













强化学习(RL)对大模型复杂推理能力提升有关键作用,但其复杂的计算流程对训练和部署也带来了巨大挑战。近日,字节跳动豆包大模型团队与香港大学联合提出 HybridFlow。这是一个灵活高效的 RL/RLHF 框架,可显著提升训练吞吐量,降低开发和维护复杂度。实验结果表明,HybridFlow 在各种模型规模和 RL 算法下,训练吞吐量相比其他框架提升了 1.5 倍至 20 倍。
在大模型后训练(Post-Training)阶段引入 RL 方法,已成为提升模型质量和对齐人类偏好的重要手段。然而,随着模型规模的不断扩大,RL 算法在大模型训练中面临着灵活性和性能的双重挑战。传统的 RL/RLHF 系统在灵活性和效率方面存在不足,难以适应不断涌现的新算法需求,无法充分发挥大模型潜力。
据豆包大模型团队介绍,HybridFlow 采用混合编程模型,将单控制器的灵活性与多控制器的高效性相结合,解耦了控制流和计算流。基于 Ray 的分布式编程、动态计算图、异构调度能力,通过封装单模型的分布式计算、统一模型间的数据切分,以及支持异步 RL 控制流,HybridFlow 能够高效地实现和执行各种 RL 算法,复用计算模块和支持不同的模型部署方式,大大提升了系统的灵活性和开发效率。
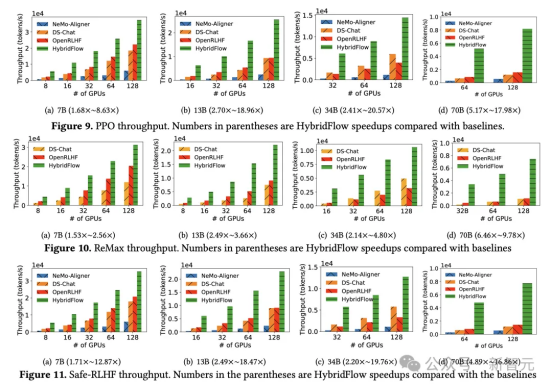
实验结果显示,无论 PPO 、ReMax 还是 Safe-RLHF 算法,HybridFlow 在所有模型规模下平均训练吞吐量均大幅领先于其他框架,提升幅度在 1.5 倍至 20 倍之间。随着 GPU 集群规模扩大,HybridFlow 吞吐量也获得良好扩展。这得益于其灵活的模型部署,充分利用硬件资源,实现高效并行计算。同时,HybridFlow 能够支持多种分布式并行框架(Megatron-LM 、FSDP 、vLLM ),满足不同模型规模的计算需求。
随着 o1 模型诞生,大模型 Reasoning 能力和 RL 愈发受到业界关注。豆包大模型团队表示,将继续围绕相关场景进行探索和实验。目前,HybridFlow 研究论文已入选学术顶会 EuroSys 2025,代码也已对外开源。
HybridFlow开源链接:https://github.com/volcengine/veRL




























