当你打开微博或一个新闻网站时,眼前会呈现出丰富的媒体文件:图片、文本、音频、视频等应有尽有。有时,一个页面甚至由成百上千个文件组合而成。那么,这些文件究竟存放在哪里呢?
通常来说,对于小于 1KB 的少量文本数据,我们会将其存储在数据库中。然而,对于较大的文本或多媒体文件(例如 MP4、TS、MP3、JPG、JS、CSS 等),我们则会存放在硬盘上。这类文件的管理并不复杂,但当文件数量达到数百万时,单靠硬盘管理就显得吃力了。
在这种情况下,当用户请求服务器时,几十台服务器需要在上百块硬盘中定位文件的具体存储位置。此外,定期备份、统计访问记录等维护工作也随之增加,大大增加了研发负担。
而对象存储技术的出现帮助我们屏蔽了这些复杂细节,显著提升了研发效率。本节课,我们将探讨存储技术的演变过程,帮助你更深入地理解服务器存储和对象存储的原理与实践。
分布式文件存储服务
在介绍对象存储之前,我们先来了解支撑它的基础技术——分布式文件存储服务。这类服务是互联网媒体资源的数据存储基础。我们先具体分析一下,分布式文件存储具备哪些功能,以及数据库在管理文件时需要完成的任务。
通常情况下,数据库中保存的只是文件路径。于是,在文件迁移、归档和备份副本时,数据库就需要同步更新这些路径记录。当文件数量达到百万级别,为了能高效响应文件查找请求,系统需要为文件索引信息进行分库分表。此外,还需提供文件检索、管理、访问统计,以及根据文件热度调整存储位置等功能。
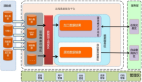
那么,这些文件索引和存储究竟是如何协同工作的呢?请看下图:
 图片
图片
从上图中可以看出,光是管理文件索引这一任务,研发团队已经面临极大的压力,更不用说涉及到文件存储、传输和副本备份的分布式存储服务,这些工作更加复杂。
在未使用分布式存储前,静态文件服务通常依赖于 Nginx 和 NFS 挂载 NAS 的方式。然而,这种方法存在明显缺陷:文件只有一份,且需要人工定期备份。为了确保数据完整性,提高文件服务的可用性,并减少研发团队的重复劳动,业界普遍选择使用分布式存储系统来统一管理文件的分发和存储。
通过分布式存储,系统能够自动实现动态扩容、负载均衡、文件分片与合并、文件归档以及冷热点文件管理等服务。这使得管理大量文件的过程变得更加高效和便捷。
为了帮助你理解常见的分布式存储服务的工作原理,我们将以 FastDFS 分布式存储为例进行分析,请看下图:
 图片
图片
其实,分布式文件存储的方案也并不是十全十美的。就拿 FastDFS 来说,它有很多强制规范,比如新保存文件的访问路径是由分布式存储服务生成的,研发需要维护文件和实际存储的映射。这样每次获取要展示的图片时,都需要查找数据库,或者为前端提供一个没有规律的 hash 路径,这样一来,如果文件丢失的话前端都不知道这个文件到底是什么。FastDFS 生成的文件名很难懂,演示路径如下所示:
# 在网上找的FastDFS生成的演示路径
/group1/M00/03/AF/wKi0d1QGA0qANZk5AABawNvHeF0411.png相信你一定也发现了,这个地址很长很难懂,这让我们管理文件的时候很不方便,因为我们习惯通过路径层级归类管理各种图片素材信息。如果这个路径是 /active/img/banner1.jpg,相对就会更好管理。虽然我只是举了一种分布式存储系统,但其他分布式存储系统也会有这样那样的小问题。
这里我想提醒你注意的是,即便用了分布式存储服务,我们的运维和研发工作也不轻松。为什么这么说呢?根据我的实践经验,我们还需要关注以下五个方面的问题:
- 磁盘监控:
监控磁盘的寿命、容量、inode 剩余。
进行故障监控警告及日常维护。
- 文件管理:
使用分布式存储控制器对文件做定期、冷热转换、定期清理以及文件归档等工作。
确保服务稳定:
关注分布式存储副本同步状态及服务带宽。
如果服务流量过大,运维和研发还需要处理好热点访问文件缓存的问题。
业务定制化:
一些稍微个性点的需求,比如在文件中附加业务类型的标签、增加自动 TTL 清理,现有的分布式存储服务可能无法直接支持,还需要我们阅读相关源码,进一步改进代码才能实现功能。
硬件更新:
