本文经自动驾驶之心公众号授权转载,转载请联系出处。
写在前面&笔者的个人理解
近年来,自动驾驶技术发展迅速,在驾驶感知、运动预测、规划等领域取得了重大进展,为实现更准确、更安全的驾驶决策奠定了坚实的基础。其中,端到端自动驾驶技术取得了重大突破,端到端方法以大规模数据为基础,展现出卓越的规划能力。此外,大型视觉语言模型已经表现出越来越强大的图像理解和推理能力。通过利用其常识和逻辑,LVLM 可以分析驾驶环境并在复杂场景中做出安全的决策。利用大量驾驶数据来提高 LVLM 在自动驾驶中的性能并连接 LVLM 和端到端模型,对于实现安全、稳健和可推广的自动驾驶至关重要。
端到端自动驾驶的常见做法是直接预测未来轨迹或控制信号,而无需决策步骤。然而,这种方法可能会使模型学习更加困难,同时缺乏可解释性。相比之下,当人脑做出详细决策时,由分层高级决策和低级执行组成的系统起着至关重要的作用。此外,端到端模型通常缺乏常识,在简单场景中可能会出错。例如,它们可能会将载有交通锥的卡车误认为是路障,从而触发不必要的刹车。这些限制阻碍了端到端模型的规划性能。因此,本文针对以下涉及到的三个问题进行探索。
- 如何将 LVLM 与端到端模型相结合?目前,LVLM 在自动驾驶规划中的应用主要分为两类。一是直接使用 LVLM 作为规划器来预测轨迹点或控制信号;另一种方法是将 LVLM 与端到端模型相结合。涉及使用 LVLM 预测低频轨迹点,然后通过端到端模型对其进行细化以产生高频轨迹。在本文,我们提出了一种结构化的自动驾驶系统Senna,该系统将大型视觉语言模型与端到端模型相结合,具体来说,大型视觉语言模型用自然语言预测高级规划决策,并将其编码为高维特征,然后输入到端到端自动驾驶系统中。根据高级决策,端到端自动驾驶系统生成最终的规划轨迹。
- 如何设计适合驾驶任务的LVLM?目前流行的LVLM并未专门针对多图像输入进行优化。以前用于驾驶任务的 LVLM 要么仅支持前视输入,这会限制空间感知并增加安全风险,要么可以适应多图像输入但仍然缺乏详细设计或有效性验证。我们提出的Senna,它支持多图像输入来编码环视数据,这对于了解驾驶场景和确保安全至关重要。
- 如何有效地训练驾驶 LVLM?在开发用于驾驶任务的 LVLM 之后,最后一步是确保有效的训练,这需要合适的数据和策略。我们引入了一系列面向规划的问答,旨在增强 VLM 对驾驶场景中规划相关线索的理解,最终实现更准确的规划。
针对上述相关问题的讨论,本文提出了一种将 LVLM 与端到端模型相结合的自动驾驶系统,实现了从高级决策到低级轨迹预测的结构化规划。该算法称之为Senna。并且在nuScenes数据集和DriveX大规模数据集上的大量实验也证明了Senna的SOTA规划性能。

论文链接:https://arxiv.org/pdf/2410.22313
网络结构&技术细节梳理
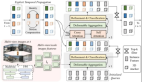
在详细介绍本文提出的算法模型的网络架构细节之前,下图展示了我们提出的Senna算法模型的整体网络结构图。

整体而言,输入的场景信息包括多视角图像序列、用户指令和导航命令。用户指令作为提示输入到Senna-VLM中,其他指令则同时发送给Senna-VLM和Senna-E2E。Senna-VLM将图像和文本信息分别编码为图像和文本标记,然后由LLM进行处理。LLM生成高级决策,这些决策通过元动作编码器编码为高维特征。Senna-E2E根据场景信息和Senna-VLM生成的元动作特征预测最终的规划轨迹。我们设计了一系列面向规划的QA来训练Senna-VLM,这些QA不需要人工注释,并且可以完全通过自动标记流程大规模生成。
驾驶场景理解
了解驾驶场景中的关键因素对于安全准确地进行规划至关重要。我们设计了一系列面向规划的 QA,以增强 Senna-VLM 对驾驶场景的理解。每种类型的 QA 的细节如下图所示。用于生成这些 QA 的原始数据(例如 3D 物体检测框和物体跟踪轨迹)可以通过自动注释系统获得。此外,描述性 QA 可以由 GPT-4o 等 LVLM 生成。

