














详解redis cluster数据迁移过程
节点基本结构定义
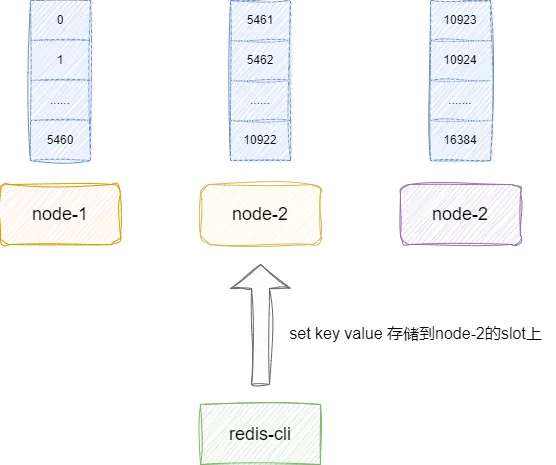
redis集群提供16384个slot,我们可以按需分配给节点上,后续进行键值对存储时,我们就可以按照算法将键值对存到对应slot上的redis服务器上:
集群节点本质就是通过slots这个数组记录当前节点的所管理的情况,这里我们可以看到slots是一个char 数组,长度为REDIS_CLUSTER_SLOTS(16384)除8,这样做的原因是因为:
- char占1个字节,每个字节8位。
- 每个char可以记录8个slot的情况,如果是自己的slot则对应char的某一个位置记录为1:
我们以node-1为例,因为它负责0-5460的节点,所以它的slots0-5460都为1,对应的图解如下所示,可以看到笔者这里省略了后半部分,仅仅表示了0-15位置为1:
对此我们也给出这段redis中节点的定义,即位于cluster.h中的clusterNode这个结构体中,可以看slots这段定义:
typedef struct clusterNode {
//......
//记录集群负责的槽,总的为16384
unsigned char slots[REDIS_CLUSTER_SLOTS/8];
//......
}设置slot后续节点走向
以本文示例为例,我们希望后续节点2的数据全部存到节点1中,那么我们首先需要键入如下两条配置:
# 在节点1上执行,将节点2数据导入到节点1上
CLUSTER SETSLOT 3 IMPORTING node2
# 在节点2上执行,将自己的数据迁移到节点1
CLUSTER SETSLOT 3 MIGRATING node1这两条指最终都会被各自的服务端解析,并调用clusterCommand执行,我们以节点1导入为例,假设我们执行clusterCommand解析到setslot 关键字和importing关键字,即知晓要导入其他节点的数据。对应的节点1就会通过importing_slots_from数组标记自己将导入这个slot的数据,而节点2也会通过migrating_slots_to数组标记自己要将数据导出给其他节点的slot:
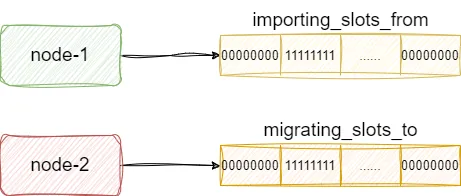
对此我们给出clusterCommand的执行流程,可以看到该函数解析出migrating或者importing关键字时就会将对的migrating_slots_to或者importing_slots_from数组对应slot位置的索引位置设置为当前上述命令传入的node id:
void clusterCommand(redisClient *c) {
//......
if (!strcasecmp(c->argv[3]->ptr,"migrating") && c->argc == 5) {//处理迁出的逻辑
//看看自己是否有迁出的slot,没有则报错
if (server.cluster->slots[slot] != myself) {
addReplyErrorFormat(c,"I'm not the owner of hash slot %u",slot);
return;
}
//查看自己是否知晓这个node id,如果没有则报错
if ((n = clusterLookupNode(c->argv[4]->ptr)) == NULL) {
addReplyErrorFormat(c,"I don't know about node %s",
(char*)c->argv[4]->ptr);
return;
}
//标记迁出到slot为传入的node
server.cluster->migrating_slots_to[slot] = n;
} else if (!strcasecmp(c->argv[3]->ptr,"importing") && c->argc == 5) {//处理迁入的逻辑
//查看迁入的slot是否已经配置,如果有则报错
if (server.cluster->slots[slot] == myself) {
addReplyErrorFormat(c,
"I'm already the owner of hash slot %u",slot);
return;
}
//查看自己是否知晓要迁入数据的node的信息,如果不知道则报错
if ((n = clusterLookupNode(c->argv[4]->ptr)) == NULL) {
addReplyErrorFormat(c,"I don't know about node %s",
(char*)c->argv[3]->ptr);
return;
}
//标记迁入slot位置为传入的nodeid
server.cluster->importing_slots_from[slot] = n;
} //......