服务器用的硬盘寿命普遍不长,特别是用于存储服务的硬盘,需要定期更换(比如三年一换)。
对象存储
自从采用分布式存储后,回想过去的经历,我意识到树形磁盘存储结构给研发带来了很多额外的工作。比如,在数百台服务器和磁盘上提供相对路径和绝对路径的挂载服务,需要具备文件检索、遍历功能,并设置文件的访问权限。这些管理功能并非我们对外业务所需的高频使用功能,这种设计导致研发投入过高,超出了本应关注的范围。
而使用对象存储服务后,这些问题得到了显著改善。对象存储优雅地屏蔽了底层实现细节,将业务和运维工作隔离,使路径变得简单明了,让研发团队可以更专注于业务发展。
对象存储的优势主要体现在以下三个方面:
首先,从文件索引的角度来看,对象存储弱化了树形目录结构,甚至可以说是省略了。尽管如此,树形目录结构仍然可以保留。当需要进行运维操作时,可以通过前缀检索对 Key 进行查找,从而实现目录管理。这种方式使用方便,无需担心数据量大导致索引查找缓慢的问题。值得强调的是,对象存储并不是按照指定路径进行存储,实际上,文件路径仅是一个 Key。当查询文件对象时,实际上是进行了一次哈希查询,这比在数据库中进行字符串前缀匹配查询要快得多。此外,由于不需要维护整体树索引,键值(KV)方式在查询和存储上都大幅提升了效率,同时更容易进行维护。
其次,读写管理方式也从原先通过磁盘文件管理,转变为通过 API 管理文件对象。这种简化后的接口方式使得数据读写变得更加灵活和方便,无需过多考虑磁盘相关的知识。
最后,对象存储还提供了文件的索引管理与映射,增加了数据和媒体文件的管理可能性。以往,我们的文件主要是图片、音频和视频,这些文件通常在业务系统中是独立存在的。而结合对象存储后,我们可以将一些数据作为小文件来管理。然而,这也带来了大量小文件的管理挑战。这些小文件往往很零碎,需要更多的管理策略和工具。接下来,我们将探讨在对象存储的思路下,如何有效管理小文件。
对象存储如何管理小文件
之前曾提到过,在对象存储当中,实际的存储路径已经转变为通过 hash 方式来进行存储了。
对此,我们能够借鉴类似 RESTful 的思路去规划设计我们的对象存储路径,示例如下:
- “user\info\9527.json”,该路径下保存的是用户的公共信息。
- “user\info\head\9527.jpg”,这里存放的是与之对应的用户头像。
- “product\detail\4527.json”,通过此路径可直接获取商品信息。
从上述设计能够看出,如此一来,我们无需在每次发起请求时都去访问数据库,便能够获取到特定对象的相关信息。前端只需简单地对路径进行拼接操作,就可以拿到所有所需的文件。采用这样的方式,能够帮助我们大幅削减缓存的维护成本。
也许看到这里,你心里会存在疑问:既然这个技巧这么好用,那为什么在此之前它没有得到广泛普及呢?
这是因为在以往的实现过程中,请求所访问的路径就是文件实际的物理存储路径。而对于 Linux 系统而言,在同一个目录下是无法存放过多文件的,要是存放的文件数量过多,就会导致管理起来极为困难。
就拿上面所举的例子来说,如果我们拥有 300 万个用户,将这 300 万个头像文件全部放置在同一个目录下,那么即便是执行一个简单的 ls 命令,都有可能致使服务器卡顿长达十分钟之久。
为了避免出现类似这样的问题,很多服务器在存储这些小文件的时候,会先对文件名进行 hash 计算,然后取 hash 结果的最后四位作为双层子目录名,通过这种方式来确保在一个目录下不会存在过多的文件。
然而,这样做就需要进行 hash 计算,这会使得前端在使用时极为不方便,而且我们在平时对磁盘数据进行查找、管理等操作时,也会感觉十分痛苦,所以这种方式遭到了很多人的排斥。
不过,即便切换到了分布式存储服务,小文件存储方面的问题依旧会给我们带来困扰。因为在进行副本同步以及存储操作时,都是以文件作为基本单位来开展的。倘若文件很小,每秒能够上传上千个文件,那么在进行副本同步时,就会由于存在大量的分配调度请求,进而出现延迟现象,这样一来,要对副本同步的流量进行管理也就变得十分困难了。
针对上述这些问题,对象存储和分布式存储服务针对这方面做出了优化,不再将小文件独立地进行保存,而是采用文件块的方式对多个文件进行压缩存储。