- 场景描述:我们利用预先训练的 LVLM 根据环视图像生成驾驶场景描述。为了避免生成与规划无关的冗余信息,我们在提示中指定了所需的信息,包括:交通状况、环境(例如城市、乡村等)、道路类型(例如铺装道路、高速公路)、天气状况、一天中的时间以及道路状况(例如道路是否平坦或是否有任何障碍物)。通过以这种方式构建提示,我们可以获得简洁且信息丰富的场景描述。
- 交通灯信号检测:交通信号灯有多种类型,但这里我们主要关注最关键的一种:交通信号灯。交通信号灯的状态可分为四种:红色、绿色、黄色和无,其中无表示在自车前方未检测到交通信号灯。
- VRU识别:通过识别环境中的VRU,我们增强了 Senna 对这些关键物体的感知,并提高了规划的安全性。具体来说,我们使用真值 3D 检测结果来获取 VRU 的类别和位置,然后以文本形式描述这些信息。位置信息以自车为中心,包括每个 VRU 相对于自车的横向和纵向距离。我们仅使用 Senna-VLM 来预测距离的整数部分,以在构建距离感知的同时降低学习复杂性。
- 运动意图预测:准确预测其他车辆的未来运动意图是安全规划的先决条件。我们还采用了元动作方法,使 Senna 能够预测周围车辆的未来行为。这增强了 Senna 对场景动态特征的理解,使其能够做出更明智的决策。
- 元动作规划:为了避免使用 LVLM 进行精确的轨迹预测,我们将自身车辆的未来轨迹转换为元动作以进行高级规划。具体而言,元动作包括横向和纵向决策。横向元动作包括左转、直行和右转,而纵向元动作包括加速、保持、减速和停止。横向元动作是根据预测的未来时间步长 T 内的横向位移确定的,纵向元动作是根据预测期间的速度变化确定的。最终的元动作包括横向和纵向元动作。
- 规划解释:我们还使用基于车辆真实未来运动的 LVLM 生成规划解释。换句话说,我们向 LVLM 告知车辆的实际未来运动(例如加速和左转),并要求它们分析此类决策背后的原因。在提示中,我们通过考虑以下影响规划的因素来指导模型分析决策:其他交通参与者的行为、导航信息、道路状况和交通信号灯状态。
Senna-VLM
Senna-VLM 由四个组件组成。视觉编码器以多视角图像序列作为输入并提取图像特征,然后由Driving Vision Adapter进一步编码和压缩,产生图像标记。文本编码器将用户指令和导航命令编码为文本标记。图像和文本标记均输入到 LLM 中,后者预测高级决策。在实践中,我们使用 Vicuna-v1.5-7b作为我们的 LLM。最后,元动作编码器对决策进行编码并输出元动作特征。
我们使用 CLIP 的 ViT-L/14 作为视觉编码器,由于多幅图像输入,导致图像 token 数量过多,不仅减慢了 VLM 的训练和推理速度,还会导致模型崩溃和解码失败。因此,我们引入了 Driving Vision Adapter 模块。该模块不仅将图像特征映射到LLM特征空间,而且还对图像特征进行额外的编码和压缩,以减少图像标记的数量。具体来说,我们采用一组图像查询来对图像特征进行编码并输出图像标记:

其中,MHSA代表的是多头自注意力机制。
为了让 Senna-VLM 能够区分不同视图中的图像特征并建立空间理解,我们为驾驶场景设计了一个简单而有效的环视提示。以正面视图为例,相应的提示是:FRONT VIEW: \n image \n,其中 image 是 LLM 的特殊标记,在生成过程中将被图像标记替换。下图说明了我们提出的多视图提示和图像编码方法的设计。

最后,我们提出了元动作编码器,将LLM输出的高级决策转换为元动作特征。元动作编码器使用一组可学习的嵌入实现从元动作到元动作特征的一对一映射,下面的公式说明了生成元动作特征的过程

