上周的一天,到公司接了杯水刚刚坐稳,就看到 DBA就在群里@ 某个研发帅哥,说“你们表已经有10个索引了,怎么这次还要加呢?”
关于索引,是数据库后台用来加快查询速度的强大工具,索引通过提供快速查找所需数据的方法来增强查询能力。
但我们经常听到这样一句话:“索引是把双刃剑”。
说明索引并不是越多越好,索引可以提高查询的效率,但会降低写数据的效率,有时不恰当的索引还会降低查询的效率。
那我就在想:一张表到底建多少个索引才是合适呢?
要搞懂这个问题,我们就需要弄清楚以下这几个问题:
1)常见的索引分类有哪些?
2)MySQL 是如何使用索引的?
3)一张表最多可以建多少索引?
4)新建索引的规范原则有哪些?
本文我们就一起来展开聊聊这几个问题~
1、常见的索引分类有哪些?
1.1 应用层分类
从应用层面,常见分类:
- 普通索引INDEX:加速查找
- 唯一索引:
- 主键索引PRIMARY KEY:加速查找+约束(不为空、不能重复)
- 唯一索引UNIQUE:加速查找+约束(不能重复)
- 联合索引:
PRIMARY KEY(id,name):联合主键索引
UNIQUE(id,name):联合唯一索引
INDEX(id,name):联合普通索引
1.2 数据结构层分类
从数据结构层面,分类如下:
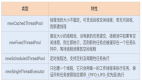
- 哈希(hash)索引
- 基于哈希函数来实现。哈希函数会将索引键值(如数据库表中的某个字段值)作为输入,通过特定的算法运算,生成一个固定长度的哈希值。
- 查询速度快,但不支持范围查找
- B 树(btree)索引
一种平衡的多叉树数据结构。B 树索引会将表中的索引键值按照一定的顺序(如升序或降序)存储在树的节点中。每个节点可以存储多个键值以及指向其他节点的指针。
支持范围查询,但占用空间较大
 图片
图片
2、新建索引的规范原则有哪些?
关于新建索引,通常需要注意以下规范原则:
2.1 最左前缀匹配原则
MySQL 会一直向右匹配直到遇到范围查询(>、<、between、like)就停止匹配
比如a = 1 and b = 2 and c > 3 and d = 4 如果建立(a,b,c,d)顺序的索引,d是用不到索引的;
如果建立(a,b,d,c)的索引则都可以用到,a,b,d的顺序可以任意调整。
2.2 尽量选择区分度高的列作为索引
区分度的公式是:count(distinct col)/count(*),表示字段不重复的比例,比例越大我们扫描的记录数越少。
唯一键的区分度是1,而一些 status 状态、性别等 字段可能在大数据面前区分度就是0。
2.3 索引列不能参与计算
保持索引列“干净”,这个原因其实很简单,b+树中存的都是数据表中的字段值。但是在进行检索时,需要把所有元素都应用函数才能比较,显然成本太大。
比如 from_unixtime(create_time) = ’2014-05-29’ 就不能使用到索引,需要将语句改写成:create_time = unix_timestamp(’2014-05-29’)。
2.4 尽量的扩展索引,不要新建索引
比如表中已经有a的索引,现在要加(a,b)的索引,那么只需要修改原来的索引即可,而不建议再单独去建一个b索引。
3、MySQL 是如何使用索引的?
索引用于快速查找具有特定列值的行,其目的在于提高查询效率。
与我们查阅图书所用的目录是一个道理:先定位到章,然后定位到该章下的一个小节,然后找到页数。相似的例子还有:查字典,查火车车次,飞机航班等。
本质都是:通过不断地缩小想要获取数据的范围来筛选出最终想要的结果,同时把随机的事件变成顺序的事件。
也就是说,有了这种索引机制,我们可以总是用同一种查找方式来锁定数据。
数据库也是一样,但显然要复杂得多,因为不仅面临着等值查询,还有范围查询(>、<、between、in)、模糊查询(like)、并集查询(or)等等。数据库应该选择怎么样的方式来应对所有的问题呢?
大多数 MySQL 索引(PRIMARY KEY、UNIQUEINDEX 和FULLTEXT)都存储在 B树 中。
另外:
空间数据类型使用 R 树;
MEMORYtable 还支持哈希索引;
InnoDB 对 FULLTEXT 索引使用倒排列表。
在 MySQL 中,使用索引进行以下操作:
3.1 = 和 in 可以乱序
比如a = 1 and b = 2 and c = 3 建立(a,b,c)索引可以任意顺序,MySQL 的查询优化器会帮你优化成索引可以识别的形式。
3.2 and 与 or
联合索引:(d,a,b,c)
1)查询条件:
a = 10 and b = 'xxx' and c > 3 and d =4MySQL 会按照联合索引,从左到右的顺序找一个区分度高的索引字段(这样便可以快速锁定很小的范围),加速查询,即按照d—>a->b->c的顺序
2)查询条件:
a = 10 or b = 'xxx' or c > 3 or d =4MySQL 会按照条件的顺序,从左到右依次判断,即a->b->c->d
4、一张表最多可以建多少个索引?
4.1 理论上来说
MySQL 的存储引擎(如 InnoDB、MyISAM 等)本身并没有对一个表能创建的索引数量设置一个固定数值限制,,而是由MySQL数据库引擎内部的数据结构和算法决定的。
从数据库设计和架构的角度,理论上只要满足以下条件,就可以新增创建索引:
- 存储空间允许:每个索引都需要占用一定的磁盘空间来存储索引数据结构,所以只要磁盘空间足够容纳新创建的索引结构及其相关数据,在空间层面就不会因空间不足而无法创建索引。
- 性能可接受:随着索引数量的增加,虽然查询性能在某些情况下可能会因合适的索引而提升,但过多的索引也会带来一些负面效应,比如数据更新(插入、删除、修改操作)时需要同时更新相关索引,这会导致更新操作变慢。只要系统整体性能(包括查询性能和更新性能等)在可接受的范围内,理论上可以继续创建索引。
4.2 实际应用情况
然而在实际应用场景中,通常不会无限制地创建索引。一方面是因为上述提到的性能问题,过多的索引往往会导致数据更新操作变得极为缓慢,严重影响系统的正常运行。
例如,在一个高并发的电商订单处理系统中,如果对订单表的大量字段都创建了索引,那么每一次订单的插入、修改或删除操作,都要花费大量时间来更新相关索引,导致订单处理效率大幅下降。
另一方面,不同的 MySQL 版本以及不同的存储引擎在实际表现上也会有差异。
例如,对于一个拥有百万条记录的用户信息表,在 MySQL 5.7 中按照用户姓氏进行模糊查询,可能需要遍历相当一部分数据,查询速度相对较慢,假设平均每次查询需要 20 秒。而 MySQL 8.0 引入了新的索引算法和数据结构优化,新的索引算法对这种模糊查询的支持更好,同样的查询可能只需要 5 秒左右,性能提升明显。
总结
索引是应用程序设计和开发的一个重要方面。若索引太多,应用程序的性能可能会受到影响。而索引太少,对查询性能又会产生影响,要找到一个平衡点,这对应用程序的性能至关重要。
MySQL 表能创建的索引数量没有一个确切的、通用的绝对上限,而是要综合考虑多方面因素,在满足性能要求和存储空间允许的条件下合理创建索引。
其实做了这么长时间的语句优化后才发现,任何数据库层面的优化都抵不上应用系统的优化,同样是MySQL,可以用来支撑Google/FaceBook/Taobao应用,但可能连你的个人网站都撑不住。套用最近比较流行的话:“查询容易,优化不易,且写且珍惜!”