探索更高效的模型架构, MoE是最具代表性的方向之一。
MoE架构的主要优势是利用稀疏激活的性质,将大模型拆解成若干功能模块,每次计算仅激活其中一小部分,而保持其余模块不被使用,从而大大降低了模型的计算与学习成本,能够在同等计算量的情况下产生性能优势。
然而,此前像MoE等利用稀疏激活性质的研究工作,都认为大模型需要在预训练阶段就额外引入模块化结构约束。
如今,来自清华的一项最新研究打破了以上思维定式,并将MoE架构进行了革新。
具体而言,研究人员受启发于人脑高效的稀疏模块化架构,在论文《Configurable Foundation Models: Building LLMs from a Modular Perspective》中提出了一种类脑高效稀疏模块化架构:Configurable Foundation Model。
该架构将大模型的模块拆分为预训练阶段产生的涌现模块(Emergent Brick)与后训练阶段产生的定制模块(Customized Brick),然后通过模块的检索、组合、更新与增长可以高效地实现复杂功能配置与组合,因此,将这一类模块化模型架构命名为“Configurable Foundation Model”——可配置的基础模型。
从此,训练大模型无需在预训练阶段就像MoE架构一样引入模块化结构约束,而是可以在预训练阶段产生涌现模块之后,像搭积木一样来构建大模型!
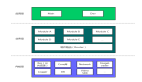
如下图所示,大模型看做是一个大的积木,将其按照功能拆分成一个一个小模块之后,给定一个指令时,我们仅需选用部分相关的模块组成子模型即可完成任务。
 图片
图片
该研究揭示了「模块化」是大模型本身自带的性质,所有 Transformer-based 大模型的预训练和后训练等工作都可以通过模块化的视角进行解构,其中MoE、Delta tuning只是Configurable Foundation Model包含的一种路线。
Configurable Foundation Model架构具有高效性、可复用性、可溯源性、可扩展性,并且更适合分布式计算,能够更好地契合未来大模型在端侧部署、在广泛的场景中使用、在新环境中进化的未来趋势。
 图片
图片
论文链接:https://arxiv.org/pdf/2409.02877
论文单位:清华大学、加州大学圣地亚哥分校、卡耐基梅隆大学、面壁智能、中国人民大学、普林斯顿大学、新加坡国立大学、斯坦福大学和加州大学洛杉矶分校。
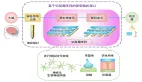
可配置的大模型 —— 涌现模块与定制模块
研究人员描述了涌现模块和定制模块两种模块类型及其构建方式。
1. 涌现模块
随机初始化的模型参数,在预训练过程中,模型神经元将会自发地产生功能分化的现象,进而组成了大模型的功能分区。在推理阶段,只有与当前输入内容相关的功能分区会被激活,并作用于模型的输出结果。
 图片
图片
在该机制作用下,许多研究致力于发掘大模型神经元的稀疏激活性质与功能定位:
稀疏激活:
最早利用稀疏激活性质的模型架构为稀疏混合专家模型,它通过预定义的模块化结构,强制每个词仅能使用部分专家进行计算。
进一步地,在稠密训练的模型中,神经元同样存在稀疏激活现象:在处理每个词语过程中,大量神经元激活值的绝对值很低,无法对输出产生有效贡献。稀疏激活的性质使得我们可以训练高效的参数选择器,在推理时动态选择参数进行计算,以降低计算开销。
功能定位:
与人脑类似,大模型神经元在预训练后产生了功能分化,各自仅负责部分功能。目前已经被广泛发现的功能神经元包括:
- 知识神经元,用于存储世界三元组知识;
- 技能神经元,用于辅助模型完成特定任务,例如情感分类;
- 语言神经元,用于识别特定的语法特征或处理特定语言。
这些功能神经元的发现进一步佐证了大模型具备与人脑一样进行高效稀疏化推理的潜力。
2. 定制模块(插件)
预训练之后,我们往往需要对模型进行后训练,从而将模型与人类需求对齐,并增强包括领域能力和任务能力在内的模型能力。最近的研究表明,后训练过程中参数变化本质上是低秩的,这意味着该过程只训练少部分参数。受这些发现的启发,多样化的定制模块(插件)被提出。
其中,最广为人知的是通过少参数微调形成的任务模块,保持模型主体参数不变,仅微调少量的任务相关参数。进一步地,许多研究发现,小规模的外部插件,不仅可以赋予大模型任务特定的能力,还可以为它们补充更多额外的知识和功能,例如用于世界知识注入的知识插件、用于多模态组合的模态插件、用于长文本处理的记忆插件,以及用于推理加速的压缩插件等。
因此,该论文研究者认为,后训练的本质是定制模块的训练,这些模块可以充分补充和激发大模型的知识和能力。
 图片