随后,元动作特征将被输入到 SennaE2E 中以预测规划轨迹。
Senna-E2E
Senna-E2E 扩展了 VADv2。具体来说,Senna-E2E 的输入包括多视角图像序列、导航命令和元动作特征。它由三个模块组成:感知模块,用于检测动态物体并生成局部地图;运动预测模块,用于预测动态物体的未来轨迹;规划模块,使用一组通过注意力机制与场景特征交互的规划标记来预测规划轨迹。我们将元动作特征集成为 Senna-E2E 的附加交互标记。由于元动作特征采用嵌入向量的形式,因此 Senna-VLM 可以轻松与其他端到端模型结合。Senna-E2E的轨迹规划过程可以表述如下

训练策略
我们为 Senna-VLM 提出了一种三阶段训练策略。第一阶段是混合预训练,我们使用单图像数据训练Driving Vision Adapter,同时保持 Senna-VLM 中其他模块的参数不变。这样可以将图像特征映射到 LLM 特征空间。混合是指使用来自多个来源的数据,包括 LLaVA中使用的指令跟踪数据和我们提出的驾驶场景描述数据。第二阶段是驾驶微调,我们根据之前提出的面向规划的 QA 对 Senna-VLM 进行微调,不包括元动作规划 QA。在此阶段,使用环视多图像输入而不是单图像输入。第三阶段是规划微调,我们仅使用元动作规划 QA 进一步微调 Senna-VLM。
实验结果&评价指标
下图的实验结果展示了 Senna 在高级规划和场景描述方面的表现,并与最先进的开源 LVLM(包括 QwenVL、LLaVA 和 VILA)进行了比较。前三行的结果是通过直接评估原始模型获得的。可以看出,使用预训练权重的模型在驾驶任务上表现不佳,因为它们的训练目标是面向一般理解和对话,而不是专门针对驾驶相关任务而量身定制的。

为了进一步验证 Senna 的优势,我们还使用相同的训练流程在 DriveX 数据集上对这些模型进行了微调。Senna 在高级规划和场景描述方面均优于其他方法。与其他方法的最佳结果相比,Senna 将规划准确率提高了 10.44%。此外,在减速等最关键的驾驶安全决策中,F1 得分从 52.68 提升至 61.99,提升幅度达 17.67%,凸显了Senna在驾驶场景分析和空间理解方面的卓越能力。
此外,我们在下表中展示了 Senna 在 nuScenes 数据集上的轨迹规划性能。为了进行公平比较,我们用 VAD 替换 VADv2 作为端到端模型。与之前将 LVLM 与端到端模型相结合的 SOTA 方法相比,Senna 有效地将平均规划位移误差降低了 29.03%,碰撞率降低了 20.00%。为了避免与使用自车状态特征相关的潜在问题,我们还报告了未使用自车状态特征的结果。通过使用来自 DriveX 数据集的预训练权重初始化模型并在 nuScenes 数据集上进行微调,Senna 实现了最先进的规划性能。与 VAD 相比,平均规划位移误差显着降低了 40.28%,平均碰撞率降低了 45.45%。通过在 DriveX 数据集上进行预训练,然后在 nuScenes 数据集上进行微调,Senna 的性能得到显著增强,展示了其强大的泛化和可转移性。

下表展示了DriveX 数据集上的轨迹规划结果。除了端到端模型 VADv2 之外,我们还引入了两个额外的比较模型。第一个模型将真值规划元动作作为额外的输入特征,旨在验证我们提出的结构化规划策略的性能上限。第二个模型是我们复现的 DriveVLM,它预测低频轨迹而不是元动作,充当 LVLM 和端到端模型之间的连接器。

通过实验结果可以看出,利用真值规划元动作的 VADv2 实现了最低的规划误差,验证了我们提出的结构化规划策略的有效性。预测低频轨迹作为连接器的 DriveVLM仅比 VADv2 显示出微小的改进。相比之下,我们提出的 Senna 在所有方法中提供了最佳的规划性能,将平均规划位移误差大大降低了 14.27%。
结论
在本文中,我们提出了LVLM 与端到端模型相结合,用于结构化规划,从高级决策到低级轨迹规划的自动驾驶系统Senna,大量的实验结果证明了我们提出的Senna算法模型的卓越性能,凸显了通过基于语言的规划将 LVLM 与端到端模型相结合的潜力。