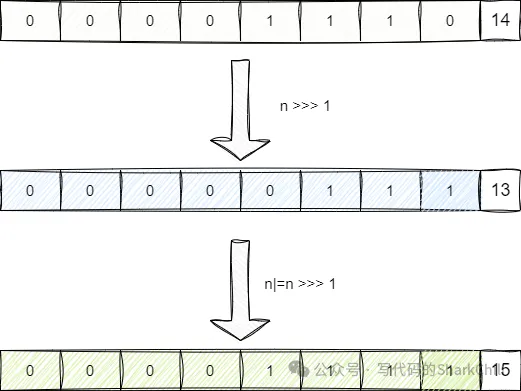
都知道HashMap底层是由数组构成,理论上我们显示声明HashMap容量为n时,其底层数组长度应该也为n,实际并非如此,HashMap在初始化时会基于我们提供的容量n得到一个2的次方的上限阈值,举个例子,假如我们初始化HashMap的代码为new HashMap<>(15),按照HashMap底层的算法,它首先会基于我们的容量减去1即得到14,也就是二进制1110。 然后开始基于当前二进制的值进行移位运算然后和1110进行亦或,这里我们以>>>1运算为例,可以看到减去1的结果为14,通过无符号右移位后得到0111,然后进行按位或运算得到15。
经过不断的无符号右移结合亦或运算,保证了n的低位都是1:
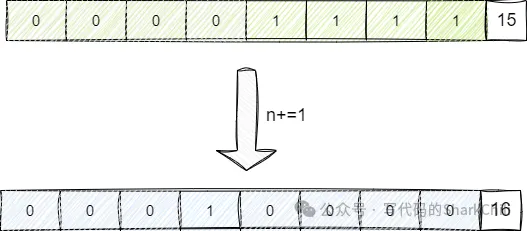
最后基于这个全1的二进制值再加上1,由此得到一个2的次方的二进制,也就是16,也就是2的4次方:
查看HashMap可以印证这段逻辑,可以看到基于我们的初始化设置的容量initialCapacity会调用tableSizeFor获得一个2的次方的阈值:
public HashMap(int initialCapacity, float loadFactor) {
//......
this.loadFactor = loadFactor;//默认为0.75f
this.threshold = tableSizeFor(initialCapacity);
}步入tableSizeFor即可看到笔者上文所说的,先进行无符号右移在进行按位或运算,得到一个低位为全1的二进制数,然后再加上1,得到一个2的次方的上限阈值,由此完成HashMap初始化的第一步,我们得到的上限阈值为16,负载因子取默认值即0.75:
static final int tableSizeFor(int cap) {
//容量减1
int n = cap - 1;
//基于n进行无符号右移得到低位包含1的字段,进行按位或保证低位尽可能都为1
n |= n >>> 1;
n |= n >>> 2;
n |= n >>> 4;
n |= n >>> 8;
n |= n >>> 16;
//基于计算结果加上1,得到2的次方
return (n < 0) ? 1 : (n >= MAXIMUM_CAPACITY) ? MAXIMUM_CAPACITY : n + 1;
}HashMap插入细节
接下来就是插入操作的细节,HashMap初次进行插入会对数组容量进行初始化,对应的加载公式为上限阈值*负载因子,也就是16*0.75按照整形计算方式,最终得到值为12,对此我们给出入口代码putVal,可以看到如果看到底层数组为空则会调用resize进行初始化:
final V putVal(int hash, K key, V value, boolean onlyIfAbsent,
boolean evict) {
Node<K,V>[] tab; Node<K,V> p; int n, i;
//初次插入会调用resize初始化底层数组
if ((tab = table) == null || (n = tab.length) == 0)
n = (tab = resize()).length;
//......
return null;
}步入resize即可看到,初次初始化会基于上限阈值和负载因子相乘然后得到一个取整的2的次方的容量的数组:
final Node<K,V>[] resize() {
Node<K,V>[] oldTab = table;
int oldCap = (oldTab == null) ? 0 : oldTab.length;
//oldThr 设置为当前阈值
int oldThr = threshold;
int newCap, newThr = 0;
//......