图片
由涌现模块与定制模块构成的可配置的大模型相比于传统的稠密模型拥有五大优势:
- 高效性:我们依旧可以使用数百亿、数千亿的参数来存储海量的世界知识,但每次计算过程,仅有部分参数参与计算,保证了模型效果的同时,大幅降低计算开销。
- 可复用性:不同数据、不同任务训练得到的模块,可以在同一个序列中通过模块路由器/选择器进行组合,实现能力的迁移与复用。
- 可溯源性:模块化架构改变了传统黑盒大模型的使用方法,在推理阶段,我们可以观察到不同功能模块的激活调用情况,从而更好地观测模型产生错误行为的原因。
- 可扩展性:模块化架构使得我们可以通过模块的更新与构建实现对模型的更新、能力增强,而无需对所有模型参数进行训练。这使得模型可以高效地不断学习新知识与新能力。
- 分布式计算:功能模块的拆分使得我们在部署模型时,可以天然地将不同模块置于不同机器上进行计算。例如,将包含有个人隐私数据的模块部署在端侧设备中,而将大部分通用模块署在云端服务器,实现高效、安全的端云协同。
在定义了可配置的大模型架构之后,研究人员提出了四种主要的模块操作,通过这些操作,可以让不同模块进行灵活地配合,实现复杂能力。
- 检索与路由:根据需求,选择相关的功能模块参与计算;
- 组合:将多个单一能力的模块进行组合,实现复合能力;
- 更新:根据外部世界的需求,对特定的知识与功能模块进行更改;
- 增长:构建新的功能模块,对模型进行能力增强的同时,使其能够与其他模块进行高效合作。
这些模块化操作,使得我们能够更方便地对模型能力进行高效配置。
大模型的涌现模块分析
进一步地,为了验证大模型模块化观点,作者对现在被广泛使用的通用生成式大模型(Llama-3-8B-Instruct,Mistral-7B-Instruct-v0.3)进行了涌现模块分析:
- 稀疏激活特性:通用的生成式大模型是否存在稀疏激活现象,即每个词仅要求少量的神经元参与计算;
- 功能分化特性:对于不同的能力,是否存在特定的神经元来负责;
- 功能分区特性:不同的能力对应的神经元之间,是否存在重叠。
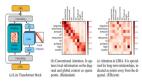
(1)针对稀疏激活特性,作者采用了神经元激活值、神经元输出向量的模长两个指标,作为神经元是否激活的评价指标。并且,作者还开展了扰动实验,探究对每个词语将其中激活指标最低的神经元给遮盖掉之后,模型性能是否会受到影响。
 图片
图片
结果表明,对于神经元激活值和输出向量模长两个指标而言,神经元激活指标均存在长尾分布特点,即绝大多数神经元的激活指标均较低。同时,将每个词激活指标最低的70%-80%的神经元进行遮盖,模型性能仅会受到非常微弱的影响。这充分表明了,通用生成式大模型存在稀疏激活特性,每次计算过程中,大量神经元的计算对输出并不会造成太多的影响。
(2)针对功能分化特性:作者选取了7种大模型能力,包括代码、伦理、知识、语言、数学、翻译和写作能力,并且计算了神经元激活与输入指令所需能力之间的相关性。下图结果表明,每种能力都有非常少量的神经元与其高度相关,而在需要改能力的指令中,大部分与该能力无关的神经元的激活特性与随机激活的神经元相似。
 图片
图片
进一步地,作者尝试将每种能力特定的神经元进行剪枝,观察这些神经元对其他能力的影响。
下图结果表明,对大部分能力而言,剪除与其最相关的神经元,对其他能力影响甚微,表明了这些神经元的特异性。
比如,对于Llama-3-8B-Instruct而言,剪除代码神经元之后,性能下降(PPL上涨了) 112%,而对其他能力的性能影响均不超过8%。
此外,Llama-3-8B-Instruct中的知识相关神经元、Mistral-7B-Instruct-v0.3中翻译相关神经元对每一种能力都非常关键,这可能是常驻神经元的影响,识别特定能力神经元时算法,将常驻神经元识别出来,影响了模型通用能力。这也进一步需要研究者针对神经元能力探索开展更多的后续研究。
 图片
图片
(3)功能分区特性:作者对不同能力神经元开展了分布上的分析,结果发现,不同能力神经元之间重叠度很低。这表明,我们可以进一步将神经元进行聚类分隔,形成功能分区。

大模型的定制模块(插件)分析
Configurable Foundation Model由预训练阶段的涌现模块与后训练阶段的定制化模块构成。前文已经对大模型涌现模块的相关性质进行了分析。同样,作者团队已经在插件构建层面,取得了很多有益的尝试:
- 知识插件:为实现高效地长时知识更新,我们提出面向大模型的即插即拔参数化知识插件:把无结构文本知识参数化为大模型的模块,在模型需要相关知识时,将模块插入模型中实现知识注入。该方法能够有效地为模型注入知识,降低知识驱动任务中的文本编码开销,节省69%的计算成本。