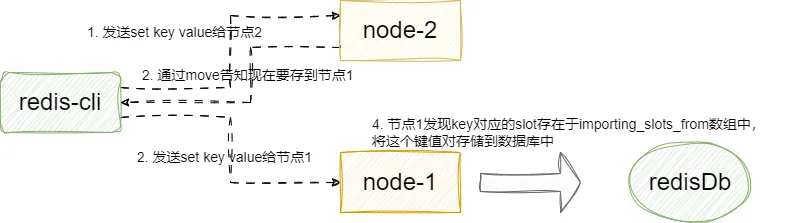
}后续的我们假设还是将set key value请求发送到节点2,因为上述命令的原因,节点会返回move/ask告知客户端这个键值对现在要存到节点1上。对应节点1收到这个key请求时,通过key计算得slot正是自己,它就会将这个键值对存储到自己的数据库中:
这里我们以节点1的角度查看这个问题,当客户端收到move指令后,继续向节点1发送指令,节点1通过收到指令调用processCommand,其内部调用getNodeByQuery获取当前key对应的slot,发现是自己则直接存储数据到当前节点的内存数据库中:
int processCommand(redisClient *c) {
//......
//如果开启了集群模式,且发送者不是master且参数带key则进入逻辑
if (server.cluster_enabled &&
!(c->flags & REDIS_MASTER) &&
!(c->flags & REDIS_LUA_CLIENT &&
server.lua_caller->flags & REDIS_MASTER) &&
!(c->cmd->getkeys_proc == NULL && c->cmd->firstkey == 0))
{
int hashslot;
if (server.cluster->state != REDIS_CLUSTER_OK) {
//......
} else {
int error_code;
//查找键值对对应的slot和这个slot负责的节点
clusterNode *n = getNodeByQuery(c,c->cmd,c->argv,c->argc,&hashslot,&error_code);
//如果为空且或者非自己,则转交出去给别人处理
if (n == NULL || n != server.cluster->myself) {
flagTransaction(c);
clusterRedirectClient(c,n,hashslot,error_code);
return REDIS_OK;
}
}
}
//......
//将键值对存储到当前数据库中
}我们以节点的视角再次直接步入getNodeByQuery查看这段逻辑,可以看到其内部会基于key计算slot然后将得到对应的node,如果发现这个node是自己且属于importing_slots_from,即说明是客户端通过move或者ask请求找到自己的,则进行进一步是否是多条指令执行且存在key找不到存储位置的情况,若存在则返回空,反之都是直接返回当前节点信息,即node2的新数据直接迁移过来:
clusterNode *getNodeByQuery(redisClient *c, struct redisCommand *cmd, robj **argv, int argc, int *hashslot, int *error_code) {
//......
//遍历命令
for (i = 0; i < ms->count; i++) {
//.....
//获取指令、参数个数、参数
mcmd = ms->commands[i].cmd;
margc = ms->commands[i].argc;
margv = ms->commands[i].argv;
//解析出key以及个数
keyindex = getKeysFromCommand(mcmd,margv,margc,&numkeys);
for (j = 0; j < numkeys; j++) {
//拿到key
robj *thiskey = margv[keyindex[j]];
//计算slot
int thisslot = keyHashSlot((char*)thiskey->ptr,
sdslen(thiskey->ptr));
//.....
//如果就是当前节点正在做迁出或者迁入,则migrating_slot/importing_slot设置为1
if (n == myself &&
server.cluster->migrating_slots_to[slot] != NULL)
{
migrating_slot = 1;
} else if (server.cluster->importing_slots_from[slot] != NULL) {
importing_slot = 1;
}
} else {
//.....
//.....
}
//.....
}
//如果设置了导入标识为1且标识为asking则步入这段逻辑,
if (importing_slot &&
(c->flags & REDIS_ASKING || cmd->flags & REDIS_CMD_ASKING))
{ //当前指令有多个key且存在未命中的则返回空,反之返回自己
if (multiple_keys && missing_keys) {
if (error_code) *error_code = REDIS_CLUSTER_REDIR_UNSTABLE;
return NULL;
} else {
return myself;
}
}
//.....
//返回节点信息以本示例来说就是返回当前节点信息
return n;
}完成节点迁移
上述操作仅仅针对新节点的迁移,对于旧的节点我们就需要通过节点2键入CLUSTER GETKEYSINSLOT slot count要迁移的旧的key的slot,然后通过MIGRATE host port key dbid timeout [COPY | REPLACE]将数据迁移到节点1上。 这里我们补充一下MIGRATE 中copy和replace的区别,前者是遇到重复直接报错,后者是迁移时直接覆盖。 最终这条指令回基于要迁移的key而生成一条RESTORE-ASKING key ttl serialized-value [REPLACE] [ABSTTL] [IDLETIME seconds] [FREQ frequency]指令发送给导入的节点,以本文例子来说就是节点1:
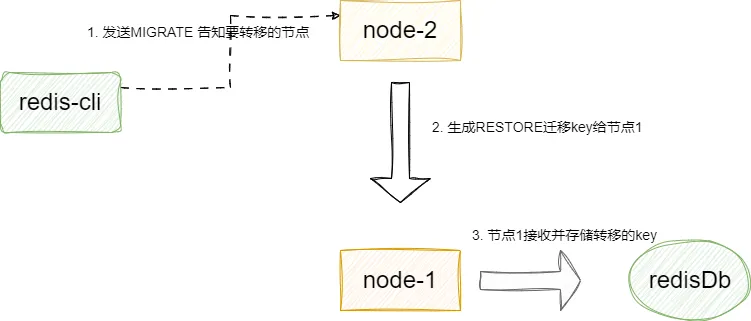
这里我们给出MIGRATE 指令对应的处理函数migrateCommand,逻辑和我上文说的差不多,基于指令解析出replace或者copy等信息,然后用argv[3]即我们的key得出这个键值对的信息生成RESTORE指令将键值对转存给节点1:
/* 命令 MIGRATE host port key dbid timeout [COPY | REPLACE] */
void migrateCommand(redisClient *c) {
//......
