爆火国产3A大作《黑神话·悟空》,如今也能由AI生成了?
一夜之间,国内首个实时视频游戏生成AI,火遍全网。

致敬「西游记」
几天前,专做推理芯片初创Etched曾推出世界首个实时生成AI游戏Oasis,每一帧都是扩散Transformer预测。
无需游戏引擎,就能实现每秒20帧实时渲染,几乎没有延迟。

没想到,GameGen-X一出,再次颠覆了我们对AI游戏的认知。
来自港科大、中科大、港中文等机构联手,提出开放世界视频游戏生成AI,可以实时交互创建游戏。
这是首个专为生成和交互控制开放世界游戏视频而设计的扩散Transformer模型。

论文地址:https://gamegen-x.github.io/
GameGen-X能够模拟游戏引擎特性,实现高质量开放世界游戏生成。比如,创建新角色、动态环境、复杂动作和各种事件等等。

它还能进行交互式控制,根据当前片段预测或更改未来内容,实现游戏模拟。

有网友表示,一切都结束了,中国再次在AI游戏领域拿下第一。

还有人称,这比Oasis看起来更好。

AI实时游戏生成,惊呆歪果仁
老黄曾说过,未来每个像素很快都将会是生成的,并非是渲染的。
不论是从谷歌GameNGen,到Oasis,再到GameGen-X,每一步的进化都在逼近这个预言。
高质量游戏生成
在游戏生成上,GameGen-X不仅能够创建角色,还能生成动作、动态环境、各种事件、开放域。
角色生成
《巫师》的Geralt of Rivia

《荒野大镖客:救赎2》的主角Arthur Morgan

《刺客信条》的Eivor

还有这种偏卡通风的人物——异星探险家

射击游戏中的机械战警RoboCop,机器人角色生成很赛博。

环境生成
不论是春夏秋冬四季,还是山川湖海,各种名胜古迹,都能实时生成。




动作生成
骑摩托车第一人称视角,以及第三人称视角。


驾马车

飞行

事件生成
下雨、下雪、打雷、日起日落、火灾、沙尘暴、海啸.....



开放域生成
在中国城漫游的赛博和尚

血月下的幽灵

穿着斗篷的旅行者走在火星上

多模态交互控制
在多模态交互中,GameGen-X能够支持结构化指令提示、外设操作信号、视频提示的生成。
结构化指令提示
同在沙漠中行走的旅人,你可以通过提示要求,让背景实时变幻。
天空之火

黑暗与星星

日落时分

雾出现

操作信号
游戏中角色向左向右移动,一句话的事。


视频提示
提供一个Canny提示的视频

接下来,就会得到

又或者提供一个运动失量的视频

就会生成一个扬沙的视频

GameGen-X技术
GameGen-X擅长生成多样化和创造性的游戏内容,包括动态环境、多变的角色、引人入胜的事件和复杂的动作,树立了该领域的新标杆。
更为震撼的是,它还提供了交互式可控性,并首次将角色交互和场景内容控制统一起来。
AI根据当前片段预测和更改未来内容,从而实现游戏模拟,赋予了游戏更多的真实性。
它首先生成一个视频片段,以设置环境和角色。
随后,利用当前视频片段和多模态用户控制信号,生成动态响应用户输入的视频片段。
这一过程可被视为模拟现实一般的体验,因为这一过程中,环境和角色都是动态发展的!

GameGen-X的训练过程分为两个阶段,包括基础模型预训练和指令微调。
首先,通过在OGameData-GEN数据集上的文本到视频的生成和视频延续对模型进行预训练,使其具备生成长序列、高质量开放世界游戏视频的能力。
此外,为了实现交互可控性,研究团队在设计InstructNet时纳入了与游戏相关的多模态信号控制专家系统。
这使得模型能够根据用户输入微调潜表征,首次在视频生成中将角色交互和场景内容的调控统一起来。
在指令微调过程中,为了保证不损失生成视频内容的多样性和质量的情况下,实现多模态交互式控制,模型引入了 InstructNet。具体来说,InstructNet 的主要目的是根据指令修改未来的预测。
当没有给出用户输入信号时,视频自然延伸。因此会将预先训练好的基础模型冻结,只利用OGameData-INS数据集更新InstructNet,从而将用户输入(如游戏环境动态的结构化文本指令和角色动作与操作的键盘控制)映射到生成的游戏内容上。
总之,GameGen-X代表了使用生成模型进行开放世界视频游戏设计的一次重大飞跃。它展示了生成模型作为传统渲染技术辅助工具的潜力,有效地将创意生成与交互能力融合在一起。