论文链接:https://arxiv.org/pdf/2305.17691 https://arxiv.org/pdf/2305.17660
- 长文本记忆插件:为实现高效地短时知识记忆,我们提出面向大模型的免训练上下文记忆模块:将远距离上下文存储到额外的记忆单元中,并采用一种高效的机制来查找与当前文本相关的记忆单元进行注意力计算。实验结果表明,我们提出的InfLLM能够有效地扩展Mistral、LLaMA的上下文处理窗口,并在1024K上下文的passkey检索任务中实现100%召回。
论文链接:https://arxiv.org/pdf/2402.04617
- 加速插件:阅读知觉广度是影响人阅读速度的重要因素,人单次注视可以阅读并处理多个字词,然而大模型却始终只能够逐字阅读并处理。受启发于此,该研究提出了一种文本推理加速模块。该加速模块在大模型内部对文本序列进行长度压缩,使得模型单次阅读可以处理多个词语,从而实现效率的提升。该加速模块不改变大模型原本参数,通过部署一个模型+多个不同速率的加速模块,可以实现速度与效果的动态平衡。
论文链接:https://arxiv.org/pdf/2310.15724
总结和更多研究
在本篇文章中,作者提出了一种高效模块化架构 —— 由涌现模块与定制模块组成的可配置大模型。该架构强调将大模型根据功能拆解为若干模块,通过模块的检索、组合、更新、增长实现复杂能力的组合。该架构具有高效性、可复用性、可溯源性、可扩展性,并且更适合分布式计算,能够更好地契合未来大模型在端侧部署、在广泛的场景中使用、在新环境中进化的未来趋势。
清华大学自然语言处理实验室已经在大模型稀疏模块化架构方面开展了大量的研究工作,附上相关论文列表,供大家参考:
- 参数模块化聚类
Moefication: Transformer feed-forward layers are mixtures of experts (https://arxiv.org/pdf/2110.01786)
- 大模型稀疏模块性增强:
ProSparse: Introducing and Enhancing Intrinsic Activation Sparsity within Large Language Models (https://arxiv.org/pdf/2402.13516)
ReLU^2 Wins: Discovering Efficient Activation Functions for Sparse LLMs (https://arxiv.org/pdf/2402.03804)
- 大模型模块化性质分析:
Emergent Modularity in Pre-trained Transformers (https://arxiv.org/pdf/2305.18390)
- 稀疏模块化预训练:
Exploring the Benefit of Activation Sparsity in Pre-training (https://arxiv.org/pdf/2410.03440?)
- 神经元功能定位:
Finding Skill Neurons in Pre-trained Transformer-based Language Model(https://arxiv.org/pdf/2211.07349)
- 大模型知识插件:
Plug-and-play document modules for pre-trained models (https://arxiv.org/pdf/2305.17660)
Plug-and-play knowledge injection for pre-trained language models (https://arxiv.org/pdf/2305.17691)
- 大模型记忆插件:
Infllm: Training-free long-context extrapolation for llms with an efficient context memory (https://arxiv.org/pdf/2402.04617)
- 大模型加速插件:
Variator: Accelerating Pre-trained Models with Plug-and-Play Compression Modules (https://arxiv.org/pdf/2310.15724)
- 大模型任务插件:
Delta tuning: A comprehensive study of parameter efficient methods for pre-trained language models (https://arxiv.org/pdf/2203.06904)