 图片
图片
比如把 100 个文件压缩存储到一个 10M 大小的文件块里统一管理,比直接管理文件简单很多。不过可以预见这样数据更新会麻烦,为此我们通常会在小文件更新数据时,直接新建一个文件来更新内容。定期整理数据的时候,才会把新老数据合并写到新的块里,清理掉老数据。这里顺便提示一句,大文件你也可以使用同样的方式,切成多个小文件块来管理,这样更方便。
对象存储如何管理大文本
在前面讨论了对象存储在管理小文件方面的优势后,接下来我们来看看对象存储如何管理大文本。这种管理方式可以抽象地概括为用对象存储取代缓存。
那么,什么情况下会有大文本的管理需求呢?比较典型的场景就是新闻资讯网站,尤其是资讯量特别丰富的那些网站,它们常常直接使用对象存储提供文本服务。这种设计的主要原因是,1KB 以上的大文本并不适合放在数据库或缓存中。接下来,我们通过后面的示意图进行分析。
首先,大文本通常具有较大的体积和不规则的访问模式,这使得将其存储在数据库中不仅增加了存储成本,还可能导致数据库性能下降。数据库的设计初衷是高效管理小规模、频繁更新的数据,而大文本的读写操作相对较少,因此将其存储在数据库中并不高效。
其次,缓存虽然能加速数据的访问,但它的内存资源有限。大量大文本的缓存会迅速消耗可用内存,导致缓存命中率降低,从而影响整体性能。因此,对于大文本的管理,直接使用对象存储会更加合适。
对象存储提供了高效、灵活的存储解决方案,能够处理大文本的存取需求,同时避免了数据库和缓存中的瓶颈。这使得在需要频繁更新和访问的大文本场景中,使用对象存储成为一种理想的选择。通过这种方式,我们可以更高效地管理和提供服务,同时确保系统的整体性能。
 图片
图片
如上图所示,左边展示了通过缓存提供数据查询服务的常见方式,而右边则展示了使用对象存储的方式。从结构上来看,对象存储在使用和维护上显得更为方便和简单。接下来,我们来估算一下成本。
假设我们的请求访问量为 1W QPS,那么对于 1KB 的数据缓存服务,带宽需求可以计算为:
为了留出一些余地,我们大概需要 100MB/s 的带宽。此外,还需要多台高性能服务器和一个大容量的缓存集群,以支撑我们的服务。这么一算,成本确实不低。对于资讯类网站这种读多写少的系统,如果无法降低维护成本,必然需要更多资源投入。
一种常见的解决方法是将资讯内容直接生成静态文件,虽然这样可以控制流量成本,但运维和开发的成本却会随之增加。有没有更好的方法呢?
相较之下,使用对象存储维护资源的具体页面则更为高效。具体过程如下:所有流量都会请求云厂商的对象存储服务,同时通过 CDN 实现缓存和加速。当 CDN 找不到待查文件时,会回源到对象存储进行查找;如果对象存储也未找到,则会回源到服务端生成。这种方式大大降低了网络流量压力,若配合版本控制功能,还能实现文件的历史版本回退,提高服务的可用性。
此外,值得补充的是,如果资讯内容存在阅读权限限制(例如仅限会员阅读),我们可以对特定对象设置权限,使得只有使用短期有效的 token 才能读取文件内容。这种做法不仅保护了内容的安全性,也提高了系统的灵活性。
文件的云中转
 图片
图片
除了通过服务端提供数据供用户下载之外,还有一种更为普遍的数据交换方式,即用户之间的文件传输。例如,当用户 A 想传递一个文件给用户 B,通常的做法是通过 TCP 连接两端客户端或通过服务端中转,但这种方式传输效率较低。而使用对象存储则能显著提升文件传输和交换的效率。
主要过程如下:文件传输服务为发送方生成一个临时授权 token,文件上传至对象存储后,接收方即可通过该地址和授权 token 进行多线程下载。当临时文件过期后,系统会自动清除文件。
实际上,这种方式不仅适用于用户之间的数据交换,业务系统也可利用对象存储实现跨机房的数据交换和数据备份。许多对象存储服务提供商的客户端 SDK 已内置了多线程分片上传下载和 GSLB(全局服务器负载均衡)就近 CDN 路线优化的上传加速功能,使用这些服务可大大提高数据传输速度。
此外,关于容灾,大部分对象存储服务商都提供容灾支持。我们可以为所有数据开启同城双活备份、全球加速、灾难调度以及主备切换等功能。这种完善的容灾机制确保数据在各种情况下都能安全、快速地访问。