首个开放世界游戏视频数据集OGameData
为了促进交互式控制游戏生成领域的发展,研究团队构建了开放世界视频游戏数据集(Open-World Video Game Dataset,OGameData),这是首个专为游戏视频生成和交互式控制精心设计的大规模数据集。
它提供游戏特定知识,并包含游戏名称、玩家视角和角色细节等元素。该数据集从150多款下一代游戏中收集而来,其中包括评分、筛选、排序和结构化注释。

OGameData的构建与处理流程
如表1所示,OGameData包含100万个高分辨率视频片段,来源从几分钟到几小时不等。
与其他特定领域的数据集相比,OGameData在文本-视频对的规模、多样性和丰富性方面脱颖而出。
即使与最新的开放域生成数据集Miradata相比,仍然具有提供更多细粒度注释的优势,其在单位时间内提供的注释甚至是Miradata数据集的2倍多!

该数据集具有几个主要特点:OGameData 具有高度精细的文本,并拥有大量可训练的视频-文本对,从而提高了模型训练中文本-视频的一致性。
此外,它还包括两个子集:生成数据集(OGameData-GEN)和指令数据集(OGameData-INS)。
其中OGameData-GEN专门用于训练生成基础模型,而OGameData-INS则针对指令微调和交互式控制任务进行了优化。

OGameData-GEN需要制作详细的注释来描述游戏元数据、场景背景和关键角色,以确保生成基础模型训练所需的全面文本描述。
相比之下,OGameData-INS使用基于指令的简明注释,突出显示初始帧和后续帧之间的差异,重点是描述游戏场景的变化,以便进行交互式生成。

这种结构化注释方法可实现精确的生成和细粒度的控制,允许模型在保留场景的同时修改特定元素。该数据集的高质量得益于10多位人类专家的精心设计。
每个视频片段都配有使用GPT-4o生成的注释,以保持清晰度和连贯性,并确保数据集不受用户界面和视觉伪影的影响。
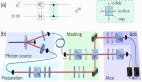
模型架构
在将视频片段进行编码时,为解决时空信息冗余问题,GameGen-X引入了三维时空变分自编码器(3D-VAE),将视频片段压缩为潜表征。
这种压缩技术可以对具有较长帧序列的高分辨率视频进行高效训练。
具体来说,3D-VAE首先进行空间下采样以获得帧级潜特征。此外,它还进行了时间组合,以捕捉时间依赖性并有效减少帧上的冗余。
通过3D-VAE对视频片段进行处理,可以得到一个具有空间-时间信息并降低了维度的潜张量。这样的张量可以支持长视频和高分辨率模型训练,满足游戏内容生成的要求。
GameGen-X还引入了掩码时空扩散Transformer(Masked Spatial-Temporal Diffusion Transformer,MSDiT)。
具体来说,MSDiT结合了空间注意力、时间注意力和交叉注意力机制,可有效生成由文本提示引导的游戏视频。
对于每个时间步长t,模型会处理捕捉帧细节的潜特征z。
空间注意力通过对空间维度(H′、W′)的自注意力来增强帧内关系。时间注意通过在时间维度F′上进行操作,捕捉帧间的依赖关系,从而确保帧间的一致性。
交叉注意力整合了通过文本编码器T5获得的外部文本特征的指导,使视频生成与文本提示的语义信息保持一致。
而掩码机制则可以在扩散处理过程中,将某些帧从噪声添加和去噪中屏蔽掉。
如图4所示,整体框架采用了将成对的空间和时间区块堆叠在一起的设计,其中每个区块都配备了交叉注意和空间或时间注意力机制。

这样的设计使模型能够同时捕捉空间细节、时间序列动态和文本引导,从而使GameGen-X能够生成高保真、时间上一致的视频,并与所提供的文本提示紧密结合。
负责实现交互式控制的指令微调的部分由N个InstructNet模块组成,每个模块利用专门的操作集成式专家层和指令集成式专家层来整合不同的条件。
输出特征被注入到基础模型中以融合原始潜在特征,根据用户输入调制潜在表征,并有效地将输出与用户意图对齐,这使用户能够影响角色动作和场景动态。
InstructNet主要通过视频连续训练来模拟游戏中的控制和反馈机制。此外,还在初始帧中巧妙地添加了高斯噪声,以减少误差累积。
实验结果
为了全面评估GameGen-X在生成高质量、逼真且可交互控制的视频游戏内容方面的能力,研究团队采用了一套十分细致的度量标准。
包括Fréchet Inception Distance(FID)、Fréchet Video Distance(FVD)、文本视频对齐(TVA)、用户偏好度(UP)、运动平滑度(MS)、动态度(DD)、主体一致性(SC) 和成像质量(IQ)。
表2对比了GameGen-X和4个知名开源模型,即Mira、OpenSora Plan1.2、OpenSora1.2和CogVideoX-5B。
值得注意的是,Mira和OpenSora1.2都明确提到在游戏数据上进行训练,而其他两个模型虽然不是专门为此目的设计的,但仍然可以在类似环境中满足某些生成需求。
结果显示,GameGen-X在FID、FVD、TVA、MS和SC等指标上表现良好。这表明GameGen-X在生成高质量和连贯的视频游戏内容方面具有优势,同时保持了竞争性的视觉和技术质量。