//解析拷贝和替代选项,前者重复会报错
for (j = 6; j < c->argc; j++) {
if (!strcasecmp(c->argv[j]->ptr,"copy")) {
copy = 1;
} else if (!strcasecmp(c->argv[j]->ptr,"replace")) {
replace = 1;
} else {
addReply(c,shared.syntaxerr);
return;
}
}
//......
//查看要迁移的key是否存在吗,如果不存则直接报错返回
if ((o = lookupKeyRead(c->db,c->argv[3])) == NULL) {
addReplySds(c,sdsnew("+NOKEY\r\n"));
return;
}
/* Connect */
//建立socket连接
cs = migrateGetSocket(c,c->argv[1],c->argv[2],timeout);
//......
//cmd初始化一个buf缓冲区
rioInitWithBuffer(&cmd,sdsempty());
/* Send the SELECT command if the current DB is not already selected. */
//如果尚未选择当前DB,则发送SELECT命令。
int select = cs->last_dbid != dbid; /* Should we emit SELECT? */
if (select) {
redisAssertWithInfo(c,NULL,rioWriteBulkCount(&cmd,'*',2));
redisAssertWithInfo(c,NULL,rioWriteBulkString(&cmd,"SELECT",6));
redisAssertWithInfo(c,NULL,rioWriteBulkLongLong(&cmd,dbid));
}
/* Create RESTORE payload and generate the protocol to call the command. */
//获取key的过期时效
expireat = getExpire(c->db,c->argv[3]);
if (expireat != -1) {
ttl = expireat-mstime();
if (ttl < 1) ttl = 1;
}
//集群用RESTORE-ASKING发送key给目标
if (server.cluster_enabled)
redisAssertWithInfo(c,NULL,
rioWriteBulkString(&cmd,"RESTORE-ASKING",14));
else
redisAssertWithInfo(c,NULL,rioWriteBulkString(&cmd,"RESTORE",7));
//填充key和value ttl等
redisAssertWithInfo(c,NULL,sdsEncodedObject(c->argv[3]));
redisAssertWithInfo(c,NULL,rioWriteBulkString(&cmd,c->argv[3]->ptr,
sdslen(c->argv[3]->ptr)));
redisAssertWithInfo(c,NULL,rioWriteBulkLongLong(&cmd,ttl));
//......
//迁移指令字符串写入缓冲区
redisAssertWithInfo(c,NULL,rioWriteBulkString(&cmd,payload.io.buffer.ptr,
sdslen(payload.io.buffer.ptr)));
//......
//如果是replace发出 REPLACE
if (replace)
redisAssertWithInfo(c,NULL,rioWriteBulkString(&cmd,"REPLACE",7));
//......
}最后调整
最后我们只需在节点1和2都执行CLUSTER SETSLOT <SLOT> NODE <NODE ID> 完成slot指派,这指令最终就会走到clusterCommand中,节点1和节点2格子的处理逻辑为:
- 节点2看看迁移的key是否不存则且migrating_slots_to数据不为空,若符合要求说明迁移完成但状态未修改,直接将migrating_slots_to置空完成指派最后调整。
- 节点1查看节点id是否是自己且importing_slots_from是否有数据,若有则说明节点导入完成,直接将importing_slots_from置空。
void clusterCommand(redisClient *c) {
//......
else if (!strcasecmp(c->argv[1]->ptr,"setslot") && c->argc >= 4) {//处理setslot指令
//......
else if (!strcasecmp(c->argv[3]->ptr,"node") && c->argc == 5) {
/* CLUSTER SETSLOT <SLOT> NODE <NODE ID> 标记最终迁移的节点 */
clusterNode *n = clusterLookupNode(c->argv[4]->ptr);
//......
//如果发现对应的key为0,且migrating_slots_to不为空,则说明迁出完成但状态还未修改,节点2会将migrating_slots_to设置为空
if (countKeysInSlot(slot) == 0 &&
server.cluster->migrating_slots_to[slot])
server.cluster->migrating_slots_to[slot] = NULL;
//如果是节点1则会看指令的nodeid是否是自己且importing_slots_from是否有数据,若有则说明导入成功直接将importing_slots_from设置为空
if (n == myself &&
server.cluster->importing_slots_from[slot])
{
//......
server.cluster->importing_slots_from[slot] = NULL;
}
}
//......
}
