//初始化容量为上限阈值的值
else if (oldThr > 0) // initial capacity was placed in threshold
newCap = oldThr;
//......
//默认情况下新的阈值为0,于是步入该逻辑,将容量设置为上限阈值*负载因子然后取整
if (newThr == 0) {
float ft = (float)newCap * loadFactor;
newThr = (newCap < MAXIMUM_CAPACITY && ft < (float)MAXIMUM_CAPACITY ?
(int)ft : Integer.MAX_VALUE);
}
threshold = newThr;
@SuppressWarnings({"rawtypes","unchecked"})
Node<K,V>[] newTab = (Node<K,V>[])new Node[newCap];
//......
}那么问题也就来了,我们愿意是15时进行扩容,按照这套逻辑,我们容量达到12时就会进行扩容,默认情况下HashMap的扩容都是2倍扩容,在极端场景情况下,这种开销是非常大的:
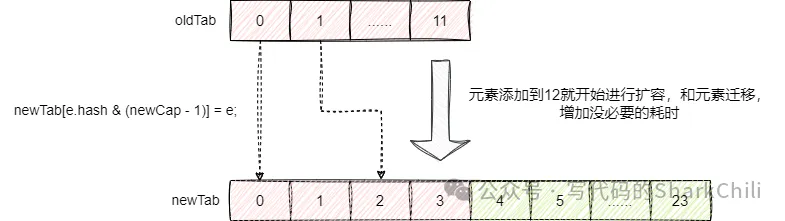
HashMap的容量设置多少合适
解决错误扩容时机的本质原因就是初次put操作*0.75,对此我们可以提前基于当前容量/0.75即可。实际上guava包的newHashMapWithExpectedSize方法就做到了这一点。该方法其底层容量计算公式为(int) ((float) expectedSize / 0.75F + 1.0F),即基于当前容量除0.75再加1,由此抵消put操作初始化时*0.75的伤害:
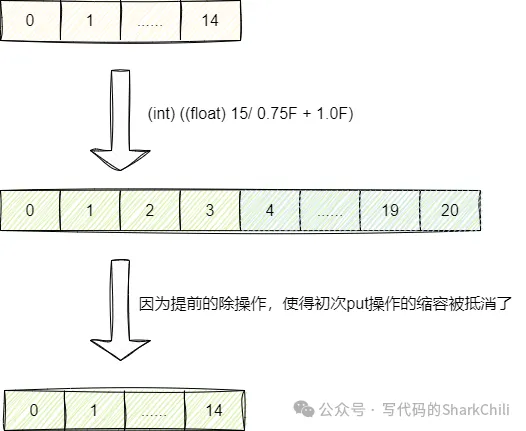
对此我们给出guava包的Maps工具下的newHashMapWithExpectedSize的源代码:
public static <K, V> HashMap<K, V> newHashMapWithExpectedSize(int expectedSize) {
//调用capacity获得可以抵消伤害的容量
return new HashMap<>(capacity(expectedSize));
}
static int capacity(int expectedSize) {
//......
if (expectedSize < Ints.MAX_POWER_OF_TWO) {
//提前/0.75+1进行预分配,用于抵消put操作的缩容
return (int) ((float) expectedSize / 0.75F + 1.0F);
}
return Integer.MAX_VALUE; // any large value
}压测
我们以原生和guava工具包Maps对应的newHashMapWithExpectedSize分别创建2的24次方的容量空间,然后进行键值对插入操作:
public class Main {
private static int SIZE = 1 << 24;
public static void main(String[] args) {
HashMap<Integer, Integer> map = new HashMap<>(SIZE);
HashMap<Integer, Integer> map2 = Maps.newHashMapWithExpectedSize(SIZE);
batchSave(map);
batchSave(map2);
}
private static void batchSave(HashMap<Integer, Integer> map) {
long start = System.currentTimeMillis();
for (int i = 0; i < SIZE; i++) {
map.put(i, i);
}
long end = System.currentTimeMillis();
System.out.println((end - start) + "ms");
}
}可以看到,使用guava的API操作时间整整少了7s左右:
22821ms
15831ms