我们还是用一张图先概括所有的要点:
 图片
图片
批量发送与压缩
Kafka发送消息时,首先将消息进行批量打包,然后压缩后通过网络传输,Producer可以通过GZIP或Snappy格式对消息集合进行压缩。这样可以减少网络传输的开销,同时也可以利用压缩算法来降低磁盘存储的空间占用。
优秀的网络模型
Kafka使用了基于Java NIO的网络框架,其实也是个 reactor的模型。他的设计中,Accepter 作为一个 main reactor,里面包含了 child reactor 即 processor,然后发送和接收都是通过队列的方式异步进行[1]。
 图片
图片
磁盘顺序写
与随机访问相比,磁盘上的顺序写操作要快得多。Kafka将每个分区的日志作为一系列连续的文件段进行管理,并且总是追加到当前活动的日志文件末尾。
页缓存技术(MMAP内存映射)
即便是顺序写入硬盘,硬盘的访问速度还是不可能追上内存。所以 Kafka 的数据并不是实时的写入硬盘 ,它充分利用了现代操作系统页缓存来利用内存提高 I/O 效率。kafka在写数据的时候,会先将数据写入到页缓存,满足一定条件后刷写到磁盘上,可以保证更高的读写性能。
操作系统本身有一层缓存,叫做page cache,是在内存里的缓存,我们也可以称之为os cache,意思就是操作系统自己管理的缓存。你在写入磁盘文件的时候,可以直接写入这个os cache里,也就是仅仅写入内存中,接下来由操作系统自己决定什么时候把os cache里的数据真的刷入磁盘文件中[2]。

MMAP将磁盘文件映射到内存,用户通过修改内存就能修改磁盘文件。通过MMAP,进程像读写硬盘一样读写内存(当然是虚拟机内存)。使用这种方式可以获取很大的 I/O 提升,省去了用户空间到内核空间复制的开销。
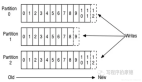
分区并发
Kafka的分区机制可以实现高并发的数据消费。Kafka中的topic中的内容可以分在多个分区(partition)存储,每个partition又分为多个段segment,所以每次操作都是针对一小部分做操作,很轻便,并且增加并行操作的能力,每个分区都是独立的、有序的消息队列。
消费者组内的不同成员可以并行地消费不同的分区,从而实现了水平扩展性和更高的并发度。这种设计使得Kafka能够很好地支持大规模的消息处理场景。
Sendfile零拷贝
当客户端请求读取数据时,Kafka可以利用操作系统级别的零拷贝特性直接将数据从磁盘传输给网络接口,而不需要经过应用程序缓冲区,这样就减少了不必要的数据复制过程。Kafka 使用到了 mmap 和 sendfile 的方式来实现零拷贝。分别对应 Java 的 MappedByteBuffer 和 FileChannel.transferTo。如下图[4]:
 图片
图片
结语
Kafka是一个非常优秀的消息系统,它提供了高吞吐量、低延迟和高可靠性等特性。通过使用批量发送与压缩、优秀的网络模型、磁盘顺序写、页缓存、分区并发、sendfile零拷贝等技术,Kafka可实现百万级高吞吐量。
参考:
[1] https://juejin.cn/post/7276814487054532645
[2] https://blog.csdn.net/CSDN2497242041/article/details/120458401
[3] https://www.jianshu.com/p/53b8ec516a0b
[4] https://mp.weixin.qq.com/s/MLQzOv2lFV_NL1tm5rAZ-w
[5] https://mp.weixin.qq.com/s/iJJvgmwob9Ci6zqYGwpKtw
[6] https://developer.aliyun.com/article/939817