此外,团队还使用了有条件的视频片段和密集提示词来评估模型的生成响应。
其中,新引入的指标——成功率(SR),负责衡量模型对控制信号的准确响应频率。这是由人类专家和PLLaVA共同评估的。
SR指标分为两部分:角色动作的成功率(SR-C),评估模型对角色动作的响应能力,以及环境事件的成功率(SR-E),评估模型对天气、光照和物体变化的处理能力。
如表3所示,GameGen-X在控制能力方面优于其他模型,突显了其在生成上下文适宜和互动性游戏内容方面的有效性。
在生成性能方面,有着8fps视频的CogVideo和场景频繁变化的OpenSora1.2,获得了更高的DD。

图5展示了GameGen-X在生成各种角色、环境、动作和事件的多样化生成能力。
这些例子显示模型可以创建刺客和法师等角色,模拟樱花森林和热带雨林等环境,执行飞行和驾驶等复杂动作,并重现暴风雪和暴雨等环境事件。

图6展示了GameGen-X根据文本指令和键盘输入控制环境事件和角色动作的能力。
在提供的示例中,模型有效地操控了场景的各个方面,如光照条件和大气效果,突显了其模拟不同时间和天气条件的能力。此外,角色的动作,主要涉及环境中的导航,通过输入的键盘信号得到精确控制。
通过调整光照和大气等环境因素,模型提供了一个逼真而沉浸的环境。同时,管理角色动作的能力确保生成的内容能够直观地响应用户的互动。
通过这些能力,GameGen-X展示出了在提升开放世界电子游戏模拟的真实感和参与度方面的潜力。

如图7所示,GameGen-X在角色细节、视觉环境和镜头逻辑方面更好地满足了游戏内容的要求,这得益于严格的数据集收集和OGameData的构建。

此外,GameGen-X还与包括Kling、Pika、Runway、Luma和Tongyi在内的其他商业产品进行了比较,如图8所示。
在左侧部分,即最初生成的视频片段中,只有Pika、Kling1.5和GameGen-X正确地遵循了文本描述。其他模型要么未能显示角色,要么将其描绘为进入洞穴而非退出。
在右侧部分,GameGen-X和Kling1.5都成功引导角色走出洞穴。GameGen-X实现了高质量的控制响应,同时保持了一致的镜头逻辑,并遵循了类似游戏的体验。这得益于整体训练框架和InstructNet的设计。

结论
OGameData的开发为模型训练提供了重要的基础,使其能够捕捉开放世界游戏的多样性和复杂性。而通过两阶段的训练过程,GameGen-X实现了内容生成和交互控制之间的相互增强,从而实现了丰富且身临其境般的模拟体验。
除了技术贡献之外,更重要的是:GameGen-X 还为游戏内容设计的未来开辟了新的视野。它表明游戏设计与开发有可能转向更加自动化、数据驱动的流程,从而显著减少游戏内容早期创建所需的手动工作。
通过利用模型来创建身临其境的世界和交互式游戏玩法,我们可能对于玩家自己通过创造性的探索来构建一个游戏的未来越来越近了。
尽管挑战依然存在,GameGen-X代表了游戏设计中向新颖范式迈出的重大飞跃。它为未来的研究和开发奠定了基础,也为生成模型成为创建下一代交互式数字世界的不可或缺的工具铺平了道路。
团队介绍
Haoxuan Che

Haoxuan Che正在香港科技大学(HKUST)攻读计算机科学与工程博士学位。他的主要研究兴趣在于计算机视觉、医学图像分析和可信赖人工智能。
在加入香港科技大学之前,我曾毕业于西北工业大学(NWPU),获得了软件与微电子学院的软件工程学士学位。
Xuanhua He(何炫华)

何炫华目前是中国科学技术大学的硕士生,由Jie Zhang和Chengjun Xie教授指导。他于2022年在厦门大学获得了软件工程学士学位,师从Yongxuan Lai教授。
他的研究兴趣集中在计算机视觉领域,特别是图像超分辨率、图像增强和视频生成。此前,他还曾曾探索过遥感图像处理和联邦学习。